 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Jan 28, 2025The indexing-retrieval-generation paradigm of retrieval-augmented generation (RAG) has been highly successful in solving knowledge-intensive tasks by integrating external knowledge into large language models (LLMs). However, the incorporation of external and unverified knowledge increases the vulnerability of LLMs because attackers can perform attack tasks by manipulating knowledge. In this paper, we introduce a benchmark named SafeRAG designed to evaluate the RAG security. First, we classify attack tasks into silver noise, inter-context conflict, soft ad, and white Denial-of-Service. Next, we construct RAG security evaluation dataset (i.e., SafeRAG dataset) primarily manually for each task. We then utilize the SafeRAG dataset to simulate various attack scenarios that RAG may encounter. Experiments conducted on 14 representative RAG components demonstrate that RAG exhibits significant vulnerability to all attack tasks and even the most apparent attack task can easily bypass existing retrievers, filters, or advanced LLMs, resulting in the degradation of RAG service quality. Code is available at: https://github.com/IAAR-Shanghai/SafeRAG.
LaDTalk: Latent Denoising for Synthesizing Talking Head Videos with High Frequency Details
Oct 01, 2024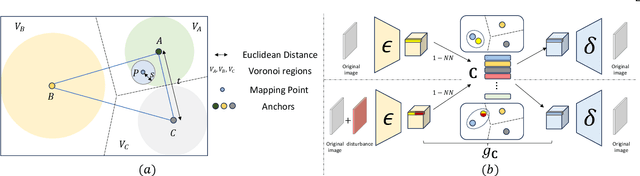
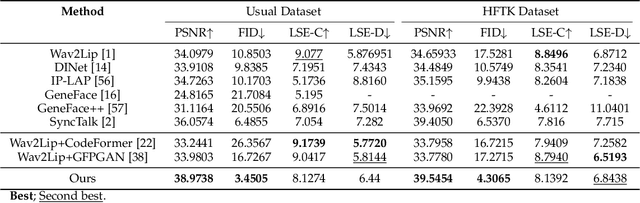


Audio-driven talking head generation is a pivotal area within film-making and Virtual Reality. Although existing methods have made significant strides following the end-to-end paradigm, they still encounter challenges in producing videos with high-frequency details due to their limited expressivity in this domain. This limitation has prompted us to explore an effective post-processing approach to synthesize photo-realistic talking head videos. Specifically, we employ a pretrained Wav2Lip model as our foundation model, leveraging its robust audio-lip alignment capabilities. Drawing on the theory of Lipschitz Continuity, we have theoretically established the noise robustness of Vector Quantised Auto Encoders (VQAEs). Our experiments further demonstrate that the high-frequency texture deficiency of the foundation model can be temporally consistently recovered by the Space-Optimised Vector Quantised Auto Encoder (SOVQAE) we introduced, thereby facilitating the creation of realistic talking head videos. We conduct experiments on both the conventional dataset and the High-Frequency TalKing head (HFTK) dataset that we curated. The results indicate that our method, LaDTalk, achieves new state-of-the-art video quality and out-of-domain lip synchronization performance.