 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Visualization With Variational Autoencoder
Sep 16, 2025We present a new method to visualize data ensembles by constructing structured probabilistic representations in latent spaces, i.e., lower-dimensional representations of spatial data features. Our approach transforms the spatial features of an ensemble into a latent space through feature space conversion and unsupervised learning using a variational autoencoder (VAE). The resulting latent spaces follow multivariate standard Gaussian distributions, enabling analytical computation of confidence intervals and density estimation of the probabilistic distribution that generates the data ensemble. Preliminary results on a weather forecasting ensemble demonstrate the effectiveness and versatility of our method.
M2IO-R1: An Efficient RL-Enhanced Reasoning Framework for Multimodal Retrieval Augmented Multimodal Generation
Aug 08, 2025Current research on Multimodal Retrieval-Augmented Generation (MRAG) enables diverse multimodal inputs but remains limited to single-modality outputs, restricting expressive capacity and practical utility. In contrast, real-world applications often demand both multimodal inputs and multimodal outputs for effective communication and grounded reasoning. Motivated by the recent success of Reinforcement Learning (RL) in complex reasoning tasks for Large Language Models (LLMs), we adopt RL as a principled and effective paradigm to address the multi-step, outcome-driven challenges inherent in multimodal output generation. Here, we introduce M2IO-R1, a novel framework for Multimodal Retrieval-Augmented Multimodal Generation (MRAMG) that supports both multimodal inputs and outputs. Central to our framework is an RL-based inserter, Inserter-R1-3B, trained with Group Relative Policy Optimization to guide image selection and placement in a controllable and semantically aligned manner. Empirical results show that our lightweight 3B inserter achieves strong reasoning capabilities with significantly reduced latency, outperforming baselines in both quality and efficiency.
HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation
Feb 18, 2025Retrieval-Augmented Generation (RAG) systems often struggle with imperfect retrieval, as traditional retrievers focus on lexical or semantic similarity rather than logical relevance. To address this, we propose HopRAG, a novel RAG framework that augments retrieval with logical reasoning through graph-structured knowledge exploration. During indexing, HopRAG constructs a passage graph, with text chunks as vertices and logical connections established via LLM-generated pseudo-queries as edges. During retrieval, it employs a retrieve-reason-prune mechanism: starting with lexically or semantically similar passages, the system explores multi-hop neighbors guided by pseudo-queries and LLM reasoning to identify truly relevant ones. Extensive experiments demonstrate HopRAG's superiority, achieving 76.78\% higher answer accuracy and 65.07\% improved retrieval F1 score compared to conventional methods. The repository is available at https://github.com/LIU-Hao-2002/HopRAG.
MRAMG-Bench: A BeyondText Benchmark for Multimodal Retrieval-Augmented Multimodal Generation
Feb 06, 2025Recent advancements in Retrieval-Augmented Generation (RAG) have shown remarkable performance in enhancing response accuracy and relevance by integrating external knowledge into generative models. However, existing RAG methods primarily focus on providing text-only answers, even in multimodal retrieval-augmented generation scenarios. In this work, we introduce the Multimodal Retrieval-Augmented Multimodal Generation (MRAMG) task, which aims to generate answers that combine both text and images, fully leveraging the multimodal data within a corpus. Despite the importance of this task, there is a notable absence of a comprehensive benchmark to effectively evaluate MRAMG performance. To bridge this gap, we introduce the MRAMG-Bench, a carefully curated, human-annotated dataset comprising 4,346 documents, 14,190 images, and 4,800 QA pairs, sourced from three categories: Web Data, Academic Papers, and Lifestyle. The dataset incorporates diverse difficulty levels and complex multi-image scenarios, providing a robust foundation for evaluating multimodal generation tasks. To facilitate rigorous evaluation, our MRAMG-Bench incorporates a comprehensive suite of both statistical and LLM-based metrics, enabling a thorough analysis of the performance of popular generative models in the MRAMG task. Besides, we propose an efficient multimodal answer generation framework that leverages both LLMs and MLLMs to generate multimodal responses. Our datasets are available at: https://huggingface.co/MRAMG.
QAEncoder: Towards Aligned Representation Learning in Question Answering System
Sep 30, 2024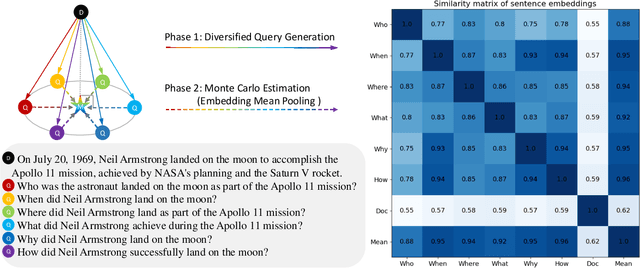
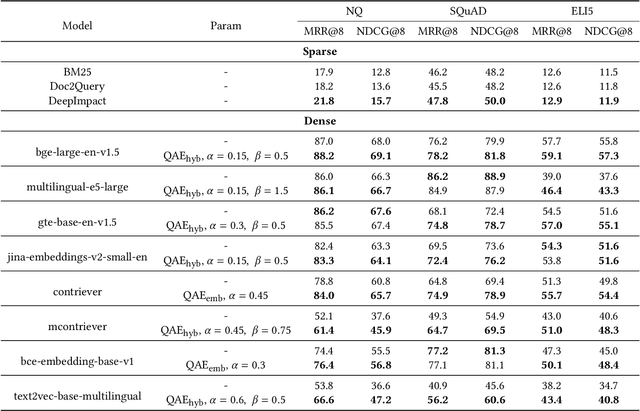
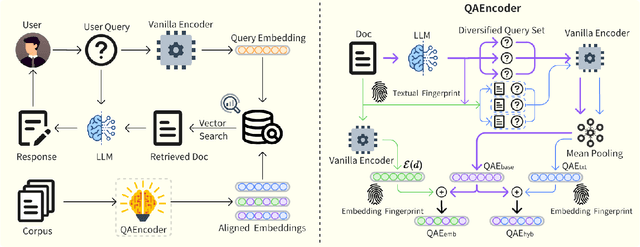
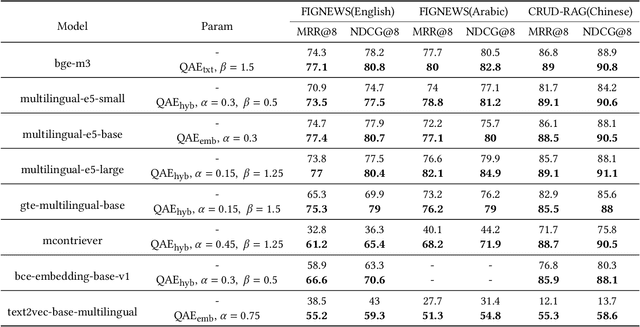
Modern QA systems entail retrieval-augmented generation (RAG) for accurate and trustworthy responses. However, the inherent gap between user queries and relevant documents hinders precise matching. Motivated by our conical distribution hypothesis, which posits that potential queries and documents form a cone-like structure in the embedding space, we introduce QAEncoder, a training-free approach to bridge this gap. Specifically, QAEncoder estimates the expectation of potential queries in the embedding space as a robust surrogate for the document embedding, and attaches document fingerprints to effectively distinguish these embeddings. Extensive experiments on fourteen embedding models across six languages and eight datasets validate QAEncoder's alignment capability, which offers a plug-and-play solution that seamlessly integrates with existing RAG architectures and training-based methods.
SynthVLM: High-Efficiency and High-Quality Synthetic Data for Vision Language Models
Aug 01, 2024



Recently, with the rise of web images, managing and understanding large-scale image datasets has become increasingly important. Vision Large Language Models (VLLMs) have recently emerged due to their robust vision-understanding capabilities. However, training these models requires vast amounts of data, posing challenges to efficiency, effectiveness, data quality, and privacy. In this paper, we introduce SynthVLM, a novel data synthesis pipeline for VLLMs. Unlike existing methods that generate captions from images, SynthVLM employs advanced diffusion models and high-quality captions to automatically generate and select high-resolution images from captions, creating precisely aligned image-text pairs. Leveraging these pairs, we achieve state-of-the-art (SoTA) performance on various vision question answering tasks, maintaining high alignment quality and preserving advanced language abilities. Moreover, SynthVLM surpasses traditional GPT-4 Vision-based caption generation methods in performance while significantly reducing computational overhead. Crucially, our method's reliance on purely generated data ensures the preservation of privacy, achieving SoTA performance with just 100k data points (only 18% of the official dataset size).
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Feb 29, 2024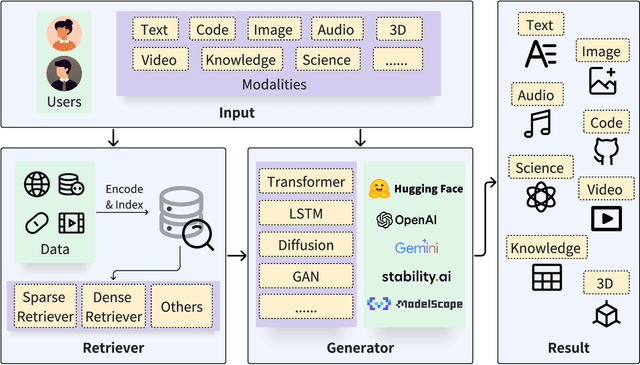
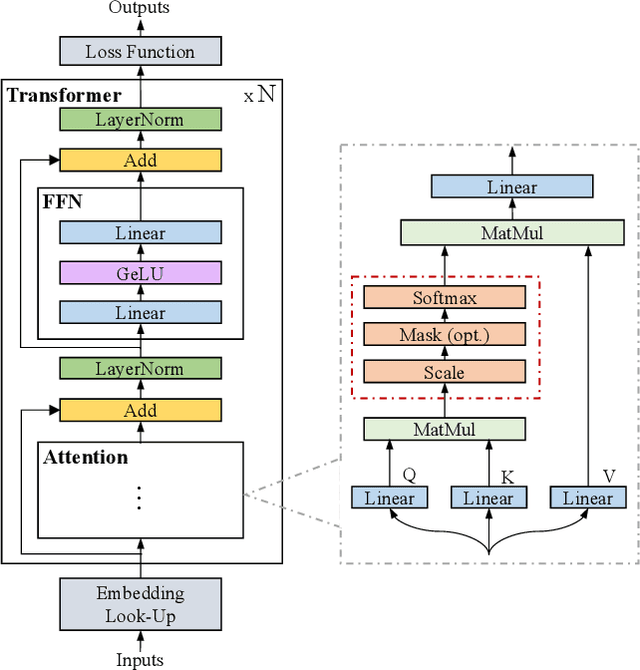
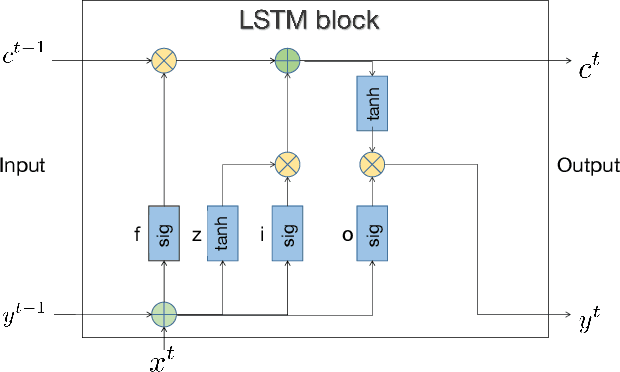
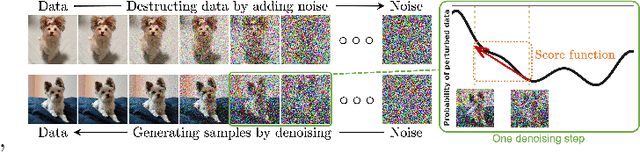
The development of Artificial Intelligence Generated Content (AIGC) has been facilitated by advancements in model algorithms, scalable foundation model architectures, and the availability of ample high-quality datasets. While AIGC has achieved remarkable performance, it still faces challenges, such as the difficulty of maintaining up-to-date and long-tail knowledge, the risk of data leakage, and the high costs associated with training and inference. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances AIGC results by retrieving relevant objects from available data stores, leading to greater accuracy and robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator. We distill the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Project: https://github.com/hymie122/RAG-Survey