 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Before Agreeing: Aligning Multi-Agent Consensus with Visual Evidence
May 29, 2026Vision-language models (VLMs) have achieved strong performance on visual question answering (VQA). To mitigate individual hallucinations and blind spots, aggregating diverse perspectives via multi-agent collaboration has emerged as a promising paradigm. While this approach has shown great success in textual QA, its potential in the multimodal domain remains under-explored. Existing multi-agent VQA methods predominantly adapt text-centric protocols, focusing on textual discussions while ignoring the alignment of visual information. In this work, we reveal a key insight: answer-level agreement is insufficient for reliable multi-agent VQA; \textit{aligned visual evidence} -- shared support from the image regions agents rely on -- is essential for trustworthy consensus. To leverage this insight, we propose EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning), a training-free evidence-centered framework for coordinating multiple VLM agents. EAGLE explicitly exposes each agent's grounding regions as visual evidence, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making. Experiments on six VQA benchmarks show that EAGLE achieves best average performance across domains while remaining lightweight, interpretable, and practical for deployment.
CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
May 13, 2026Multimodal Large Language Models (MLLMs) have significantly advanced document understanding, yet current Doc-VQA evaluations score only the final answer and leave the supporting evidence unchecked. This answer-only approach masks a critical failure mode: a model can land on the correct answer while grounding it in the wrong passage -- a critical risk in high-stakes domains like law, finance, and medicine, where every conclusion must be traceable to a specific source region. To address this, we introduce CiteVQA, a benchmark that requires models to return element-level bounding-box citations alongside each answer, evaluating both jointly. CiteVQA comprises 1,897 questions across 711 PDFs spanning seven domains and two languages, averaging 40.6 pages per document. To ensure fidelity and scalability, the ground-truth citations are generated by an automated pipeline-which identifies crucial evidence via masking ablation-and are subsequently validated through expert review. At the core of our evaluation is Strict Attributed Accuracy (SAA), which credits a prediction only when the answer and the cited region are both correct. Auditing 20 MLLMs reveals a pervasive Attribution Hallucination: models frequently produce the right answer while citing the wrong region. The strongest system (Gemini-3.1-Pro-Preview) achieves an SAA of only 76.0, and the strongest open-source MLLM reaches just 22.5. Ultimately, towards trustworthy document intelligence, CiteVQA exposes a reliability gap that answer-only evaluations overlook, providing the instrumentation needed to close it. Our repository is available at https://github.com/opendatalab/CiteVQA.
AgenticOCR: Parsing Only What You Need for Efficient Retrieval-Augmented Generation
Feb 27, 2026The expansion of retrieval-augmented generation (RAG) into multimodal domains has intensified the challenge for processing complex visual documents, such as financial reports. While page-level chunking and retrieval is a natural starting point, it creates a critical bottleneck: delivering entire pages to the generator introduces excessive extraneous context. This not only overloads the generator's attention mechanism but also dilutes the most salient evidence. Moreover, compressing these information-rich pages into a limited visual token budget further increases the risk of hallucinations. To address this, we introduce AgenticOCR, a dynamic parsing paradigm that transforms optical character recognition (OCR) from a static, full-text process into a query-driven, on-demand extraction system. By autonomously analyzing document layout in a "thinking with images" manner, AgenticOCR identifies and selectively recognizes regions of interest. This approach performs on-demand decompression of visual tokens precisely where needed, effectively decoupling retrieval granularity from rigid page-level chunking. AgenticOCR has the potential to serve as the "third building block" of the visual document RAG stack, operating alongside and enhancing standard Embedding and Reranking modules. Experimental results demonstrate that AgenticOCR improves both the efficiency and accuracy of visual RAG systems, achieving expert-level performance in long document understanding. Code and models are available at https://github.com/OpenDataLab/AgenticOCR.
SWE-MiniSandbox: Container-Free Reinforcement Learning for Building Software Engineering Agents
Feb 11, 2026Reinforcement learning (RL) has become a key paradigm for training software engineering (SWE) agents, but existing pipelines typically rely on per-task containers for isolation. At scale, pre-built container images incur substantial storage overhead, slow environment setup, and require container-management privileges. We propose SWE-MiniSandbox, a lightweight, container-free method that enables scalable RL training of SWE agents without sacrificing isolation. Instead of relying on per-instance containers, SWE-MiniSandbox executes each task in an isolated workspace backed by kernel-level mechanisms, substantially reducing system overhead. It leverages lightweight environment pre-caching techniques to eliminate the need for bulky container images. As a result, our approach lowers disk usage to approximately 5\% of that required by container-based pipelines and reduces environment preparation time to about 25\% of the container baseline. Empirical results demonstrate that SWE-MiniSandbox achieves evaluation performance comparable to standard container-based pipelines. By removing the dependency on heavy container infrastructure, SWE-MiniSandbox offers a practical and accessible foundation for scaling RL-based SWE agents, particularly in resource-constrained research environments.
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Apr 30, 2025
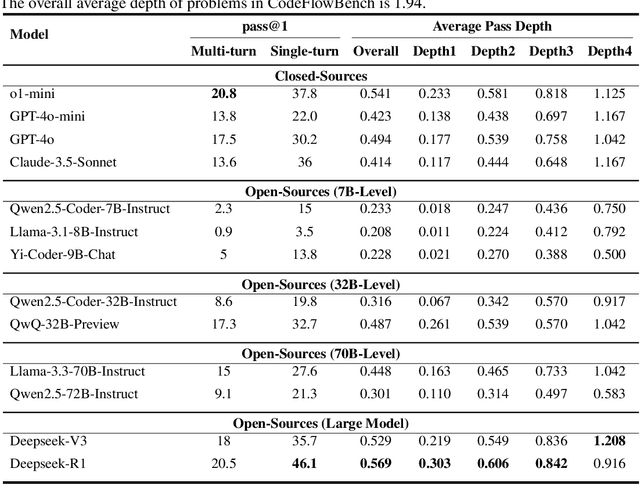


Real world development demands code that is readable, extensible, and testable by organizing the implementation into modular components and iteratively reuse pre-implemented code. We term this iterative, multi-turn process codeflow and introduce CodeFlowBench, the first benchmark designed for comprehensively evaluating LLMs' ability to perform codeflow, namely to implement new functionality by reusing existing functions over multiple turns. CodeFlowBench comprises 5258 problems drawn from Codeforces and is continuously updated via an automated pipeline that decomposes each problem into a series of function-level subproblems based on its dependency tree and each subproblem is paired with unit tests. We further propose a novel evaluation framework with tasks and metrics tailored to multi-turn code reuse to assess model performance. In experiments across various LLMs under both multi-turn and single-turn patterns. We observe models' poor performance on CodeFlowBench, with a substantial performance drop in the iterative codeflow scenario. For instance, o1-mini achieves a pass@1 of 20.8% in multi-turn pattern versus 37.8% in single-turn pattern. Further analysis shows that different models excel at different dependency depths, yet all struggle to correctly solve structurally complex problems, highlighting challenges for current LLMs to serve as code generation tools when performing codeflow. Overall, CodeFlowBench offers a comprehensive benchmark and new insights into LLM capabilities for multi-turn, iterative code generation, guiding future advances in code generation tasks.
MaintainCoder: Maintainable Code Generation Under Dynamic Requirements
Mar 31, 2025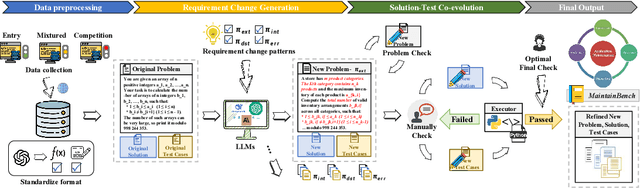
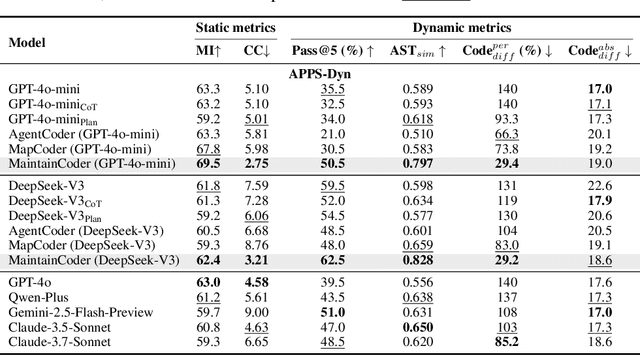
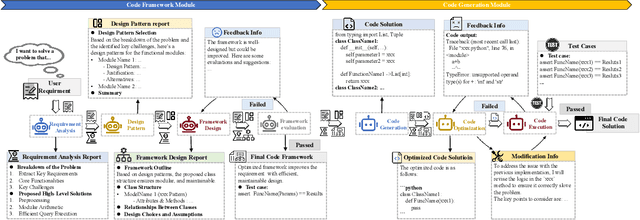
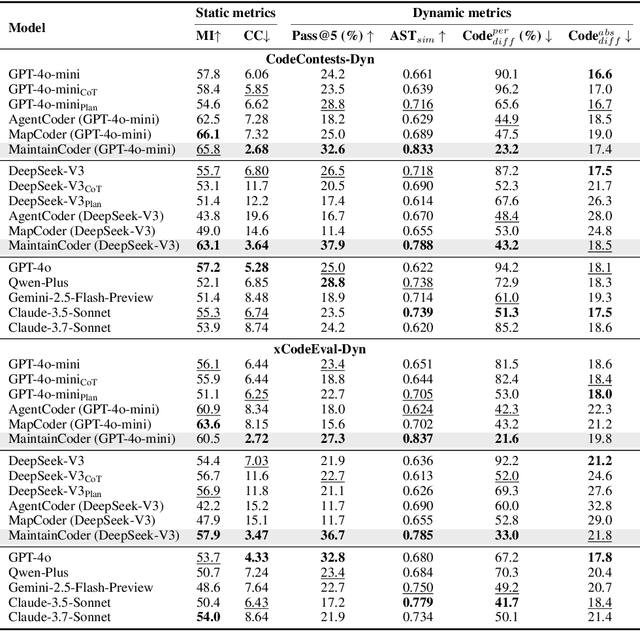
Modern code generation has made significant strides in functional correctness and execution efficiency. However, these systems often overlook a critical dimension in real-world software development: maintainability. To handle dynamic requirements with minimal rework, we propose MaintainCoder as a pioneering solution. It integrates Waterfall model, design patterns, and multi-agent collaboration to systematically enhance cohesion, reduce coupling, and improve adaptability. We also introduce MaintainBench, a benchmark comprising requirement changes and corresponding dynamic metrics on maintainance effort. Experiments demonstrate that existing code generation methods struggle to meet maintainability standards when requirements evolve. In contrast, MaintainCoder improves maintainability metrics by 14-30% with even higher correctness, i.e. pass@k. Our work not only provides the foundation of maintainable code generation, but also highlights the need for more holistic code quality research. Resources: https://github.com/IAAR-Shanghai/MaintainCoder.
RARE: Retrieval-Augmented Reasoning Modeling
Mar 30, 2025Domain-specific intelligence demands specialized knowledge and sophisticated reasoning for problem-solving, posing significant challenges for large language models (LLMs) that struggle with knowledge hallucination and inadequate reasoning capabilities under constrained parameter budgets. Inspired by Bloom's Taxonomy in educational theory, we propose Retrieval-Augmented Reasoning Modeling (RARE), a novel paradigm that decouples knowledge storage from reasoning optimization. RARE externalizes domain knowledge to retrievable sources and internalizes domain-specific reasoning patterns during training. Specifically, by injecting retrieved knowledge into training prompts, RARE transforms learning objectives from rote memorization to contextualized reasoning application. It enables models to bypass parameter-intensive memorization and prioritize the development of higher-order cognitive processes. Our experiments demonstrate that lightweight RARE-trained models (e.g., Llama-3.1-8B) could achieve state-of-the-art performance, surpassing retrieval-augmented GPT-4 and Deepseek-R1 distilled counterparts. RARE establishes a paradigm shift where maintainable external knowledge bases synergize with compact, reasoning-optimized models, collectively driving more scalable domain-specific intelligence. Repo: https://github.com/Open-DataFlow/RARE
HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation
Feb 18, 2025Retrieval-Augmented Generation (RAG) systems often struggle with imperfect retrieval, as traditional retrievers focus on lexical or semantic similarity rather than logical relevance. To address this, we propose HopRAG, a novel RAG framework that augments retrieval with logical reasoning through graph-structured knowledge exploration. During indexing, HopRAG constructs a passage graph, with text chunks as vertices and logical connections established via LLM-generated pseudo-queries as edges. During retrieval, it employs a retrieve-reason-prune mechanism: starting with lexically or semantically similar passages, the system explores multi-hop neighbors guided by pseudo-queries and LLM reasoning to identify truly relevant ones. Extensive experiments demonstrate HopRAG's superiority, achieving 76.78\% higher answer accuracy and 65.07\% improved retrieval F1 score compared to conventional methods. The repository is available at https://github.com/LIU-Hao-2002/HopRAG.
A Comprehensive Survey on Imbalanced Data Learning
Feb 13, 2025With the expansion of data availability, machine learning (ML) has achieved remarkable breakthroughs in both academia and industry. However, imbalanced data distributions are prevalent in various types of raw data and severely hinder the performance of ML by biasing the decision-making processes. To deepen the understanding of imbalanced data and facilitate the related research and applications, this survey systematically analyzing various real-world data formats and concludes existing researches for different data formats into four distinct categories: data re-balancing, feature representation, training strategy, and ensemble learning. This structured analysis help researchers comprehensively understand the pervasive nature of imbalance across diverse data format, thereby paving a clearer path toward achieving specific research goals. we provide an overview of relevant open-source libraries, spotlight current challenges, and offer novel insights aimed at fostering future advancements in this critical area of study.
MRAMG-Bench: A BeyondText Benchmark for Multimodal Retrieval-Augmented Multimodal Generation
Feb 06, 2025Recent advancements in Retrieval-Augmented Generation (RAG) have shown remarkable performance in enhancing response accuracy and relevance by integrating external knowledge into generative models. However, existing RAG methods primarily focus on providing text-only answers, even in multimodal retrieval-augmented generation scenarios. In this work, we introduce the Multimodal Retrieval-Augmented Multimodal Generation (MRAMG) task, which aims to generate answers that combine both text and images, fully leveraging the multimodal data within a corpus. Despite the importance of this task, there is a notable absence of a comprehensive benchmark to effectively evaluate MRAMG performance. To bridge this gap, we introduce the MRAMG-Bench, a carefully curated, human-annotated dataset comprising 4,346 documents, 14,190 images, and 4,800 QA pairs, sourced from three categories: Web Data, Academic Papers, and Lifestyle. The dataset incorporates diverse difficulty levels and complex multi-image scenarios, providing a robust foundation for evaluating multimodal generation tasks. To facilitate rigorous evaluation, our MRAMG-Bench incorporates a comprehensive suite of both statistical and LLM-based metrics, enabling a thorough analysis of the performance of popular generative models in the MRAMG task. Besides, we propose an efficient multimodal answer generation framework that leverages both LLMs and MLLMs to generate multimodal responses. Our datasets are available at: https://huggingface.co/MRAMG.