 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoleCDE:Benchmarking and Mitigating Role-Alignment Trade-offs in Role-Playing Agents
Jun 01, 2026Role-playing agents(RPAs) are widely used to steer large language models(LLMs) toward role-consistent behavior, yet existing benchmarks mainly evaluate surface-level fidelity and offer limited insight into decision making under role-alignment value conflicts. To address this gap, we introduce RoleCDE, the first benchmark designed to evaluate RPAs under structured conflicts between role-specific values and alignment-oriented constraints. RoleCDE formulates role-aware decision making as cognitive dilemma scenarios, jointly evaluating role-scenario grounding, value conflict resolution, and decision tendencies. The benchmark is constructed at scale, covering approximately 8k diverse role profiles and scenarios and nearly 24k dilemma instances across three difficulty levels and eight role categories. Evaluation of several mainstream LLMs reveals a "Role Value Decoupling" phenomenon, where agents systematically default to alignment-and morality-consistent decisions rather than role-specific values when the two conflict, even under explicit role conditioning. This behavior is largely invariant to dilemma difficulty but varies substantially across role categories. We further show that RoleCDE-based fine-tuning effectively mitigates this decoupling by improving value trade-off reasoning, while preserving general role-playing fidelity and general reasoning performance. Code is available at: https://github.com/rabbitrose/RoleCDE.
UniCreative: Unifying Long-form Logic and Short-form Sparkle via Reference-Free Reinforcement Learning
Apr 07, 2026A fundamental challenge in creative writing lies in reconciling the inherent tension between maintaining global coherence in long-form narratives and preserving local expressiveness in short-form texts. While long-context generation necessitates explicit macroscopic planning, short-form creativity often demands spontaneous, constraint-free expression. Existing alignment paradigms, however, typically employ static reward signals and rely heavily on high-quality supervised data, which is costly and difficult to scale. To address this, we propose \textbf{UniCreative}, a unified reference-free reinforcement learning framework. We first introduce \textbf{AC-GenRM}, an adaptive constraint-aware reward model that dynamically synthesizes query-specific criteria to provide fine-grained preference judgments. Leveraging these signals, we propose \textbf{ACPO}, a policy optimization algorithm that aligns models with human preferences across both content quality and structural paradigms without supervised fine-tuning and ground-truth references. Empirical results demonstrate that AC-GenRM aligns closely with expert evaluations, while ACPO significantly enhances performance across diverse writing tasks. Crucially, our analysis reveals an emergent meta-cognitive ability: the model learns to autonomously differentiate between tasks requiring rigorous planning and those favoring direct generation, validating the effectiveness of our direct alignment approach.
HaluMem: Evaluating Hallucinations in Memory Systems of Agents
Nov 05, 2025Memory systems are key components that enable AI systems such as LLMs and AI agents to achieve long-term learning and sustained interaction. However, during memory storage and retrieval, these systems frequently exhibit memory hallucinations, including fabrication, errors, conflicts, and omissions. Existing evaluations of memory hallucinations are primarily end-to-end question answering, which makes it difficult to localize the operational stage within the memory system where hallucinations arise. To address this, we introduce the Hallucination in Memory Benchmark (HaluMem), the first operation level hallucination evaluation benchmark tailored to memory systems. HaluMem defines three evaluation tasks (memory extraction, memory updating, and memory question answering) to comprehensively reveal hallucination behaviors across different operational stages of interaction. To support evaluation, we construct user-centric, multi-turn human-AI interaction datasets, HaluMem-Medium and HaluMem-Long. Both include about 15k memory points and 3.5k multi-type questions. The average dialogue length per user reaches 1.5k and 2.6k turns, with context lengths exceeding 1M tokens, enabling evaluation of hallucinations across different context scales and task complexities. Empirical studies based on HaluMem show that existing memory systems tend to generate and accumulate hallucinations during the extraction and updating stages, which subsequently propagate errors to the question answering stage. Future research should focus on developing interpretable and constrained memory operation mechanisms that systematically suppress hallucinations and improve memory reliability.
MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Oct 16, 2025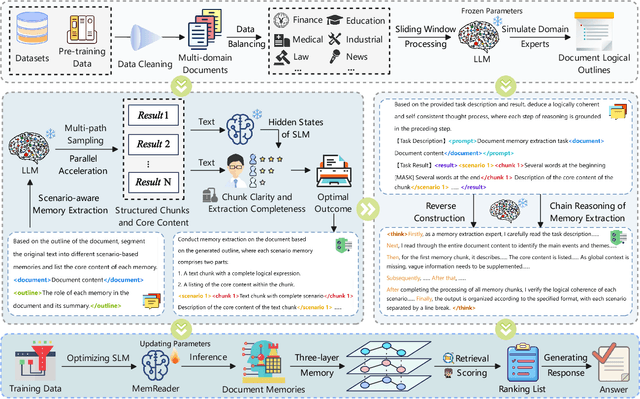
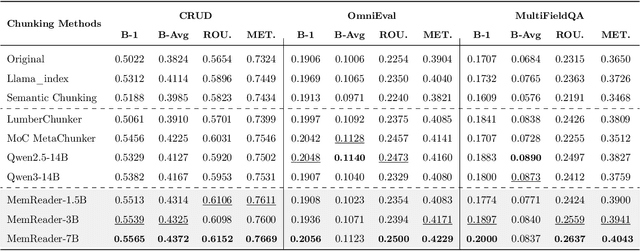
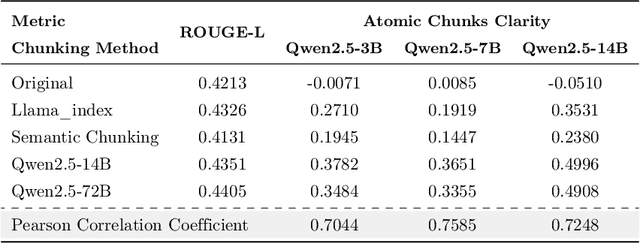
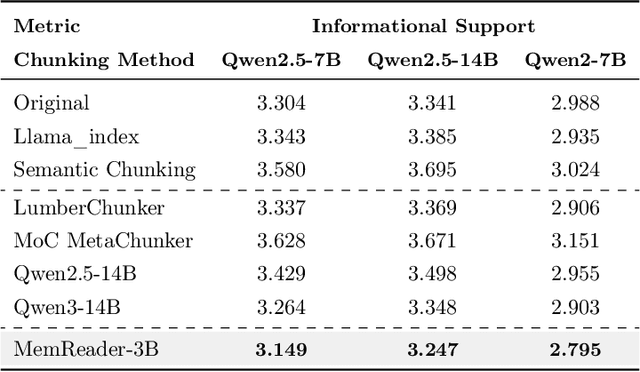
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025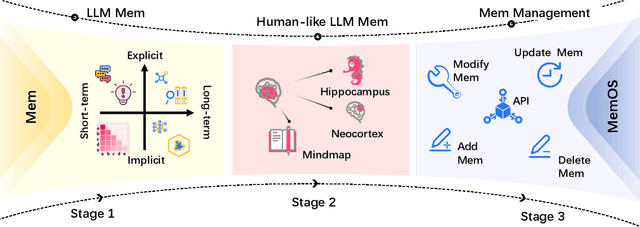
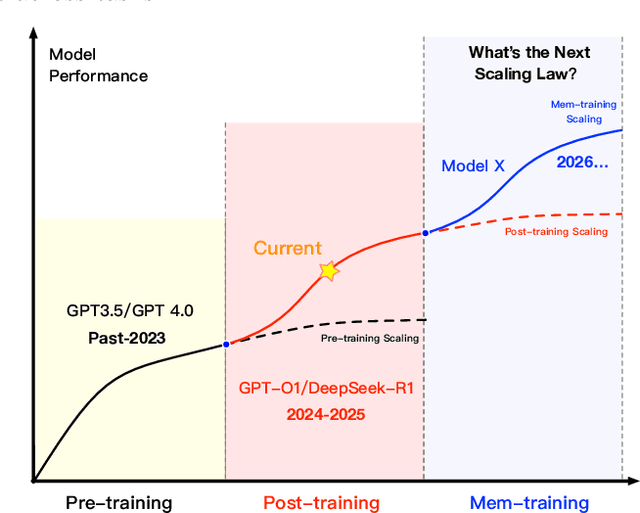
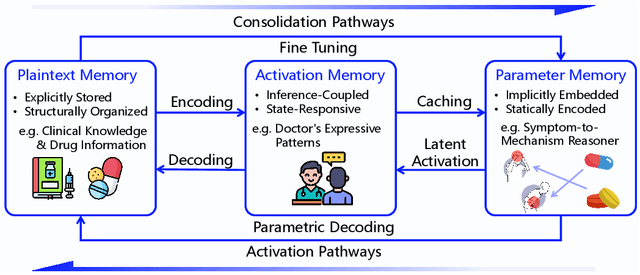
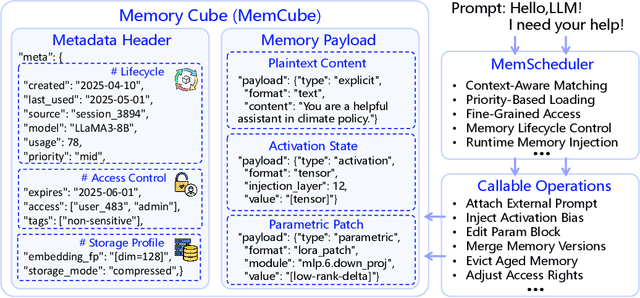
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
GuessArena: Guess Who I Am? A Self-Adaptive Framework for Evaluating LLMs in Domain-Specific Knowledge and Reasoning
May 28, 2025The evaluation of large language models (LLMs) has traditionally relied on static benchmarks, a paradigm that poses two major limitations: (1) predefined test sets lack adaptability to diverse application domains, and (2) standardized evaluation protocols often fail to capture fine-grained assessments of domain-specific knowledge and contextual reasoning abilities. To overcome these challenges, we propose GuessArena, an adaptive evaluation framework grounded in adversarial game-based interactions. Inspired by the interactive structure of the Guess Who I Am? game, our framework seamlessly integrates dynamic domain knowledge modeling with progressive reasoning assessment to improve evaluation fidelity. Empirical studies across five vertical domains-finance, healthcare, manufacturing, information technology, and education-demonstrate that GuessArena effectively distinguishes LLMs in terms of domain knowledge coverage and reasoning chain completeness. Compared to conventional benchmarks, our method provides substantial advantages in interpretability, scalability, and scenario adaptability.
MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
Mar 12, 2025



Retrieval-Augmented Generation (RAG), while serving as a viable complement to large language models (LLMs), often overlooks the crucial aspect of text chunking within its pipeline. This paper initially introduces a dual-metric evaluation method, comprising Boundary Clarity and Chunk Stickiness, to enable the direct quantification of chunking quality. Leveraging this assessment method, we highlight the inherent limitations of traditional and semantic chunking in handling complex contextual nuances, thereby substantiating the necessity of integrating LLMs into chunking process. To address the inherent trade-off between computational efficiency and chunking precision in LLM-based approaches, we devise the granularity-aware Mixture-of-Chunkers (MoC) framework, which consists of a three-stage processing mechanism. Notably, our objective is to guide the chunker towards generating a structured list of chunking regular expressions, which are subsequently employed to extract chunks from the original text. Extensive experiments demonstrate that both our proposed metrics and the MoC framework effectively settle challenges of the chunking task, revealing the chunking kernel while enhancing the performance of the RAG system.
SEAP: Training-free Sparse Expert Activation Pruning Unlock the Brainpower of Large Language Models
Mar 10, 2025



Large Language Models have achieved remarkable success across various natural language processing tasks, yet their high computational cost during inference remains a major bottleneck. This paper introduces Sparse Expert Activation Pruning (SEAP), a training-free pruning method that selectively retains task-relevant parameters to reduce inference overhead. Inspired by the clustering patterns of hidden states and activations in LLMs, SEAP identifies task-specific expert activation patterns and prunes the model while preserving task performance and enhancing computational efficiency. Experimental results demonstrate that SEAP significantly reduces computational overhead while maintaining competitive accuracy. Notably, at 50% pruning, SEAP surpasses both WandA and FLAP by over 20%, and at 20% pruning, it incurs only a 2.2% performance drop compared to the dense model. These findings highlight SEAP's scalability and effectiveness, making it a promising approach for optimizing large-scale LLMs.
SurveyX: Academic Survey Automation via Large Language Models
Feb 20, 2025Large Language Models (LLMs) have demonstrated exceptional comprehension capabilities and a vast knowledge base, suggesting that LLMs can serve as efficient tools for automated survey generation. However, recent research related to automated survey generation remains constrained by some critical limitations like finite context window, lack of in-depth content discussion, and absence of systematic evaluation frameworks. Inspired by human writing processes, we propose SurveyX, an efficient and organized system for automated survey generation that decomposes the survey composing process into two phases: the Preparation and Generation phases. By innovatively introducing online reference retrieval, a pre-processing method called AttributeTree, and a re-polishing process, SurveyX significantly enhances the efficacy of survey composition. Experimental evaluation results show that SurveyX outperforms existing automated survey generation systems in content quality (0.259 improvement) and citation quality (1.76 enhancement), approaching human expert performance across multiple evaluation dimensions. Examples of surveys generated by SurveyX are available on www.surveyx.cn
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Jan 28, 2025The indexing-retrieval-generation paradigm of retrieval-augmented generation (RAG) has been highly successful in solving knowledge-intensive tasks by integrating external knowledge into large language models (LLMs). However, the incorporation of external and unverified knowledge increases the vulnerability of LLMs because attackers can perform attack tasks by manipulating knowledge. In this paper, we introduce a benchmark named SafeRAG designed to evaluate the RAG security. First, we classify attack tasks into silver noise, inter-context conflict, soft ad, and white Denial-of-Service. Next, we construct RAG security evaluation dataset (i.e., SafeRAG dataset) primarily manually for each task. We then utilize the SafeRAG dataset to simulate various attack scenarios that RAG may encounter. Experiments conducted on 14 representative RAG components demonstrate that RAG exhibits significant vulnerability to all attack tasks and even the most apparent attack task can easily bypass existing retrievers, filters, or advanced LLMs, resulting in the degradation of RAG service quality. Code is available at: https://github.com/IAAR-Shanghai/SafeRAG.