 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFP-Gen: Combinatorial Functional Protein Generation via Diffusion Language Models
May 28, 2025Existing PLMs generate protein sequences based on a single-condition constraint from a specific modality, struggling to simultaneously satisfy multiple constraints across different modalities. In this work, we introduce CFP-Gen, a novel diffusion language model for Combinatorial Functional Protein GENeration. CFP-Gen facilitates the de novo protein design by integrating multimodal conditions with functional, sequence, and structural constraints. Specifically, an Annotation-Guided Feature Modulation (AGFM) module is introduced to dynamically adjust the protein feature distribution based on composable functional annotations, e.g., GO terms, IPR domains and EC numbers. Meanwhile, the Residue-Controlled Functional Encoding (RCFE) module captures residue-wise interaction to ensure more precise control. Additionally, off-the-shelf 3D structure encoders can be seamlessly integrated to impose geometric constraints. We demonstrate that CFP-Gen enables high-throughput generation of novel proteins with functionality comparable to natural proteins, while achieving a high success rate in designing multifunctional proteins. Code and data available at https://github.com/yinjunbo/cfpgen.
OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving
Dec 23, 2024



To enhance autonomous driving safety in complex scenarios, various methods have been proposed to simulate LiDAR point cloud data. Nevertheless, these methods often face challenges in producing high-quality, diverse, and controllable foreground objects. To address the needs of object-aware tasks in 3D perception, we introduce OLiDM, a novel framework capable of generating high-fidelity LiDAR data at both the object and the scene levels. OLiDM consists of two pivotal components: the Object-Scene Progressive Generation (OPG) module and the Object Semantic Alignment (OSA) module. OPG adapts to user-specific prompts to generate desired foreground objects, which are subsequently employed as conditions in scene generation, ensuring controllable outputs at both the object and scene levels. This also facilitates the association of user-defined object-level annotations with the generated LiDAR scenes. Moreover, OSA aims to rectify the misalignment between foreground objects and background scenes, enhancing the overall quality of the generated objects. The broad effectiveness of OLiDM is demonstrated across various LiDAR generation tasks, as well as in 3D perception tasks. Specifically, on the KITTI-360 dataset, OLiDM surpasses prior state-of-the-art methods such as UltraLiDAR by 17.5 in FPD. Additionally, in sparse-to-dense LiDAR completion, OLiDM achieves a significant improvement over LiDARGen, with a 57.47\% increase in semantic IoU. Moreover, OLiDM enhances the performance of mainstream 3D detectors by 2.4\% in mAP and 1.9\% in NDS, underscoring its potential in advancing object-aware 3D tasks. Code is available at: https://yanty123.github.io/OLiDM.
ALOcc: Adaptive Lifting-based 3D Semantic Occupancy and Cost Volume-based Flow Prediction
Nov 12, 2024Vision-based semantic occupancy and flow prediction plays a crucial role in providing spatiotemporal cues for real-world tasks, such as autonomous driving. Existing methods prioritize higher accuracy to cater to the demands of these tasks. In this work, we strive to improve performance by introducing a series of targeted improvements for 3D semantic occupancy prediction and flow estimation. First, we introduce an occlusion-aware adaptive lifting mechanism with a depth denoising technique to improve the robustness of 2D-to-3D feature transformation and reduce the reliance on depth priors. Second, we strengthen the semantic consistency between 3D features and their original 2D modalities by utilizing shared semantic prototypes to jointly constrain both 2D and 3D features. This is complemented by confidence- and category-based sampling strategies to tackle long-tail challenges in 3D space. To alleviate the feature encoding burden in the joint prediction of semantics and flow, we propose a BEV cost volume-based prediction method that links flow and semantic features through a cost volume and employs a classification-regression supervision scheme to address the varying flow scales in dynamic scenes. Our purely convolutional architecture framework, named ALOcc, achieves an optimal tradeoff between speed and accuracy achieving state-of-the-art results on multiple benchmarks. On Occ3D and training without the camera visible mask, our ALOcc achieves an absolute gain of 2.5\% in terms of RayIoU while operating at a comparable speed compared to the state-of-the-art, using the same input size (256$\times$704) and ResNet-50 backbone. Our method also achieves 2nd place in the CVPR24 Occupancy and Flow Prediction Competition.
RepVF: A Unified Vector Fields Representation for Multi-task 3D Perception
Jul 15, 2024Concurrent processing of multiple autonomous driving 3D perception tasks within the same spatiotemporal scene poses a significant challenge, in particular due to the computational inefficiencies and feature competition between tasks when using traditional multi-task learning approaches. This paper addresses these issues by proposing a novel unified representation, RepVF, which harmonizes the representation of various perception tasks such as 3D object detection and 3D lane detection within a single framework. RepVF characterizes the structure of different targets in the scene through a vector field, enabling a single-head, multi-task learning model that significantly reduces computational redundancy and feature competition. Building upon RepVF, we introduce RFTR, a network designed to exploit the inherent connections between different tasks by utilizing a hierarchical structure of queries that implicitly model the relationships both between and within tasks. This approach eliminates the need for task-specific heads and parameters, fundamentally reducing the conflicts inherent in traditional multi-task learning paradigms. We validate our approach by combining labels from the OpenLane dataset with the Waymo Open dataset. Our work presents a significant advancement in the efficiency and effectiveness of multi-task perception in autonomous driving, offering a new perspective on handling multiple 3D perception tasks synchronously and in parallel. The code will be available at: https://github.com/jbji/RepVF
IS-Fusion: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
Mar 22, 2024



Bird's eye view (BEV) representation has emerged as a dominant solution for describing 3D space in autonomous driving scenarios. However, objects in the BEV representation typically exhibit small sizes, and the associated point cloud context is inherently sparse, which leads to great challenges for reliable 3D perception. In this paper, we propose IS-Fusion, an innovative multimodal fusion framework that jointly captures the Instance- and Scene-level contextual information. IS-Fusion essentially differs from existing approaches that only focus on the BEV scene-level fusion by explicitly incorporating instance-level multimodal information, thus facilitating the instance-centric tasks like 3D object detection. It comprises a Hierarchical Scene Fusion (HSF) module and an Instance-Guided Fusion (IGF) module. HSF applies Point-to-Grid and Grid-to-Region transformers to capture the multimodal scene context at different granularities. IGF mines instance candidates, explores their relationships, and aggregates the local multimodal context for each instance. These instances then serve as guidance to enhance the scene feature and yield an instance-aware BEV representation. On the challenging nuScenes benchmark, IS-Fusion outperforms all the published multimodal works to date. Code is available at: https://github.com/yinjunbo/IS-Fusion.
DI-V2X: Learning Domain-Invariant Representation for Vehicle-Infrastructure Collaborative 3D Object Detection
Dec 25, 2023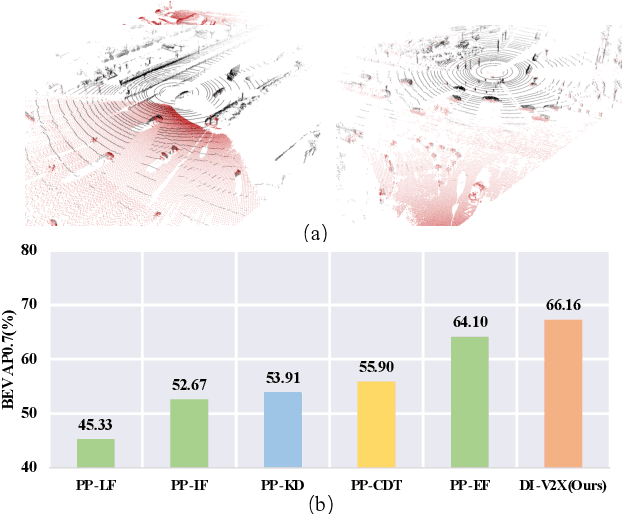
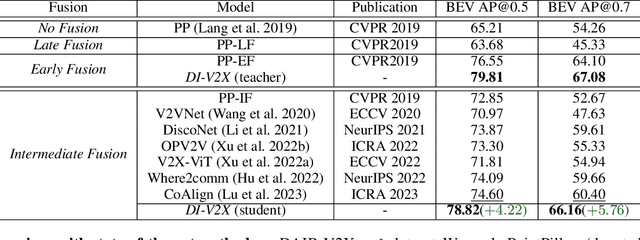
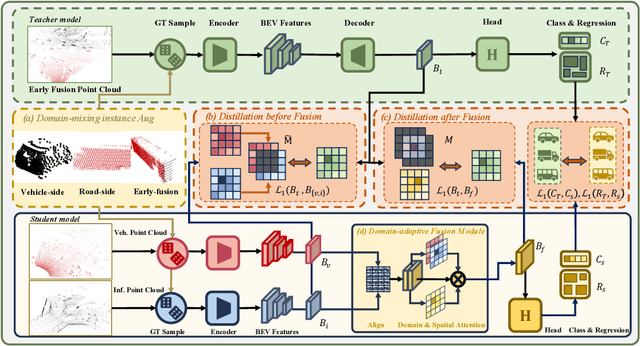
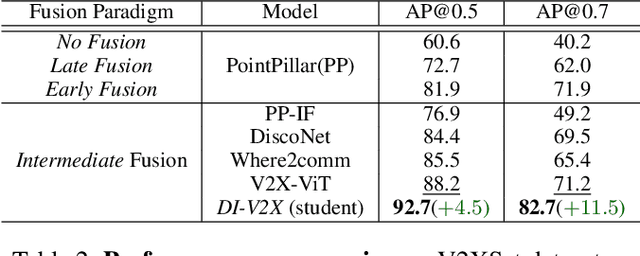
Vehicle-to-Everything (V2X) collaborative perception has recently gained significant attention due to its capability to enhance scene understanding by integrating information from various agents, e.g., vehicles, and infrastructure. However, current works often treat the information from each agent equally, ignoring the inherent domain gap caused by the utilization of different LiDAR sensors of each agent, thus leading to suboptimal performance. In this paper, we propose DI-V2X, that aims to learn Domain-Invariant representations through a new distillation framework to mitigate the domain discrepancy in the context of V2X 3D object detection. DI-V2X comprises three essential components: a domain-mixing instance augmentation (DMA) module, a progressive domain-invariant distillation (PDD) module, and a domain-adaptive fusion (DAF) module. Specifically, DMA builds a domain-mixing 3D instance bank for the teacher and student models during training, resulting in aligned data representation. Next, PDD encourages the student models from different domains to gradually learn a domain-invariant feature representation towards the teacher, where the overlapping regions between agents are employed as guidance to facilitate the distillation process. Furthermore, DAF closes the domain gap between the students by incorporating calibration-aware domain-adaptive attention. Extensive experiments on the challenging DAIR-V2X and V2XSet benchmark datasets demonstrate DI-V2X achieves remarkable performance, outperforming all the previous V2X models. Code is available at https://github.com/Serenos/DI-V2X
Self-Supervised Monocular Depth Estimation by Direction-aware Cumulative Convolution Network
Aug 10, 2023
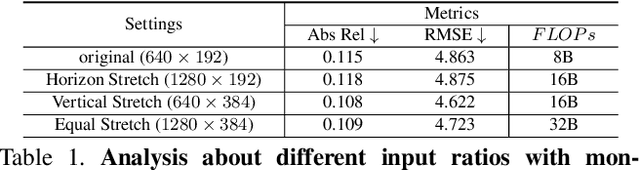

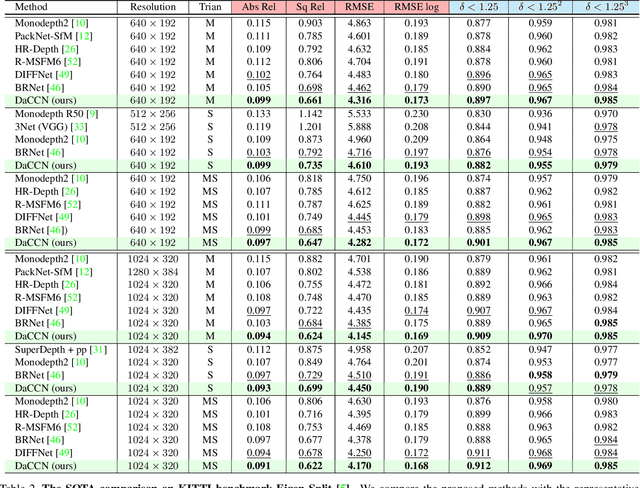
Monocular depth estimation is known as an ill-posed task in which objects in a 2D image usually do not contain sufficient information to predict their depth. Thus, it acts differently from other tasks (e.g., classification and segmentation) in many ways. In this paper, we find that self-supervised monocular depth estimation shows a direction sensitivity and environmental dependency in the feature representation. But the current backbones borrowed from other tasks pay less attention to handling different types of environmental information, limiting the overall depth accuracy. To bridge this gap, we propose a new Direction-aware Cumulative Convolution Network (DaCCN), which improves the depth feature representation in two aspects. First, we propose a direction-aware module, which can learn to adjust the feature extraction in each direction, facilitating the encoding of different types of information. Secondly, we design a new cumulative convolution to improve the efficiency for aggregating important environmental information. Experiments show that our method achieves significant improvements on three widely used benchmarks, KITTI, Cityscapes, and Make3D, setting a new state-of-the-art performance on the popular benchmarks with all three types of self-supervision.
Language-Guided 3D Object Detection in Point Cloud for Autonomous Driving
May 25, 2023



This paper addresses the problem of 3D referring expression comprehension (REC) in autonomous driving scenario, which aims to ground a natural language to the targeted region in LiDAR point clouds. Previous approaches for REC usually focus on the 2D or 3D-indoor domain, which is not suitable for accurately predicting the location of the queried 3D region in an autonomous driving scene. In addition, the upper-bound limitation and the heavy computation cost motivate us to explore a better solution. In this work, we propose a new multi-modal visual grounding task, termed LiDAR Grounding. Then we devise a Multi-modal Single Shot Grounding (MSSG) approach with an effective token fusion strategy. It jointly learns the LiDAR-based object detector with the language features and predicts the targeted region directly from the detector without any post-processing. Moreover, the image feature can be flexibly integrated into our approach to provide rich texture and color information. The cross-modal learning enforces the detector to concentrate on important regions in the point cloud by considering the informative language expressions, thus leading to much better accuracy and efficiency. Extensive experiments on the Talk2Car dataset demonstrate the effectiveness of the proposed methods. Our work offers a deeper insight into the LiDAR-based grounding task and we expect it presents a promising direction for the autonomous driving community.
LWSIS: LiDAR-guided Weakly Supervised Instance Segmentation for Autonomous Driving
Dec 07, 2022
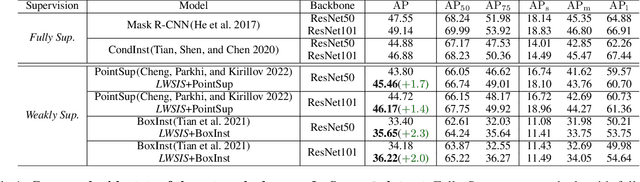
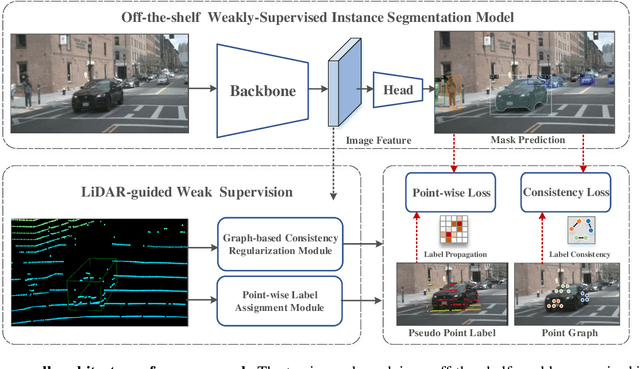
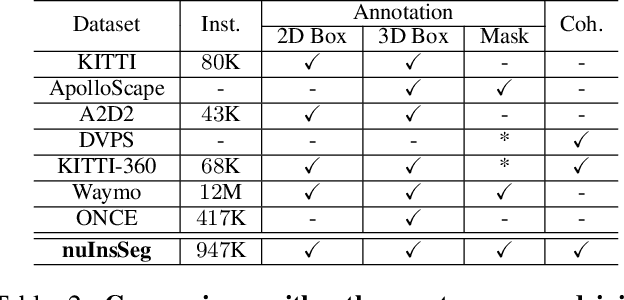
Image instance segmentation is a fundamental research topic in autonomous driving, which is crucial for scene understanding and road safety. Advanced learning-based approaches often rely on the costly 2D mask annotations for training. In this paper, we present a more artful framework, LiDAR-guided Weakly Supervised Instance Segmentation (LWSIS), which leverages the off-the-shelf 3D data, i.e., Point Cloud, together with the 3D boxes, as natural weak supervisions for training the 2D image instance segmentation models. Our LWSIS not only exploits the complementary information in multimodal data during training, but also significantly reduces the annotation cost of the dense 2D masks. In detail, LWSIS consists of two crucial modules, Point Label Assignment (PLA) and Graph-based Consistency Regularization (GCR). The former module aims to automatically assign the 3D point cloud as 2D point-wise labels, while the latter further refines the predictions by enforcing geometry and appearance consistency of the multimodal data. Moreover, we conduct a secondary instance segmentation annotation on the nuScenes, named nuInsSeg, to encourage further research on multimodal perception tasks. Extensive experiments on the nuInsSeg, as well as the large-scale Waymo, show that LWSIS can substantially improve existing weakly supervised segmentation models by only involving 3D data during training. Additionally, LWSIS can also be incorporated into 3D object detectors like PointPainting to boost the 3D detection performance for free. The code and dataset are available at https://github.com/Serenos/LWSIS.
SSDA3D: Semi-supervised Domain Adaptation for 3D Object Detection from Point Cloud
Dec 06, 2022
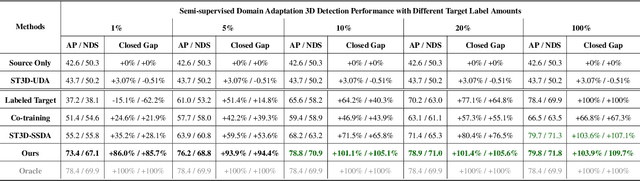
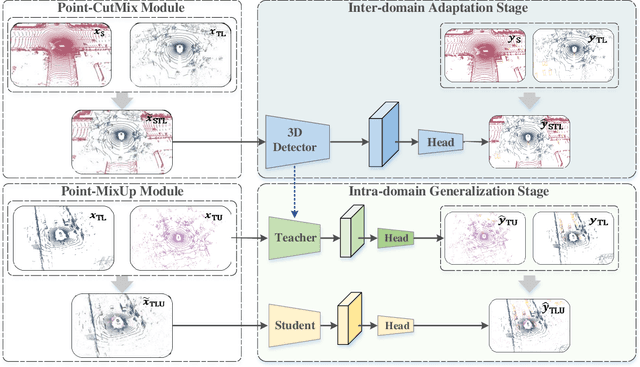

LiDAR-based 3D object detection is an indispensable task in advanced autonomous driving systems. Though impressive detection results have been achieved by superior 3D detectors, they suffer from significant performance degeneration when facing unseen domains, such as different LiDAR configurations, different cities, and weather conditions. The mainstream approaches tend to solve these challenges by leveraging unsupervised domain adaptation (UDA) techniques. However, these UDA solutions just yield unsatisfactory 3D detection results when there is a severe domain shift, e.g., from Waymo (64-beam) to nuScenes (32-beam). To address this, we present a novel Semi-Supervised Domain Adaptation method for 3D object detection (SSDA3D), where only a few labeled target data is available, yet can significantly improve the adaptation performance. In particular, our SSDA3D includes an Inter-domain Adaptation stage and an Intra-domain Generalization stage. In the first stage, an Inter-domain Point-CutMix module is presented to efficiently align the point cloud distribution across domains. The Point-CutMix generates mixed samples of an intermediate domain, thus encouraging to learn domain-invariant knowledge. Then, in the second stage, we further enhance the model for better generalization on the unlabeled target set. This is achieved by exploring Intra-domain Point-MixUp in semi-supervised learning, which essentially regularizes the pseudo label distribution. Experiments from Waymo to nuScenes show that, with only 10% labeled target data, our SSDA3D can surpass the fully-supervised oracle model with 100% target label. Our code is available at https://github.com/yinjunbo/SSDA3D.