 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Understanding Parameter Sharing in Transformers
Jun 15, 2023

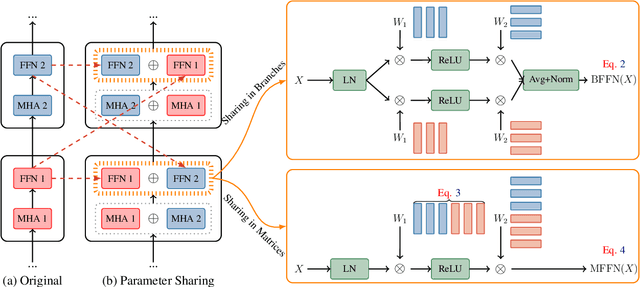

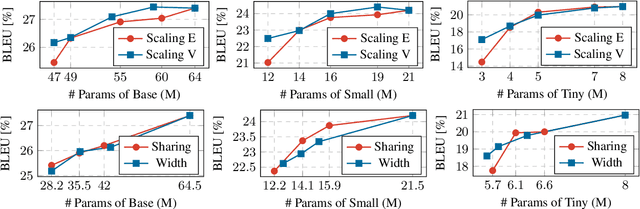
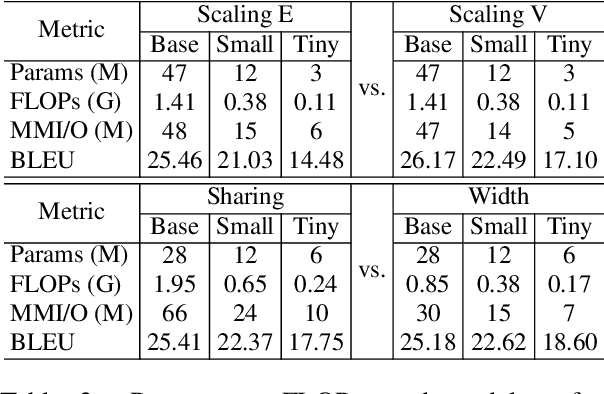
Parameter sharing has proven to be a parameter-efficient approach. Previous work on Transformers has focused on sharing parameters in different layers, which can improve the performance of models with limited parameters by increasing model depth. In this paper, we study why this approach works from two perspectives. First, increasing model depth makes the model more complex, and we hypothesize that the reason is related to model complexity (referring to FLOPs). Secondly, since each shared parameter will participate in the network computation several times in forward propagation, its corresponding gradient will have a different range of values from the original model, which will affect the model convergence. Based on this, we hypothesize that training convergence may also be one of the reasons. Through further analysis, we show that the success of this approach can be largely attributed to better convergence, with only a small part due to the increased model complexity. Inspired by this, we tune the training hyperparameters related to model convergence in a targeted manner. Experiments on 8 machine translation tasks show that our model achieves competitive performance with only half the model complexity of parameter sharing models.
MobileNMT: Enabling Translation in 15MB and 30ms
Jun 07, 2023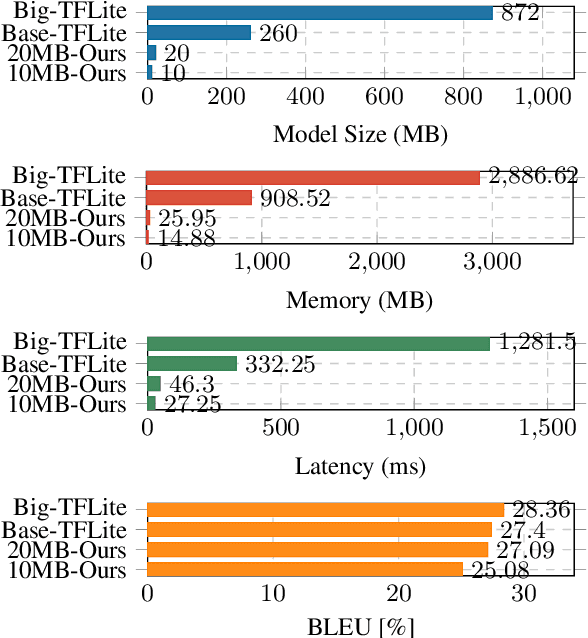
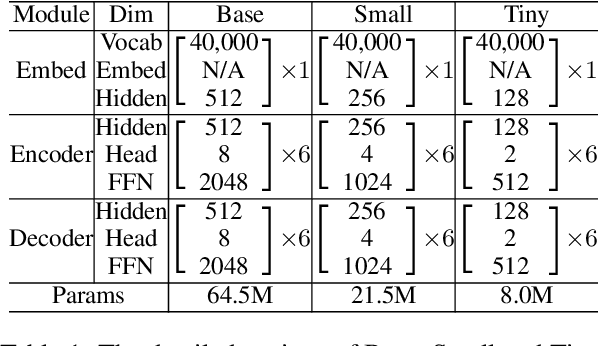
Deploying NMT models on mobile devices is essential for privacy, low latency, and offline scenarios. For high model capacity, NMT models are rather large. Running these models on devices is challenging with limited storage, memory, computation, and power consumption. Existing work either only focuses on a single metric such as FLOPs or general engine which is not good at auto-regressive decoding. In this paper, we present MobileNMT, a system that can translate in 15MB and 30ms on devices. We propose a series of principles for model compression when combined with quantization. Further, we implement an engine that is friendly to INT8 and decoding. With the co-design of model and engine, compared with the existing system, we speed up 47.0x and save 99.5% of memory with only 11.6% loss of BLEU. The code is publicly available at https://github.com/zjersey/Lightseq-ARM.
PARAGEN : A Parallel Generation Toolkit
Oct 07, 2022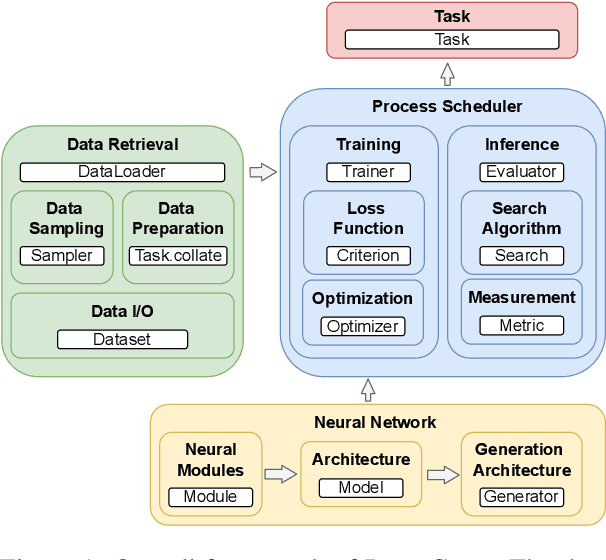

PARAGEN is a PyTorch-based NLP toolkit for further development on parallel generation. PARAGEN provides thirteen types of customizable plugins, helping users to experiment quickly with novel ideas across model architectures, optimization, and learning strategies. We implement various features, such as unlimited data loading and automatic model selection, to enhance its industrial usage. ParaGen is now deployed to support various research and industry applications at ByteDance. PARAGEN is available at https://github.com/bytedance/ParaGen.
ROME: Robustifying Memory-Efficient NAS via Topology Disentanglement and Gradients Accumulation
Nov 23, 2020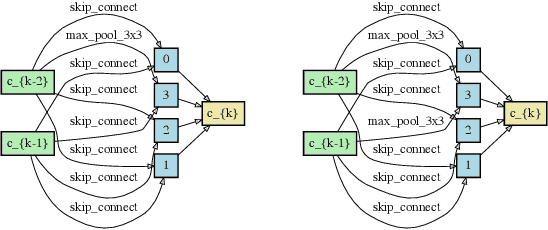


Single-path based differentiable neural architecture search has great strengths for its low computational cost and memory-friendly nature. However, we surprisingly discover that it suffers from severe searching instability which has been primarily ignored, posing a potential weakness for a wider application. In this paper, we delve into its performance collapse issue and propose a new algorithm called RObustifying Memory-Efficient NAS (ROME). Specifically, 1) for consistent topology in the search and evaluation stage, we involve separate parameters to disentangle the topology from the operations of the architecture. In such a way, we can independently sample connections and operations without interference; 2) to discount sampling unfairness and variance, we enforce fair sampling for weight update and apply a gradient accumulation mechanism for architecture parameters. Extensive experiments demonstrate that our proposed method has strong performance and robustness, where it mostly achieves state-of-the-art results on a large number of standard benchmarks.