 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRACE: A Benchmark for Robust Audio Caption Quality Evaluation
Dec 11, 2025
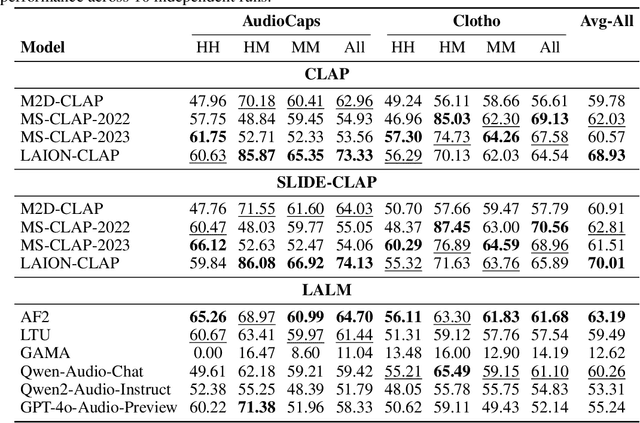
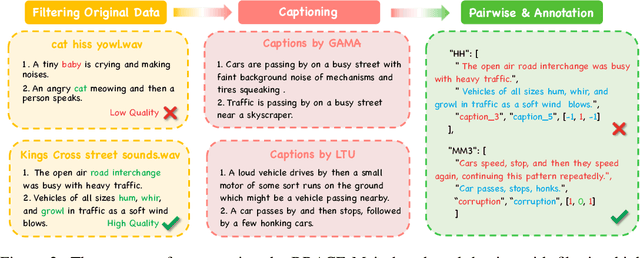
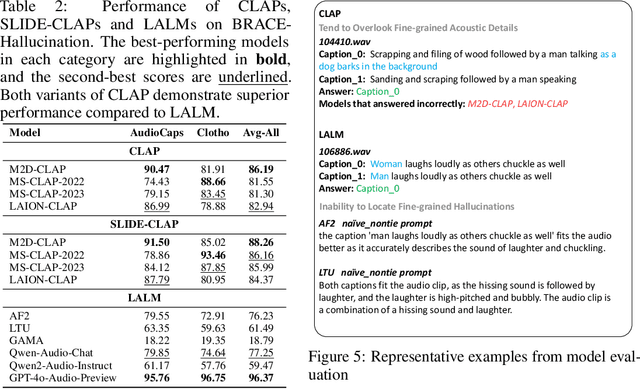
Automatic audio captioning is essential for audio understanding, enabling applications such as accessibility and content indexing. However, evaluating the quality of audio captions remains a major challenge, especially in reference-free settings where high-quality ground-truth captions are unavailable. While CLAPScore is currently the most widely used reference-free Audio Caption Evaluation Metric(ACEM), its robustness under diverse conditions has not been systematically validated. To address this gap, we introduce BRACE, a new benchmark designed to evaluate audio caption alignment quality in a reference-free setting. BRACE is primarily designed for assessing ACEMs, and can also be extended to measure the modality alignment abilities of Large Audio Language Model(LALM). BRACE consists of two sub-benchmarks: BRACE-Main for fine-grained caption comparison and BRACE-Hallucination for detecting subtle hallucinated content. We construct these datasets through high-quality filtering, LLM-based corruption, and human annotation. Given the widespread adoption of CLAPScore as a reference-free ACEM and the increasing application of LALMs in audio-language tasks, we evaluate both approaches using the BRACE benchmark, testing CLAPScore across various CLAP model variants and assessing multiple LALMs. Notably, even the best-performing CLAP-based ACEM achieves only a 70.01 F1-score on the BRACE-Main benchmark, while the best LALM reaches just 63.19. By revealing the limitations of CLAP models and LALMs, our BRACE benchmark offers valuable insights into the direction of future research.
GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
Nov 14, 2025
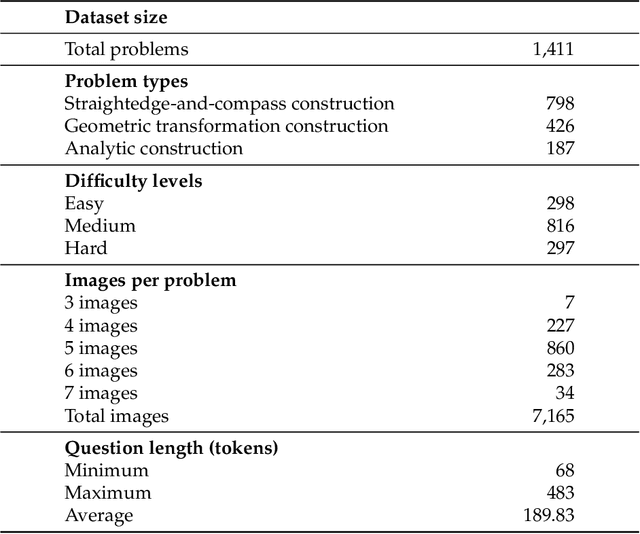
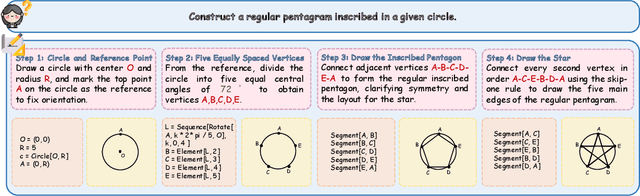

The advent of Unified Multimodal Models (UMMs) signals a paradigm shift in artificial intelligence, moving from passive perception to active, cross-modal generation. Despite their unprecedented ability to synthesize information, a critical gap persists in evaluation: existing benchmarks primarily assess discriminative understanding or unconstrained image generation separately, failing to measure the integrated cognitive process of generative reasoning. To bridge this gap, we propose that geometric construction provides an ideal testbed as it inherently demands a fusion of language comprehension and precise visual generation. We introduce GGBench, a benchmark designed specifically to evaluate geometric generative reasoning. It provides a comprehensive framework for systematically diagnosing a model's ability to not only understand and reason but to actively construct a solution, thereby setting a more rigorous standard for the next generation of intelligent systems. Project website: https://opendatalab-raiser.github.io/GGBench/.
Rethinking Text-to-SQL: Dynamic Multi-turn SQL Interaction for Real-world Database Exploration
Oct 30, 2025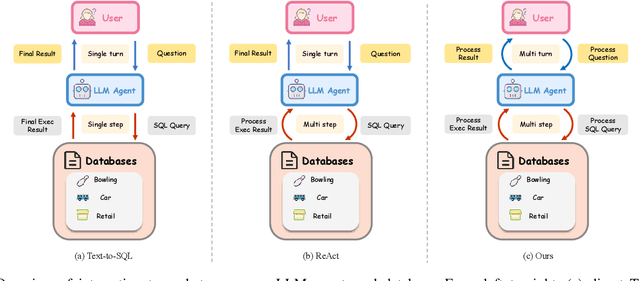



Recent advances in Text-to-SQL have achieved strong results in static, single-turn tasks, where models generate SQL queries from natural language questions. However, these systems fall short in real-world interactive scenarios, where user intents evolve and queries must be refined over multiple turns. In applications such as finance and business analytics, users iteratively adjust query constraints or dimensions based on intermediate results. To evaluate such dynamic capabilities, we introduce DySQL-Bench, a benchmark assessing model performance under evolving user interactions. Unlike previous manually curated datasets, DySQL-Bench is built through an automated two-stage pipeline of task synthesis and verification. Structured tree representations derived from raw database tables guide LLM-based task generation, followed by interaction-oriented filtering and expert validation. Human evaluation confirms 100% correctness of the synthesized data. We further propose a multi-turn evaluation framework simulating realistic interactions among an LLM-simulated user, the model under test, and an executable database. The model must adapt its reasoning and SQL generation as user intents change. DySQL-Bench covers 13 domains across BIRD and Spider 2 databases, totaling 1,072 tasks. Even GPT-4o attains only 58.34% overall accuracy and 23.81% on the Pass@5 metric, underscoring the benchmark's difficulty. All code and data are released at https://github.com/Aurora-slz/Real-World-SQL-Bench .
MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification
Feb 19, 2025



According to the Test-Time Scaling, the integration of External Slow-Thinking with the Verify mechanism has been demonstrated to enhance multi-round reasoning in large language models (LLMs). However, in the multimodal (MM) domain, there is still a lack of a strong MM-Verifier. In this paper, we introduce MM-Verifier and MM-Reasoner to enhance multimodal reasoning through longer inference and more robust verification. First, we propose a two-step MM verification data synthesis method, which combines a simulation-based tree search with verification and uses rejection sampling to generate high-quality Chain-of-Thought (COT) data. This data is then used to fine-tune the verification model, MM-Verifier. Additionally, we present a more efficient method for synthesizing MMCOT data, bridging the gap between text-based and multimodal reasoning. The synthesized data is used to fine-tune MM-Reasoner. Our MM-Verifier outperforms all larger models on the MathCheck, MathVista, and MathVerse benchmarks. Moreover, MM-Reasoner demonstrates strong effectiveness and scalability, with performance improving as data size increases. Finally, our approach achieves strong performance when combining MM-Reasoner and MM-Verifier, reaching an accuracy of 65.3 on MathVista, surpassing GPT-4o (63.8) with 12 rollouts.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
BEATS: Optimizing LLM Mathematical Capabilities with BackVerify and Adaptive Disambiguate based Efficient Tree Search
Sep 26, 2024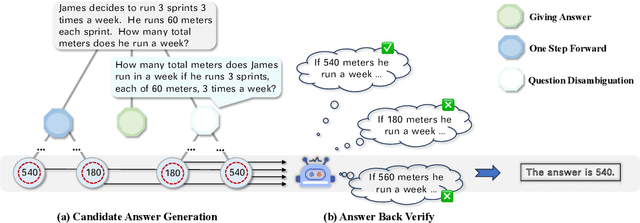


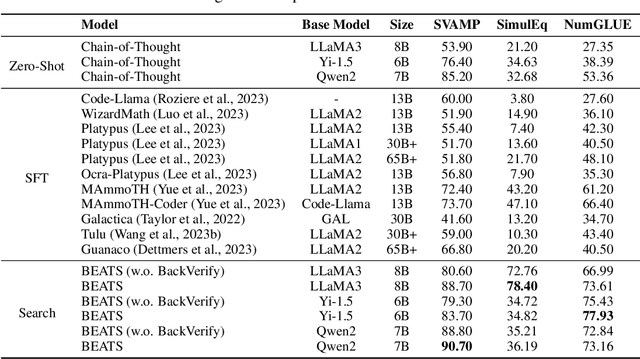
Large Language Models (LLMs) have exhibited exceptional performance across a broad range of tasks and domains. However, they still encounter difficulties in solving mathematical problems due to the rigorous and logical nature of mathematics. Previous studies have employed techniques such as supervised fine-tuning (SFT), prompt engineering, and search-based methods to improve the mathematical problem-solving abilities of LLMs. Despite these efforts, their performance remains suboptimal and demands substantial computational resources. To address this issue, we propose a novel approach, BEATS, to enhance mathematical problem-solving abilities. Our method leverages newly designed prompts that guide the model to iteratively rewrite, advance by one step, and generate answers based on previous steps. Additionally, we introduce a new back-verification technique that uses LLMs to validate the correctness of the generated answers. Furthermore, we employ a pruning tree search to optimize search time while achieving strong performance. Notably, our method improves Qwen2-7b-Instruct's score from 36.94 to 61.52, outperforming GPT4's 42.5 on the MATH benchmark.
MathScape: Evaluating MLLMs in multimodal Math Scenarios through a Hierarchical Benchmark
Aug 15, 2024With the development of Multimodal Large Language Models (MLLMs), the evaluation of multimodal models in the context of mathematical problems has become a valuable research field. Multimodal visual-textual mathematical reasoning serves as a critical indicator for evaluating the comprehension and complex multi-step quantitative reasoning abilities of MLLMs. However, previous multimodal math benchmarks have not sufficiently integrated visual and textual information. To address this gap, we proposed MathScape, a new benchmark that emphasizes the understanding and application of combined visual and textual information. MathScape is designed to evaluate photo-based math problem scenarios, assessing the theoretical understanding and application ability of MLLMs through a categorical hierarchical approach. We conduct a multi-dimensional evaluation on 11 advanced MLLMs, revealing that our benchmark is challenging even for the most sophisticated models. By analyzing the evaluation results, we identify the limitations of MLLMs, offering valuable insights for enhancing model performance.
SynthVLM: High-Efficiency and High-Quality Synthetic Data for Vision Language Models
Aug 01, 2024



Recently, with the rise of web images, managing and understanding large-scale image datasets has become increasingly important. Vision Large Language Models (VLLMs) have recently emerged due to their robust vision-understanding capabilities. However, training these models requires vast amounts of data, posing challenges to efficiency, effectiveness, data quality, and privacy. In this paper, we introduce SynthVLM, a novel data synthesis pipeline for VLLMs. Unlike existing methods that generate captions from images, SynthVLM employs advanced diffusion models and high-quality captions to automatically generate and select high-resolution images from captions, creating precisely aligned image-text pairs. Leveraging these pairs, we achieve state-of-the-art (SoTA) performance on various vision question answering tasks, maintaining high alignment quality and preserving advanced language abilities. Moreover, SynthVLM surpasses traditional GPT-4 Vision-based caption generation methods in performance while significantly reducing computational overhead. Crucially, our method's reliance on purely generated data ensures the preservation of privacy, achieving SoTA performance with just 100k data points (only 18% of the official dataset size).
Synth-Empathy: Towards High-Quality Synthetic Empathy Data
Jul 31, 2024In recent years, with the rapid advancements in large language models (LLMs), achieving excellent empathetic response capabilities has become a crucial prerequisite. Consequently, managing and understanding empathetic datasets have gained increasing significance. However, empathetic data are typically human-labeled, leading to insufficient datasets and wasted human labor. In this work, we present Synth-Empathy, an LLM-based data generation and quality and diversity selection pipeline that automatically generates high-quality empathetic data while discarding low-quality data. With the data generated from a low empathetic model, we are able to further improve empathetic response performance and achieve state-of-the-art (SoTA) results across multiple benchmarks. Moreover, our model achieves SoTA performance on various human evaluation benchmarks, demonstrating its effectiveness and robustness in real-world applications. Furthermore, we show the trade-off between data quantity and quality, providing insights into empathetic data generation and selection.