 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Parameter Sharing in Transformers
Paper and Code


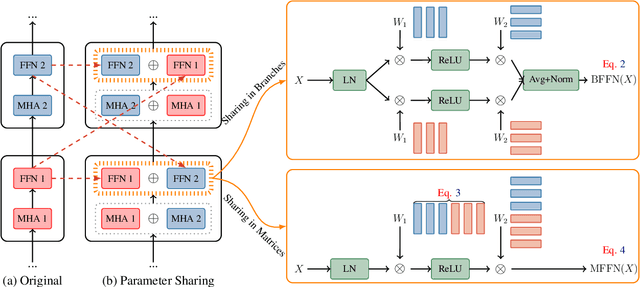

Parameter sharing has proven to be a parameter-efficient approach. Previous work on Transformers has focused on sharing parameters in different layers, which can improve the performance of models with limited parameters by increasing model depth. In this paper, we study why this approach works from two perspectives. First, increasing model depth makes the model more complex, and we hypothesize that the reason is related to model complexity (referring to FLOPs). Secondly, since each shared parameter will participate in the network computation several times in forward propagation, its corresponding gradient will have a different range of values from the original model, which will affect the model convergence. Based on this, we hypothesize that training convergence may also be one of the reasons. Through further analysis, we show that the success of this approach can be largely attributed to better convergence, with only a small part due to the increased model complexity. Inspired by this, we tune the training hyperparameters related to model convergence in a targeted manner. Experiments on 8 machine translation tasks show that our model achieves competitive performance with only half the model complexity of parameter sharing models.