 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossEarth-SAR: A SAR-Centric and Billion-Scale Geospatial Foundation Model for Domain Generalizable Semantic Segmentation
Mar 12, 2026Synthetic Aperture Radar (SAR) enables global, all-weather earth observation. However, owing to diverse imaging mechanisms, domain shifts across sensors and regions severely hinder its semantic generalization. To address this, we present CrossEarth-SAR, the first billion-scale SAR vision foundation model built upon a novel physics-guided sparse mixture-of-experts (MoE) architecture incorporating physical descriptors, explicitly designed for cross-domain semantic segmentation. To facilitate large-scale pre-training, we develop CrossEarth-SAR-200K, a weakly and fully supervised dataset that unifies public and private SAR imagery. We also introduce a benchmark suite comprising 22 sub-benchmarks across 8 distinct domain gaps, establishing the first unified standard for domain generalization semantic segmentation on SAR imagery. Extensive experiments demonstrate that CrossEarth-SAR achieves state-of-the-art results on 20 benchmarks, surpassing previous methods by over 10\% mIoU on some benchmarks under multi-gap transfer. All code, benchmark and datasets will be publicly available.
EvoTok: A Unified Image Tokenizer via Residual Latent Evolution for Visual Understanding and Generation
Mar 12, 2026The development of unified multimodal large language models (MLLMs) is fundamentally challenged by the granularity gap between visual understanding and generation: understanding requires high-level semantic abstractions, while image generation demands fine-grained pixel-level representations. Existing approaches usually enforce the two supervision on the same set of representation or decouple these two supervision on separate feature spaces, leading to interference and inconsistency, respectively. In this work, we propose EvoTok, a unified image tokenizer that reconciles these requirements through a residual evolution process within a shared latent space. Instead of maintaining separate token spaces for pixels and semantics, EvoTok encodes an image into a cascaded sequence of residual tokens via residual vector quantization. This residual sequence forms an evolution trajectory where earlier stages capture low-level details and deeper stages progressively transition toward high-level semantic representations. Despite being trained on a relatively modest dataset of 13M images, far smaller than the billion-scale datasets used by many previous unified tokenizers, EvoTok achieves a strong reconstruction quality of 0.43 rFID on ImageNet-1K at 256x256 resolution. When integrated with a large language model, EvoTok shows promising performance across 7 out of 9 visual understanding benchmarks, and remarkable results on image generation benchmarks such as GenEval and GenAI-Bench. These results demonstrate that modeling visual representations as an evolving trajectory provides an effective and principled solution for unifying visual understanding and generation.
AutoAgent: Evolving Cognition and Elastic Memory Orchestration for Adaptive Agents
Mar 10, 2026Autonomous agent frameworks still struggle to reconcile long-term experiential learning with real-time, context-sensitive decision-making. In practice, this gap appears as static cognition, rigid workflow dependence, and inefficient context usage, which jointly limit adaptability in open-ended and non-stationary environments. To address these limitations, we present AutoAgent, a self-evolving multi-agent framework built on three tightly coupled components: evolving cognition, on-the-fly contextual decision-making, and elastic memory orchestration. At the core of AutoAgent, each agent maintains structured prompt-level cognition over tools, self-capabilities, peer expertise, and task knowledge. During execution, this cognition is combined with live task context to select actions from a unified space that includes tool calls, LLM-based generation, and inter-agent requests. To support efficient long-horizon reasoning, an Elastic Memory Orchestrator dynamically organizes interaction history by preserving raw records, compressing redundant trajectories, and constructing reusable episodic abstractions, thereby reducing token overhead while retaining decision-critical evidence. These components are integrated through a closed-loop cognitive evolution process that aligns intended actions with observed outcomes to continuously update cognition and expand reusable skills, without external retraining. Empirical results across retrieval-augmented reasoning, tool-augmented agent benchmarks, and embodied task environments show that AutoAgent consistently improves task success, tool-use efficiency, and collaborative robustness over static and memory-augmented baselines. Overall, AutoAgent provides a unified and practical foundation for adaptive autonomous agents that must learn from experience while making reliable context-aware decisions in dynamic environments.
FineRMoE: Dimension Expansion for Finer-Grained Expert with Its Upcycling Approach
Mar 09, 2026As revealed by the scaling law of fine-grained MoE, model performance ceases to be improved once the granularity of the intermediate dimension exceeds the optimal threshold, limiting further gains from single-dimension fine-grained design. To address this bottleneck, we propose FineRMoE (FineR-Grained MoE), an architecture that extends fine-grained expert design to both intermediate and output dimensions, aiming to enhance expert specialization beyond the single-dimension limit. We further introduce a bi-level sparse forward computation paradigm and a specialized routing mechanism to govern the activation. In addition, to obviate the prohibitive cost of training FineRMoE from scratch, we devise a generalized upcycling method to build FineRMoE in a cost-effective manner. Extensive experiments demonstrate the superior performance achieved by FineRMoE across ten standard benchmarks. Compared with the strongest baseline, FineRMoE achieves 6 times higher parameter efficiency, 281 times lower prefill latency, and 136 timese higher decoding throughput during inference.
HELP: HyperNode Expansion and Logical Path-Guided Evidence Localization for Accurate and Efficient GraphRAG
Feb 24, 2026Large Language Models (LLMs) often struggle with inherent knowledge boundaries and hallucinations, limiting their reliability in knowledge-intensive tasks. While Retrieval-Augmented Generation (RAG) mitigates these issues, it frequently overlooks structural interdependencies essential for multi-hop reasoning. Graph-based RAG approaches attempt to bridge this gap, yet they typically face trade-offs between accuracy and efficiency due to challenges such as costly graph traversals and semantic noise in LLM-generated summaries. In this paper, we propose HyperNode Expansion and Logical Path-Guided Evidence Localization strategies for GraphRAG (HELP), a novel framework designed to balance accuracy with practical efficiency through two core strategies: 1) HyperNode Expansion, which iteratively chains knowledge triplets into coherent reasoning paths abstracted as HyperNodes to capture complex structural dependencies and ensure retrieval accuracy; and 2) Logical Path-Guided Evidence Localization, which leverages precomputed graph-text correlations to map these paths directly to the corpus for superior efficiency. HELP avoids expensive random walks and semantic distortion, preserving knowledge integrity while drastically reducing retrieval latency. Extensive experiments demonstrate that HELP achieves competitive performance across multiple simple and multi-hop QA benchmarks and up to a 28.8$\times$ speedup over leading Graph-based RAG baselines.
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
Repulsor: Accelerating Generative Modeling with a Contrastive Memory Bank
Dec 13, 2025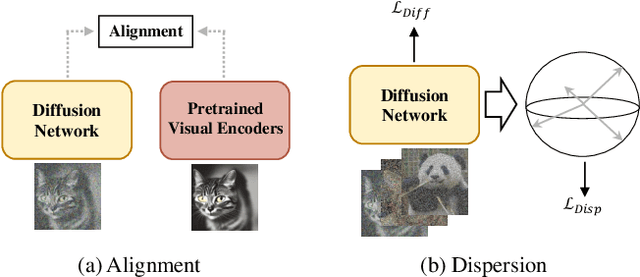
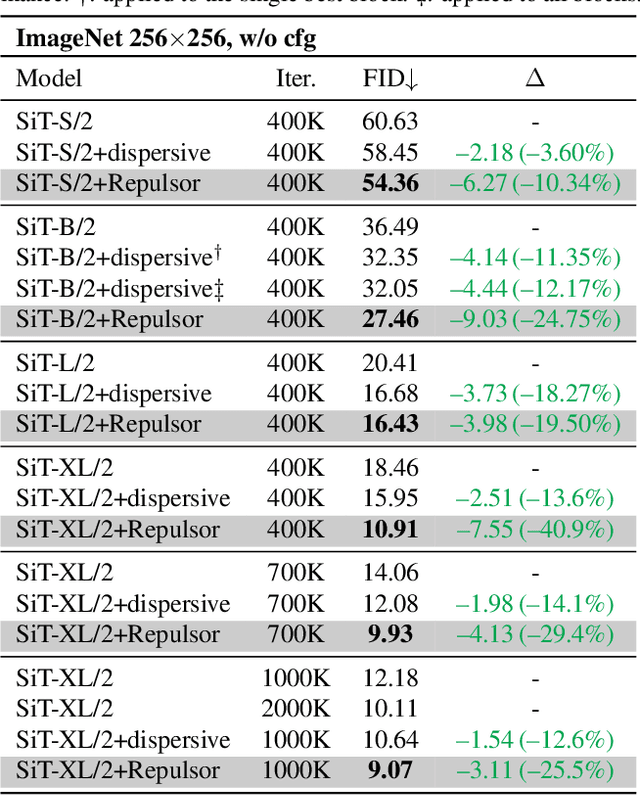
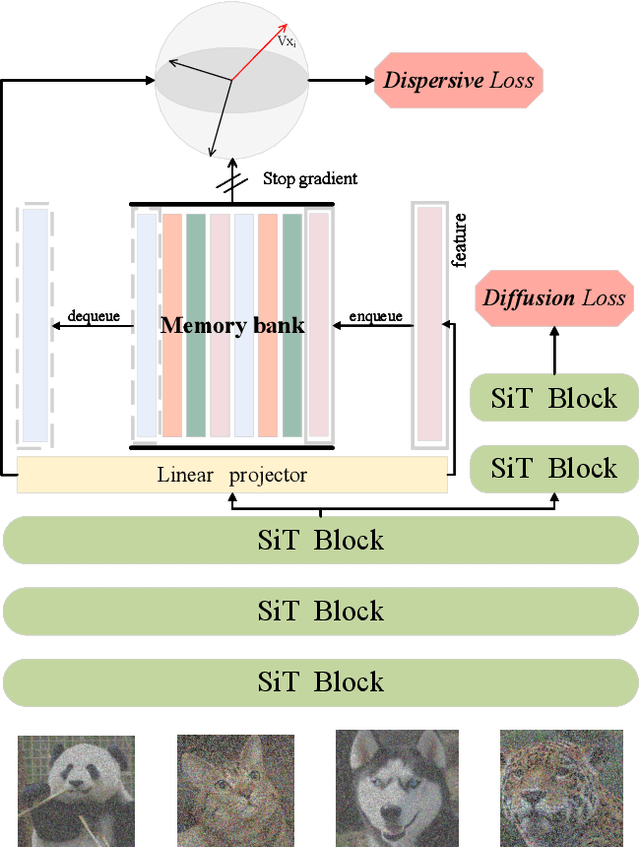

The dominance of denoising generative models (e.g., diffusion, flow-matching) in visual synthesis is tempered by their substantial training costs and inefficiencies in representation learning. While injecting discriminative representations via auxiliary alignment has proven effective, this approach still faces key limitations: the reliance on external, pre-trained encoders introduces overhead and domain shift. A dispersed-based strategy that encourages strong separation among in-batch latent representations alleviates this specific dependency. To assess the effect of the number of negative samples in generative modeling, we propose {\mname}, a plug-and-play training framework that requires no external encoders. Our method integrates a memory bank mechanism that maintains a large, dynamically updated queue of negative samples across training iterations. This decouples the number of negatives from the mini-batch size, providing abundant and high-quality negatives for a contrastive objective without a multiplicative increase in computational cost. A low-dimensional projection head is used to further minimize memory and bandwidth overhead. {\mname} offers three principal advantages: (1) it is self-contained, eliminating dependency on pretrained vision foundation models and their associated forward-pass overhead; (2) it introduces no additional parameters or computational cost during inference; and (3) it enables substantially faster convergence, achieving superior generative quality more efficiently. On ImageNet-256, {\mname} achieves a state-of-the-art FID of \textbf{2.40} within 400k steps, significantly outperforming comparable methods.
GRAPHMOE: Amplifying Cognitive Depth of Mixture-of-Experts Network via Introducing Self-Rethinking Mechanism
Jan 14, 2025



Traditional Mixture-of-Experts (MoE) networks benefit from utilizing multiple smaller expert models as opposed to a single large network. However, these experts typically operate independently, leaving a question open about whether interconnecting these models could enhance the performance of MoE networks. In response, we introduce GRAPHMOE, a novel method aimed at augmenting the cognitive depth of language models via a self-rethinking mechanism constructed on Pseudo GraphMoE networks. GRAPHMOE employs a recurrent routing strategy to simulate iterative thinking steps, thereby facilitating the flow of information among expert nodes. We implement the GRAPHMOE architecture using Low-Rank Adaptation techniques (LoRA) and conduct extensive experiments on various benchmark datasets. The experimental results reveal that GRAPHMOE outperforms other LoRA based models, achieving state-of-the-art (SOTA) performance. Additionally, this study explores a novel recurrent routing strategy that may inspire further advancements in enhancing the reasoning capabilities of language models.
Modeling All Response Surfaces in One for Conditional Search Spaces
Jan 08, 2025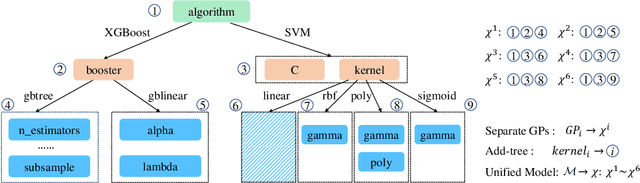
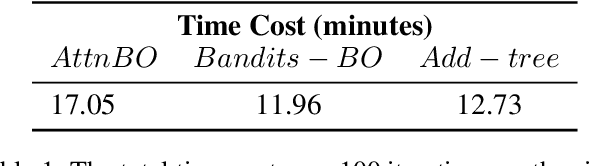
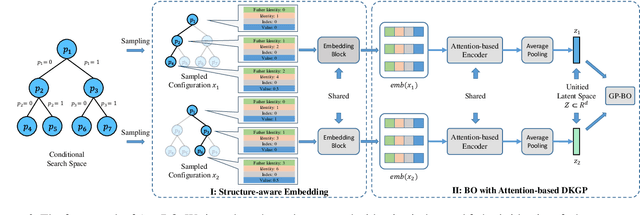
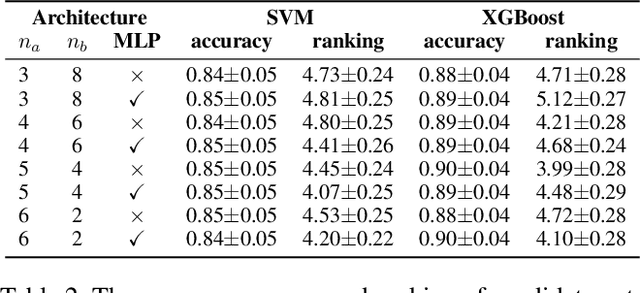
Bayesian Optimization (BO) is a sample-efficient black-box optimizer commonly used in search spaces where hyperparameters are independent. However, in many practical AutoML scenarios, there will be dependencies among hyperparameters, forming a conditional search space, which can be partitioned into structurally distinct subspaces. The structure and dimensionality of hyperparameter configurations vary across these subspaces, challenging the application of BO. Some previous BO works have proposed solutions to develop multiple Gaussian Process models in these subspaces. However, these approaches tend to be inefficient as they require a substantial number of observations to guarantee each GP's performance and cannot capture relationships between hyperparameters across different subspaces. To address these issues, this paper proposes a novel approach to model the response surfaces of all subspaces in one, which can model the relationships between hyperparameters elegantly via a self-attention mechanism. Concretely, we design a structure-aware hyperparameter embedding to preserve the structural information. Then, we introduce an attention-based deep feature extractor, capable of projecting configurations with different structures from various subspaces into a unified feature space, where the response surfaces can be formulated using a single standard Gaussian Process. The empirical results on a simulation function, various real-world tasks, and HPO-B benchmark demonstrate that our proposed approach improves the efficacy and efficiency of BO within conditional search spaces.
QAEncoder: Towards Aligned Representation Learning in Question Answering System
Sep 30, 2024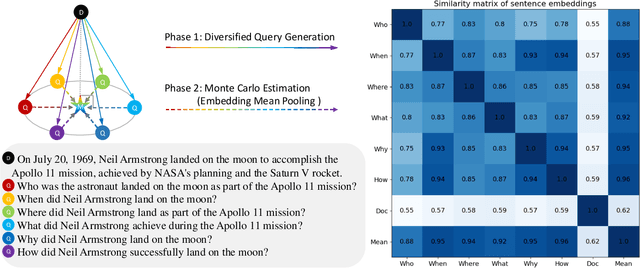
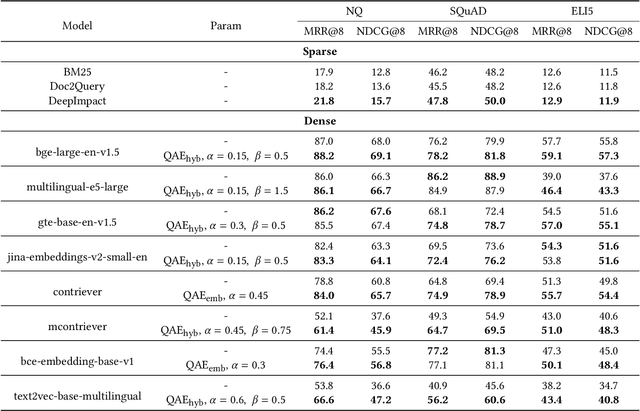
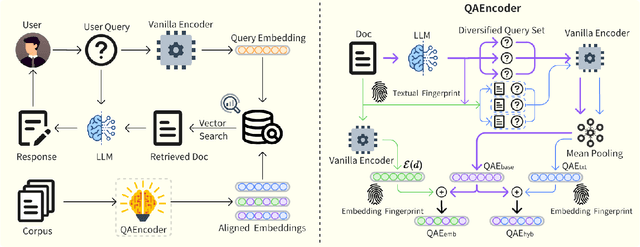
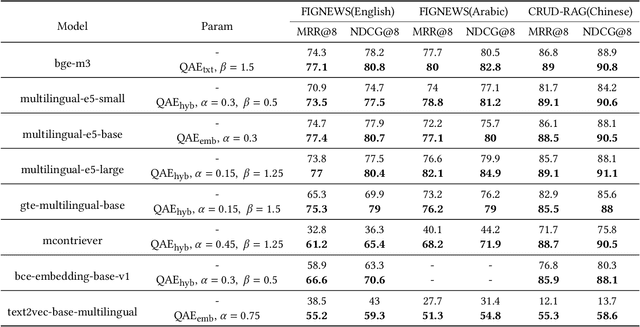
Modern QA systems entail retrieval-augmented generation (RAG) for accurate and trustworthy responses. However, the inherent gap between user queries and relevant documents hinders precise matching. Motivated by our conical distribution hypothesis, which posits that potential queries and documents form a cone-like structure in the embedding space, we introduce QAEncoder, a training-free approach to bridge this gap. Specifically, QAEncoder estimates the expectation of potential queries in the embedding space as a robust surrogate for the document embedding, and attaches document fingerprints to effectively distinguish these embeddings. Extensive experiments on fourteen embedding models across six languages and eight datasets validate QAEncoder's alignment capability, which offers a plug-and-play solution that seamlessly integrates with existing RAG architectures and training-based methods.