 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigging Into Uncertainty-based Pseudo-label for Robust Stereo Matching
Jul 31, 2023
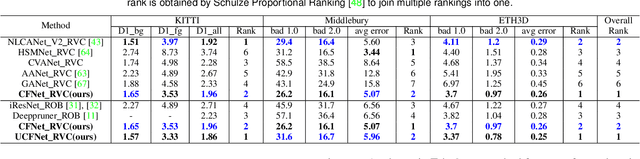

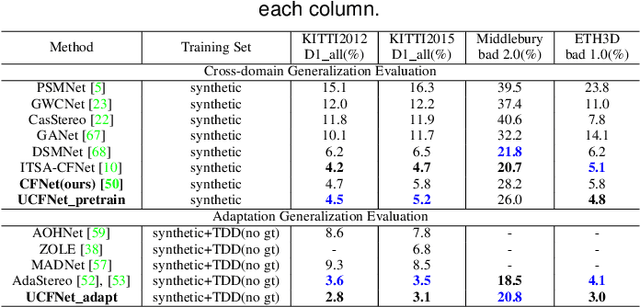
Due to the domain differences and unbalanced disparity distribution across multiple datasets, current stereo matching approaches are commonly limited to a specific dataset and generalize poorly to others. Such domain shift issue is usually addressed by substantial adaptation on costly target-domain ground-truth data, which cannot be easily obtained in practical settings. In this paper, we propose to dig into uncertainty estimation for robust stereo matching. Specifically, to balance the disparity distribution, we employ a pixel-level uncertainty estimation to adaptively adjust the next stage disparity searching space, in this way driving the network progressively prune out the space of unlikely correspondences. Then, to solve the limited ground truth data, an uncertainty-based pseudo-label is proposed to adapt the pre-trained model to the new domain, where pixel-level and area-level uncertainty estimation are proposed to filter out the high-uncertainty pixels of predicted disparity maps and generate sparse while reliable pseudo-labels to align the domain gap. Experimentally, our method shows strong cross-domain, adapt, and joint generalization and obtains \textbf{1st} place on the stereo task of Robust Vision Challenge 2020. Additionally, our uncertainty-based pseudo-labels can be extended to train monocular depth estimation networks in an unsupervised way and even achieves comparable performance with the supervised methods. The code will be available at https://github.com/gallenszl/UCFNet.
LiDAR-CS Dataset: LiDAR Point Cloud Dataset with Cross-Sensors for 3D Object Detection
Jan 29, 2023LiDAR devices are widely used in autonomous driving scenarios and researches on 3D point cloud achieve remarkable progress over the past years. However, deep learning-based methods heavily rely on the annotation data and often face the domain generalization problem. Unlike 2D images whose domains are usually related to the texture information, the feature extracted from the 3D point cloud is affected by the distribution of the points. Due to the lack of a 3D domain adaptation benchmark, the common practice is to train the model on one benchmark (e.g, Waymo) and evaluate it on another dataset (e.g. KITTI). However, in this setting, there are two types of domain gaps, the scenarios domain, and sensors domain, making the evaluation and analysis complicated and difficult. To handle this situation, we propose LiDAR Dataset with Cross-Sensors (LiDAR-CS Dataset), which contains large-scale annotated LiDAR point cloud under 6 groups of different sensors but with same corresponding scenarios, captured from hybrid realistic LiDAR simulator. As far as we know, LiDAR-CS Dataset is the first dataset focused on the sensor (e.g., the points distribution) domain gaps for 3D object detection in real traffic. Furthermore, we evaluate and analyze the performance with several baseline detectors on the LiDAR-CS benchmark and show its applications.
Multi-Sem Fusion: Multimodal Semantic Fusion for 3D Object Detection
Dec 10, 2022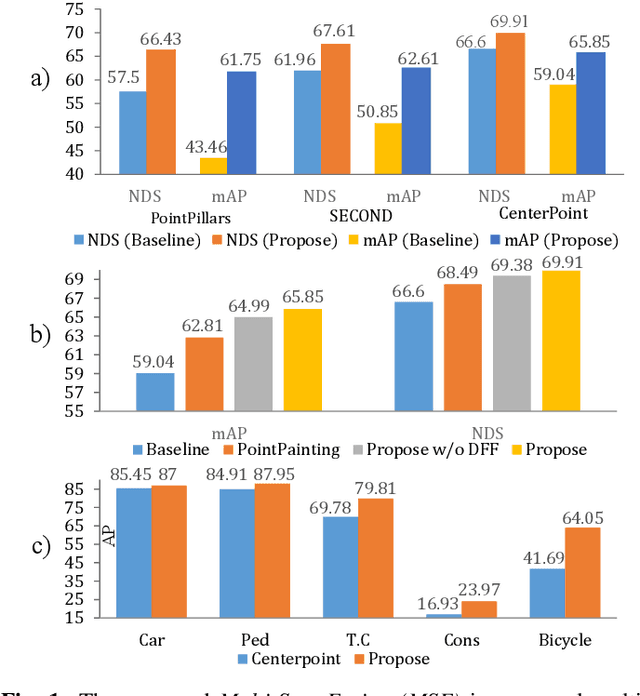
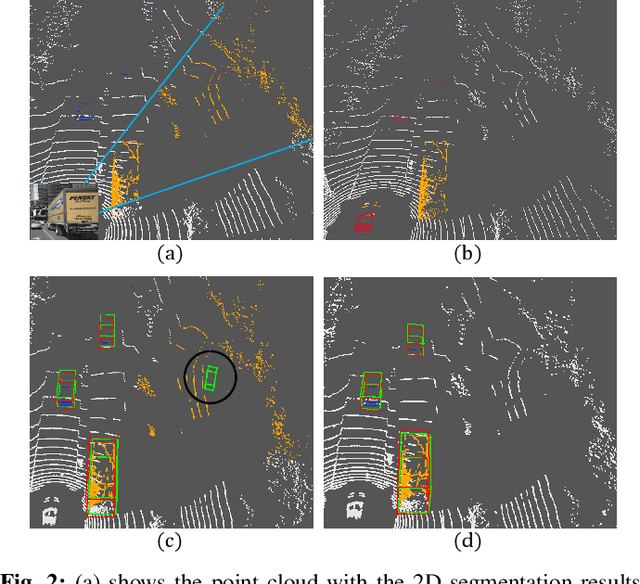


LiDAR-based 3D Object detectors have achieved impressive performances in many benchmarks, however, multisensors fusion-based techniques are promising to further improve the results. PointPainting, as a recently proposed framework, can add the semantic information from the 2D image into the 3D LiDAR point by the painting operation to boost the detection performance. However, due to the limited resolution of 2D feature maps, severe boundary-blurring effect happens during re-projection of 2D semantic segmentation into the 3D point clouds. To well handle this limitation, a general multimodal fusion framework MSF has been proposed to fuse the semantic information from both the 2D image and 3D points scene parsing results. Specifically, MSF includes three main modules. First, SOTA off-the-shelf 2D/3D semantic segmentation approaches are employed to generate the parsing results for 2D images and 3D point clouds. The 2D semantic information is further re-projected into the 3D point clouds with calibrated parameters. To handle the misalignment between the 2D and 3D parsing results, an AAF module is proposed to fuse them by learning an adaptive fusion score. Then the point cloud with the fused semantic label is sent to the following 3D object detectors. Furthermore, we propose a DFF module to aggregate deep features in different levels to boost the final detection performance. The effectiveness of the framework has been verified on two public large-scale 3D object detection benchmarks by comparing with different baselines. The experimental results show that the proposed fusion strategies can significantly improve the detection performance compared to the methods using only point clouds and the methods using only 2D semantic information. Most importantly, the proposed approach significantly outperforms other approaches and sets new SOTA results on the nuScenes testing benchmark.
Semi-supervised 3D Object Detection with Proficient Teachers
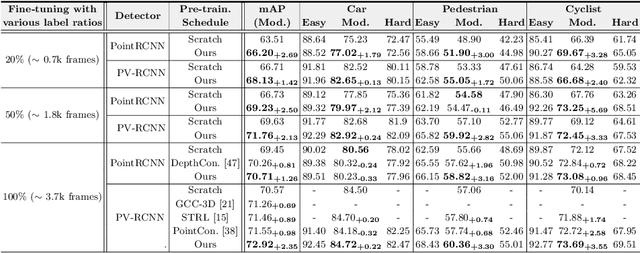
Jul 26, 2022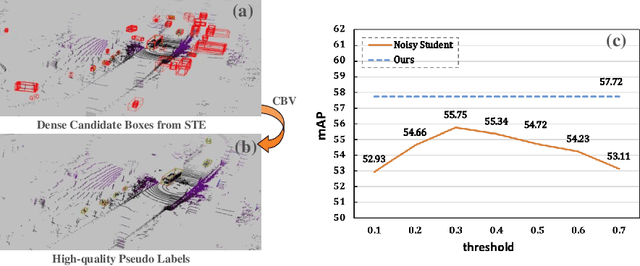

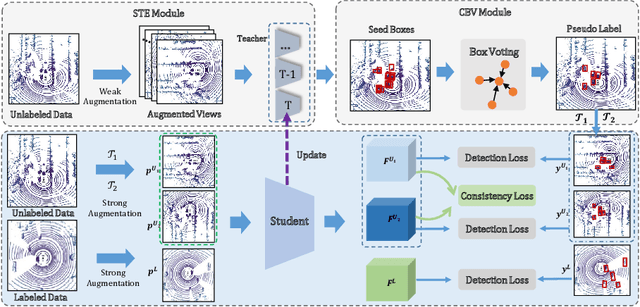
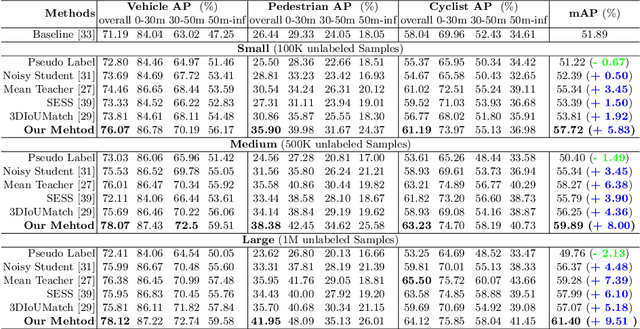
Dominated point cloud-based 3D object detectors in autonomous driving scenarios rely heavily on the huge amount of accurately labeled samples, however, 3D annotation in the point cloud is extremely tedious, expensive and time-consuming. To reduce the dependence on large supervision, semi-supervised learning (SSL) based approaches have been proposed. The Pseudo-Labeling methodology is commonly used for SSL frameworks, however, the low-quality predictions from the teacher model have seriously limited its performance. In this work, we propose a new Pseudo-Labeling framework for semi-supervised 3D object detection, by enhancing the teacher model to a proficient one with several necessary designs. First, to improve the recall of pseudo labels, a Spatialtemporal Ensemble (STE) module is proposed to generate sufficient seed boxes. Second, to improve the precision of recalled boxes, a Clusteringbased Box Voting (CBV) module is designed to get aggregated votes from the clustered seed boxes. This also eliminates the necessity of sophisticated thresholds to select pseudo labels. Furthermore, to reduce the negative influence of wrongly pseudo-labeled samples during the training, a soft supervision signal is proposed by considering Box-wise Contrastive Learning (BCL). The effectiveness of our model is verified on both ONCE and Waymo datasets. For example, on ONCE, our approach significantly improves the baseline by 9.51 mAP. Moreover, with half annotations, our model outperforms the oracle model with full annotations on Waymo.
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
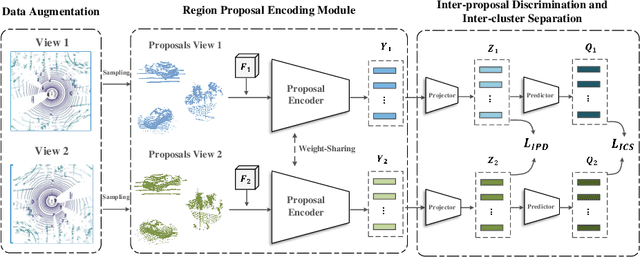
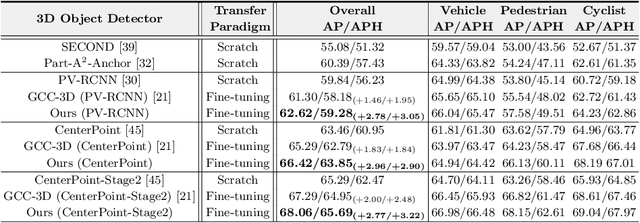
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).
Distilling Ensemble of Explanations for Weakly-Supervised Pre-Training of Image Segmentation Models
Jul 04, 2022While fine-tuning pre-trained networks has become a popular way to train image segmentation models, such backbone networks for image segmentation are frequently pre-trained using image classification source datasets, e.g., ImageNet. Though image classification datasets could provide the backbone networks with rich visual features and discriminative ability, they are incapable of fully pre-training the target model (i.e., backbone+segmentation modules) in an end-to-end manner. The segmentation modules are left to random initialization in the fine-tuning process due to the lack of segmentation labels in classification datasets. In our work, we propose a method that leverages Pseudo Semantic Segmentation Labels (PSSL), to enable the end-to-end pre-training for image segmentation models based on classification datasets. PSSL was inspired by the observation that the explanation results of classification models, obtained through explanation algorithms such as CAM, SmoothGrad and LIME, would be close to the pixel clusters of visual objects. Specifically, PSSL is obtained for each image by interpreting the classification results and aggregating an ensemble of explanations queried from multiple classifiers to lower the bias caused by single models. With PSSL for every image of ImageNet, the proposed method leverages a weighted segmentation learning procedure to pre-train the segmentation network en masse. Experiment results show that, with ImageNet accompanied by PSSL as the source dataset, the proposed end-to-end pre-training strategy successfully boosts the performance of various segmentation models, i.e., PSPNet-ResNet50, DeepLabV3-ResNet50, and OCRNet-HRNetW18, on a number of segmentation tasks, such as CamVid, VOC-A, VOC-C, ADE20K, and CityScapes, with significant improvements. The source code is availabel at https://github.com/PaddlePaddle/PaddleSeg.
A Representation Separation Perspective to Correspondences-free Unsupervised 3D Point Cloud Registration
Mar 24, 2022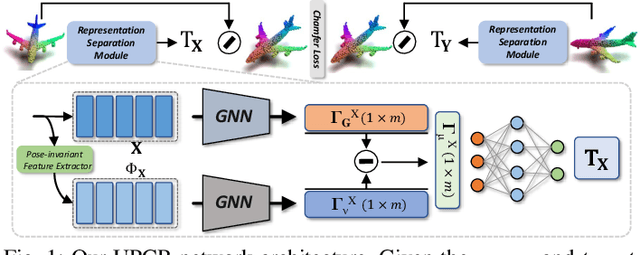
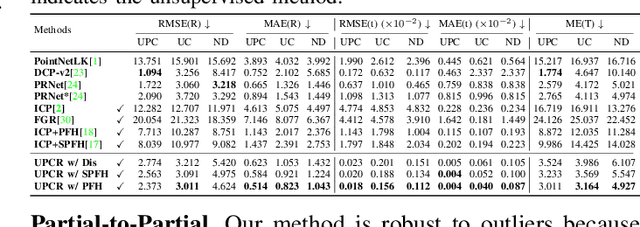
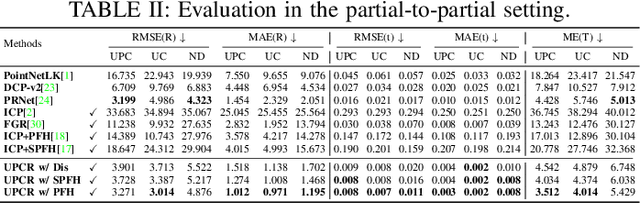
3D point cloud registration in remote sensing field has been greatly advanced by deep learning based methods, where the rigid transformation is either directly regressed from the two point clouds (correspondences-free approaches) or computed from the learned correspondences (correspondences-based approaches). Existing correspondences-free methods generally learn the holistic representation of the entire point cloud, which is fragile for partial and noisy point clouds. In this paper, we propose a correspondences-free unsupervised point cloud registration (UPCR) method from the representation separation perspective. First, we model the input point cloud as a combination of pose-invariant representation and pose-related representation. Second, the pose-related representation is used to learn the relative pose wrt a "latent canonical shape" for the source and target point clouds respectively. Third, the rigid transformation is obtained from the above two learned relative poses. Our method not only filters out the disturbance in pose-invariant representation but also is robust to partial-to-partial point clouds or noise. Experiments on benchmark datasets demonstrate that our unsupervised method achieves comparable if not better performance than state-of-the-art supervised registration methods.
End-to-end Learning the Partial Permutation Matrix for Robust 3D Point Cloud Registration
Oct 28, 2021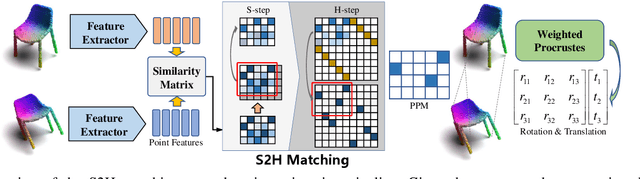
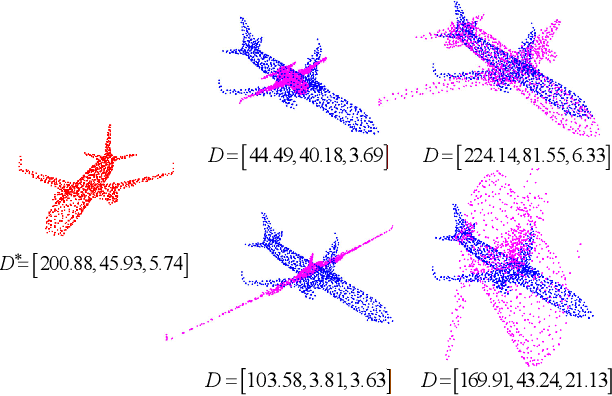
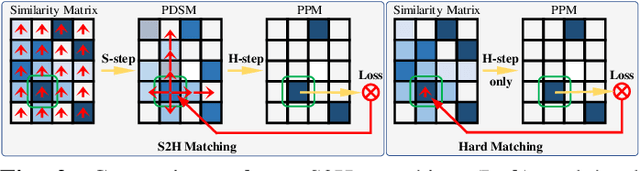
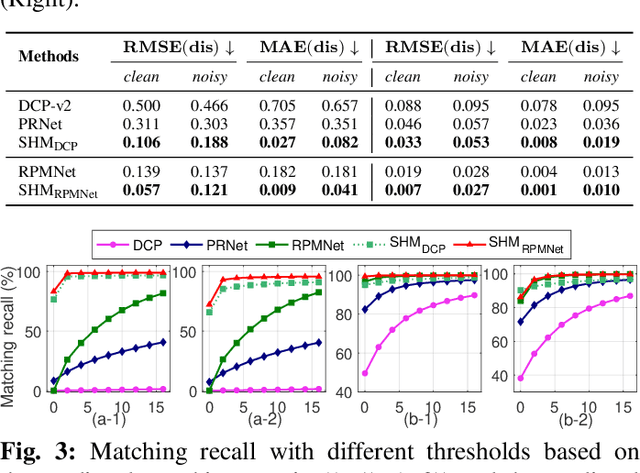
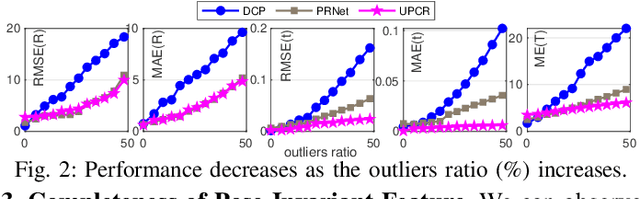
Even though considerable progress has been made in deep learning-based 3D point cloud processing, how to obtain accurate correspondences for robust registration remains a major challenge because existing hard assignment methods cannot deal with outliers naturally. Alternatively, the soft matching-based methods have been proposed to learn the matching probability rather than hard assignment. However, in this paper, we prove that these methods have an inherent ambiguity causing many deceptive correspondences. To address the above challenges, we propose to learn a partial permutation matching matrix, which does not assign corresponding points to outliers, and implements hard assignment to prevent ambiguity. However, this proposal poses two new problems, i.e., existing hard assignment algorithms can only solve a full rank permutation matrix rather than a partial permutation matrix, and this desired matrix is defined in the discrete space, which is non-differentiable. In response, we design a dedicated soft-to-hard (S2H) matching procedure within the registration pipeline consisting of two steps: solving the soft matching matrix (S-step) and projecting this soft matrix to the partial permutation matrix (H-step). Specifically, we augment the profit matrix before the hard assignment to solve an augmented permutation matrix, which is cropped to achieve the final partial permutation matrix. Moreover, to guarantee end-to-end learning, we supervise the learned partial permutation matrix but propagate the gradient to the soft matrix instead. Our S2H matching procedure can be easily integrated with existing registration frameworks, which has been verified in representative frameworks including DCP, RPMNet, and DGR. Extensive experiments have validated our method, which creates a new state-of-the-art performance for robust 3D point cloud registration. The code will be made public.
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Aug 25, 2021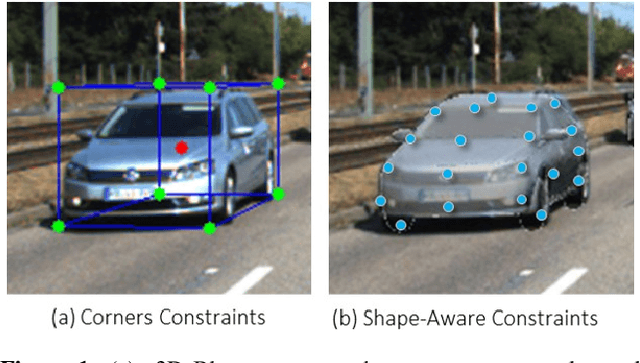
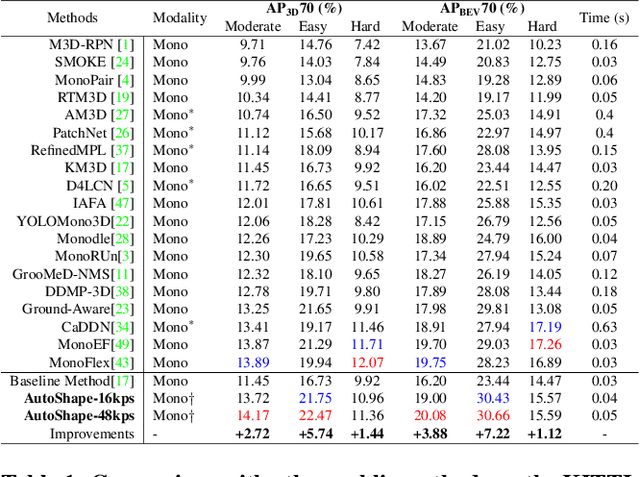
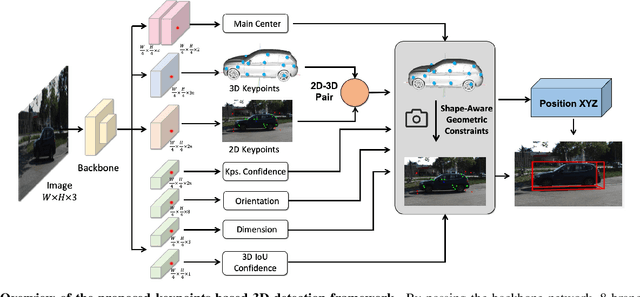
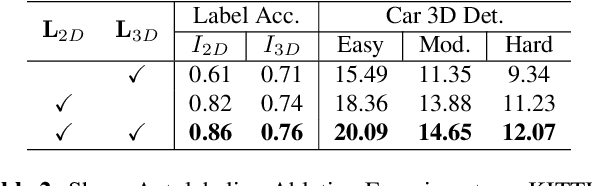
Existing deep learning-based approaches for monocular 3D object detection in autonomous driving often model the object as a rotated 3D cuboid while the object's geometric shape has been ignored. In this work, we propose an approach for incorporating the shape-aware 2D/3D constraints into the 3D detection framework. Specifically, we employ the deep neural network to learn distinguished 2D keypoints in the 2D image domain and regress their corresponding 3D coordinates in the local 3D object coordinate first. Then the 2D/3D geometric constraints are built by these correspondences for each object to boost the detection performance. For generating the ground truth of 2D/3D keypoints, an automatic model-fitting approach has been proposed by fitting the deformed 3D object model and the object mask in the 2D image. The proposed framework has been verified on the public KITTI dataset and the experimental results demonstrate that by using additional geometrical constraints the detection performance has been significantly improved as compared to the baseline method. More importantly, the proposed framework achieves state-of-the-art performance with real time. Data and code will be available at https://github.com/zongdai/AutoShape
FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection
Jun 23, 2021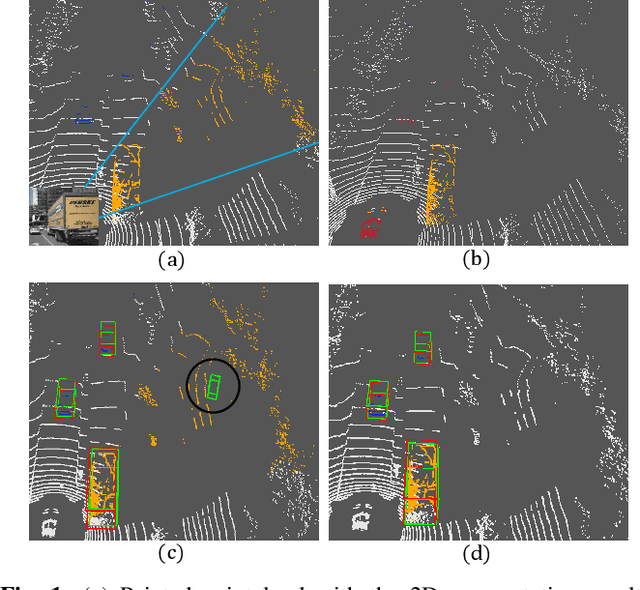
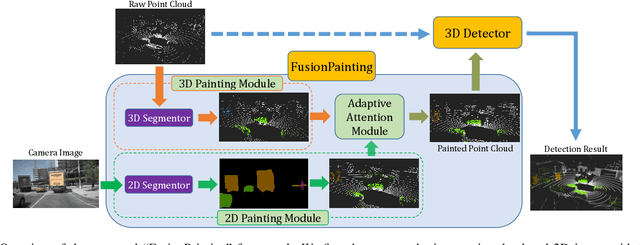
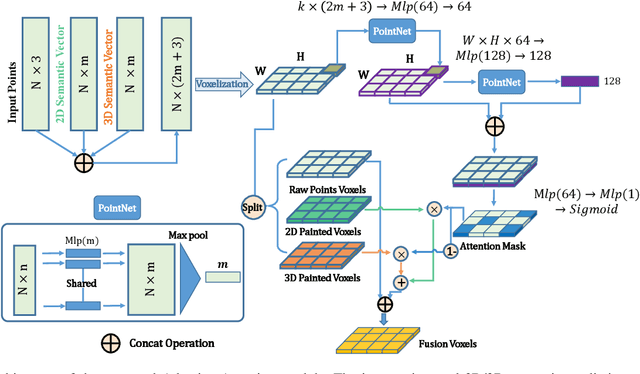
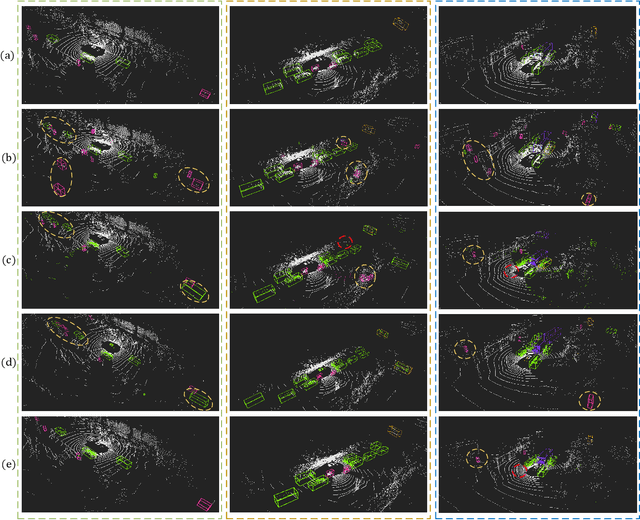
Accurate detection of obstacles in 3D is an essential task for autonomous driving and intelligent transportation. In this work, we propose a general multimodal fusion framework FusionPainting to fuse the 2D RGB image and 3D point clouds at a semantic level for boosting the 3D object detection task. Especially, the FusionPainting framework consists of three main modules: a multi-modal semantic segmentation module, an adaptive attention-based semantic fusion module, and a 3D object detector. First, semantic information is obtained for 2D images and 3D Lidar point clouds based on 2D and 3D segmentation approaches. Then the segmentation results from different sensors are adaptively fused based on the proposed attention-based semantic fusion module. Finally, the point clouds painted with the fused semantic label are sent to the 3D detector for obtaining the 3D objection results. The effectiveness of the proposed framework has been verified on the large-scale nuScenes detection benchmark by comparing it with three different baselines. The experimental results show that the fusion strategy can significantly improve the detection performance compared to the methods using only point clouds, and the methods using point clouds only painted with 2D segmentation information. Furthermore, the proposed approach outperforms other state-of-the-art methods on the nuScenes testing benchmark.