 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
Oct 29, 2024



Document parsing is essential for converting unstructured and semi-structured documents-such as contracts, academic papers, and invoices-into structured, machine-readable data. Document parsing extract reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation. This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models. Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail. Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It emphasizes the importance of developing larger and more diverse datasets and outlines future research directions.
PopAlign: Diversifying Contrasting Patterns for a More Comprehensive Alignment
Oct 17, 2024
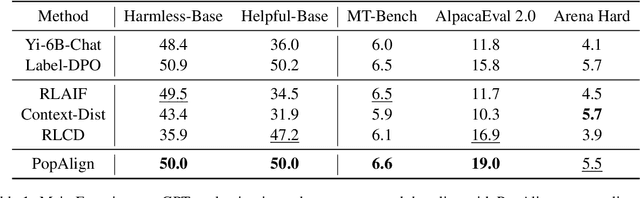

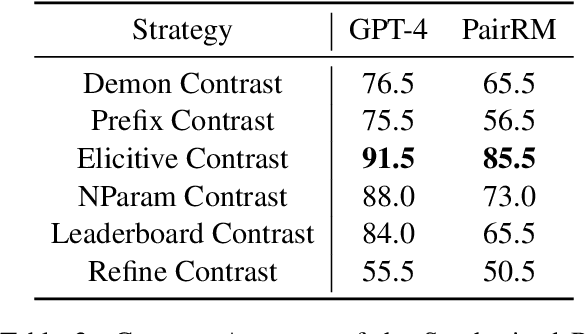
Alignment of large language models (LLMs) involves training models on preference-contrastive output pairs to adjust their responses according to human preferences. To obtain such contrastive pairs, traditional methods like RLHF and RLAIF rely on limited contrasting patterns, such as varying model variants or decoding temperatures. This singularity leads to two issues: (1) alignment is not comprehensive; and thereby (2) models are susceptible to jailbreaking attacks. To address these issues, we investigate how to construct more comprehensive and diversified contrasting patterns to enhance preference data (RQ1) and verify the impact of the diversification of contrasting patterns on model alignment (RQ2). For RQ1, we propose PopAlign, a framework that integrates diversified contrasting patterns across the prompt, model, and pipeline levels, introducing six contrasting strategies that do not require additional feedback labeling procedures. Regarding RQ2, we conduct thorough experiments demonstrating that PopAlign significantly outperforms existing methods, leading to more comprehensive alignment.