 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaDTalk: Latent Denoising for Synthesizing Talking Head Videos with High Frequency Details
Paper and Code
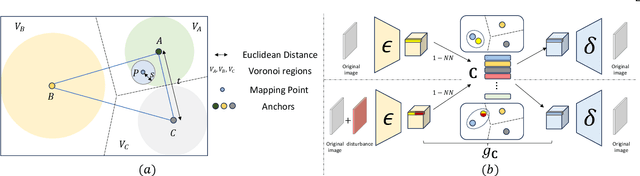
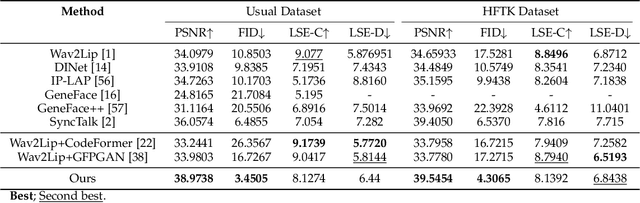


Audio-driven talking head generation is a pivotal area within film-making and Virtual Reality. Although existing methods have made significant strides following the end-to-end paradigm, they still encounter challenges in producing videos with high-frequency details due to their limited expressivity in this domain. This limitation has prompted us to explore an effective post-processing approach to synthesize photo-realistic talking head videos. Specifically, we employ a pretrained Wav2Lip model as our foundation model, leveraging its robust audio-lip alignment capabilities. Drawing on the theory of Lipschitz Continuity, we have theoretically established the noise robustness of Vector Quantised Auto Encoders (VQAEs). Our experiments further demonstrate that the high-frequency texture deficiency of the foundation model can be temporally consistently recovered by the Space-Optimised Vector Quantised Auto Encoder (SOVQAE) we introduced, thereby facilitating the creation of realistic talking head videos. We conduct experiments on both the conventional dataset and the High-Frequency TalKing head (HFTK) dataset that we curated. The results indicate that our method, LaDTalk, achieves new state-of-the-art video quality and out-of-domain lip synchronization performance.