 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELIC: Evaluating Compositional Instruction Following via Language Recognition
Jun 05, 2025Large language models (LLMs) are increasingly expected to perform tasks based only on a specification of the task provided in context, without examples of inputs and outputs; this ability is referred to as instruction following. We introduce the Recognition of Languages In-Context (RELIC) framework to evaluate instruction following using language recognition: the task of determining if a string is generated by formal grammar. Unlike many standard evaluations of LLMs' ability to use their context, this task requires composing together a large number of instructions (grammar productions) retrieved from the context. Because the languages are synthetic, the task can be increased in complexity as LLMs' skills improve, and new instances can be automatically generated, mitigating data contamination. We evaluate state-of-the-art LLMs on RELIC and find that their accuracy can be reliably predicted from the complexity of the grammar and the individual example strings, and that even the most advanced LLMs currently available show near-chance performance on more complex grammars and samples, in line with theoretical expectations. We also use RELIC to diagnose how LLMs attempt to solve increasingly difficult reasoning tasks, finding that as the complexity of the language recognition task increases, models switch to relying on shallow heuristics instead of following complex instructions.
High-Quality 3D Head Reconstruction from Any Single Portrait Image
Mar 11, 2025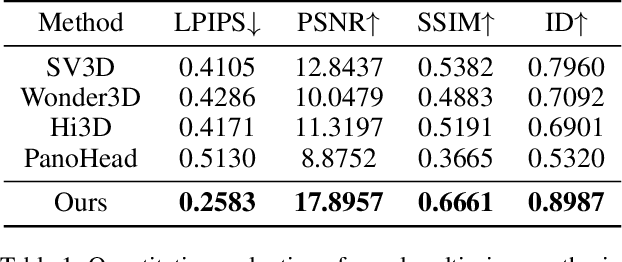
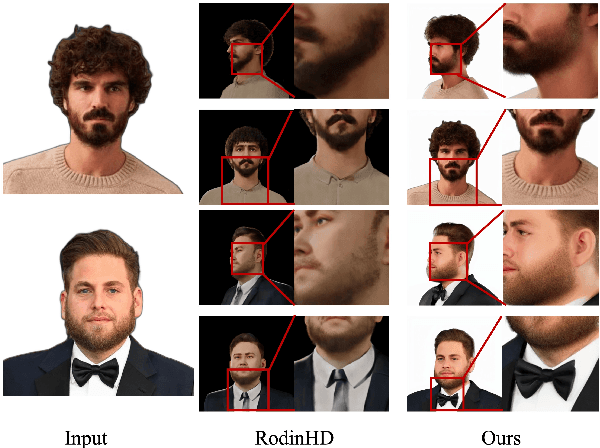
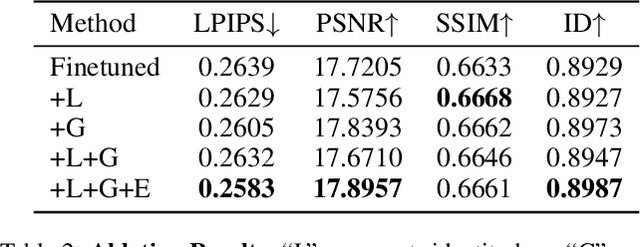
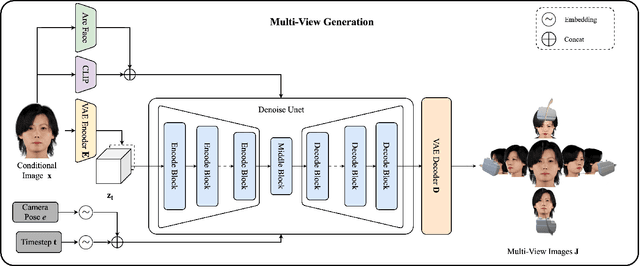
In this work, we introduce a novel high-fidelity 3D head reconstruction method from a single portrait image, regardless of perspective, expression, or accessories. Despite significant efforts in adapting 2D generative models for novel view synthesis and 3D optimization, most methods struggle to produce high-quality 3D portraits. The lack of crucial information, such as identity, expression, hair, and accessories, limits these approaches in generating realistic 3D head models. To address these challenges, we construct a new high-quality dataset containing 227 sequences of digital human portraits captured from 96 different perspectives, totalling 21,792 frames, featuring diverse expressions and accessories. To further improve performance, we integrate identity and expression information into the multi-view diffusion process to enhance facial consistency across views. Specifically, we apply identity- and expression-aware guidance and supervision to extract accurate facial representations, which guide the model and enforce objective functions to ensure high identity and expression consistency during generation. Finally, we generate an orbital video around the portrait consisting of 96 multi-view frames, which can be used for 3D portrait model reconstruction. Our method demonstrates robust performance across challenging scenarios, including side-face angles and complex accessories
Rapid Word Learning Through Meta In-Context Learning
Feb 20, 2025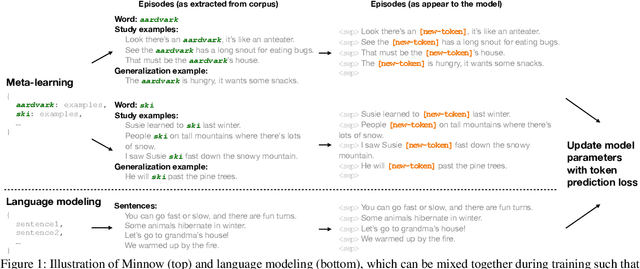
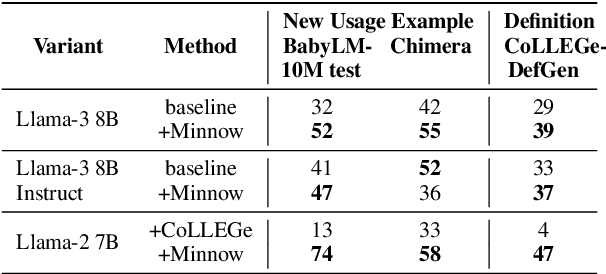

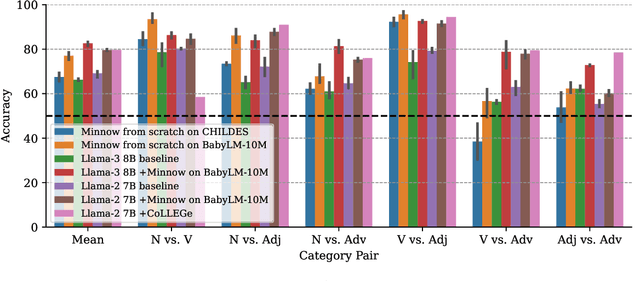
Humans can quickly learn a new word from a few illustrative examples, and then systematically and flexibly use it in novel contexts. Yet the abilities of current language models for few-shot word learning, and methods for improving these abilities, are underexplored. In this study, we introduce a novel method, Meta-training for IN-context learNing Of Words (Minnow). This method trains language models to generate new examples of a word's usage given a few in-context examples, using a special placeholder token to represent the new word. This training is repeated on many new words to develop a general word-learning ability. We find that training models from scratch with Minnow on human-scale child-directed language enables strong few-shot word learning, comparable to a large language model (LLM) pre-trained on orders of magnitude more data. Furthermore, through discriminative and generative evaluations, we demonstrate that finetuning pre-trained LLMs with Minnow improves their ability to discriminate between new words, identify syntactic categories of new words, and generate reasonable new usages and definitions for new words, based on one or a few in-context examples. These findings highlight the data efficiency of Minnow and its potential to improve language model performance in word learning tasks.
TD-RD: A Top-Down Benchmark with Real-Time Framework for Road Damage Detection
Jan 24, 2025



Object detection has witnessed remarkable advancements over the past decade, largely driven by breakthroughs in deep learning and the proliferation of large scale datasets. However, the domain of road damage detection remains relatively under explored, despite its critical significance for applications such as infrastructure maintenance and road safety. This paper addresses this gap by introducing a novel top down benchmark that offers a complementary perspective to existing datasets, specifically tailored for road damage detection. Our proposed Top Down Road Damage Detection Dataset (TDRD) includes three primary categories of road damage cracks, potholes, and patches captured from a top down viewpoint. The dataset consists of 7,088 high resolution images, encompassing 12,882 annotated instances of road damage. Additionally, we present a novel real time object detection framework, TDYOLOV10, designed to handle the unique challenges posed by the TDRD dataset. Comparative studies with state of the art models demonstrate competitive baseline results. By releasing TDRD, we aim to accelerate research in this crucial area. A sample of the dataset will be made publicly available upon the paper's acceptance.
GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data
Nov 27, 2024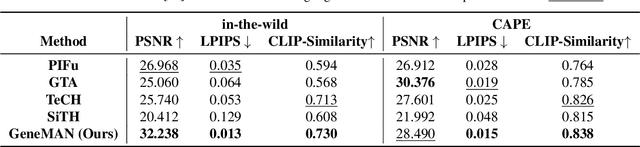


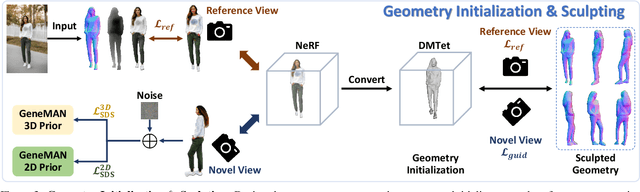
Given a single in-the-wild human photo, it remains a challenging task to reconstruct a high-fidelity 3D human model. Existing methods face difficulties including a) the varying body proportions captured by in-the-wild human images; b) diverse personal belongings within the shot; and c) ambiguities in human postures and inconsistency in human textures. In addition, the scarcity of high-quality human data intensifies the challenge. To address these problems, we propose a Generalizable image-to-3D huMAN reconstruction framework, dubbed GeneMAN, building upon a comprehensive multi-source collection of high-quality human data, including 3D scans, multi-view videos, single photos, and our generated synthetic human data. GeneMAN encompasses three key modules. 1) Without relying on parametric human models (e.g., SMPL), GeneMAN first trains a human-specific text-to-image diffusion model and a view-conditioned diffusion model, serving as GeneMAN 2D human prior and 3D human prior for reconstruction, respectively. 2) With the help of the pretrained human prior models, the Geometry Initialization-&-Sculpting pipeline is leveraged to recover high-quality 3D human geometry given a single image. 3) To achieve high-fidelity 3D human textures, GeneMAN employs the Multi-Space Texture Refinement pipeline, consecutively refining textures in the latent and the pixel spaces. Extensive experimental results demonstrate that GeneMAN could generate high-quality 3D human models from a single image input, outperforming prior state-of-the-art methods. Notably, GeneMAN could reveal much better generalizability in dealing with in-the-wild images, often yielding high-quality 3D human models in natural poses with common items, regardless of the body proportions in the input images.
Towards Efficient Moion Planning for UAVs: Lazy A* Search with Motion Primitives
Oct 02, 2024

Search-based motion planning algorithms have been widely utilized for unmanned aerial vehicles (UAVs). However, deploying these algorithms on real UAVs faces challenges due to limited onboard computational resources. The algorithms struggle to find solutions in high-dimensional search spaces and require considerable time to ensure that the trajectories are dynamically feasible. This paper incorporates the lazy search concept into search-based planning algorithms to address the critical issue of real-time planning for collision-free and dynamically feasible trajectories on UAVs. We demonstrate that the lazy search motion planning algorithm can efficiently find optimal trajectories and significantly improve computational efficiency.
LaDTalk: Latent Denoising for Synthesizing Talking Head Videos with High Frequency Details
Oct 01, 2024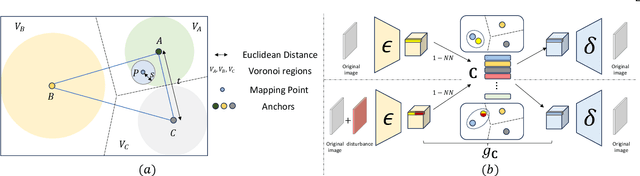
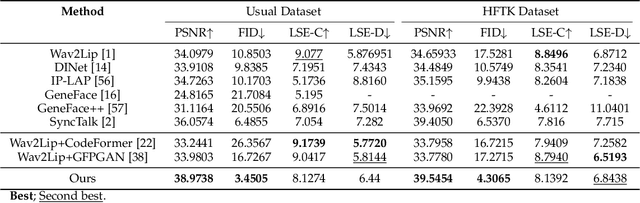


Audio-driven talking head generation is a pivotal area within film-making and Virtual Reality. Although existing methods have made significant strides following the end-to-end paradigm, they still encounter challenges in producing videos with high-frequency details due to their limited expressivity in this domain. This limitation has prompted us to explore an effective post-processing approach to synthesize photo-realistic talking head videos. Specifically, we employ a pretrained Wav2Lip model as our foundation model, leveraging its robust audio-lip alignment capabilities. Drawing on the theory of Lipschitz Continuity, we have theoretically established the noise robustness of Vector Quantised Auto Encoders (VQAEs). Our experiments further demonstrate that the high-frequency texture deficiency of the foundation model can be temporally consistently recovered by the Space-Optimised Vector Quantised Auto Encoder (SOVQAE) we introduced, thereby facilitating the creation of realistic talking head videos. We conduct experiments on both the conventional dataset and the High-Frequency TalKing head (HFTK) dataset that we curated. The results indicate that our method, LaDTalk, achieves new state-of-the-art video quality and out-of-domain lip synchronization performance.
FoAM: Foresight-Augmented Multi-Task Imitation Policy for Robotic Manipulation
Sep 29, 2024



Multi-task imitation learning (MTIL) has shown significant potential in robotic manipulation by enabling agents to perform various tasks using a unified policy. This simplifies the policy deployment and enhances the agent's adaptability across different contexts. However, key challenges remain, such as maintaining action reliability (e.g., avoiding abnormal action sequences that deviate from nominal task trajectories), distinguishing between similar tasks, and generalizing to unseen scenarios. To address these challenges, we introduce the Foresight-Augmented Manipulation Policy (FoAM), an innovative MTIL framework. FoAM not only learns to mimic expert actions but also predicts the visual outcomes of those actions to enhance decision-making. Additionally, it integrates multi-modal goal inputs, such as visual and language prompts, overcoming the limitations of single-conditioned policies. We evaluated FoAM across over 100 tasks in both simulation and real-world settings, demonstrating that it significantly improves IL policy performance, outperforming current state-of-the-art IL baselines by up to 41% in success rate. Furthermore, we released a simulation benchmark for robotic manipulation, featuring 10 task suites and over 80 challenging tasks designed for multi-task policy training and evaluation. See project homepage https://projFoAM.github.io/ for project details.
BAFNet: Bilateral Attention Fusion Network for Lightweight Semantic Segmentation of Urban Remote Sensing Images
Sep 16, 2024



Large-scale semantic segmentation networks often achieve high performance, while their application can be challenging when faced with limited sample sizes and computational resources. In scenarios with restricted network size and computational complexity, models encounter significant challenges in capturing long-range dependencies and recovering detailed information in images. We propose a lightweight bilateral semantic segmentation network called bilateral attention fusion network (BAFNet) to efficiently segment high-resolution urban remote sensing images. The model consists of two paths, namely dependency path and remote-local path. The dependency path utilizes large kernel attention to acquire long-range dependencies in the image. Besides, multi-scale local attention and efficient remote attention are designed to construct remote-local path. Finally, a feature aggregation module is designed to effectively utilize the different features of the two paths. Our proposed method was tested on public high-resolution urban remote sensing datasets Vaihingen and Potsdam, with mIoU reaching 83.20% and 86.53%, respectively. As a lightweight semantic segmentation model, BAFNet not only outperforms advanced lightweight models in accuracy but also demonstrates comparable performance to non-lightweight state-of-the-art methods on two datasets, despite a tenfold variance in floating-point operations and a fifteenfold difference in network parameters.
HGTDP-DTA: Hybrid Graph-Transformer with Dynamic Prompt for Drug-Target Binding Affinity Prediction
Jun 25, 2024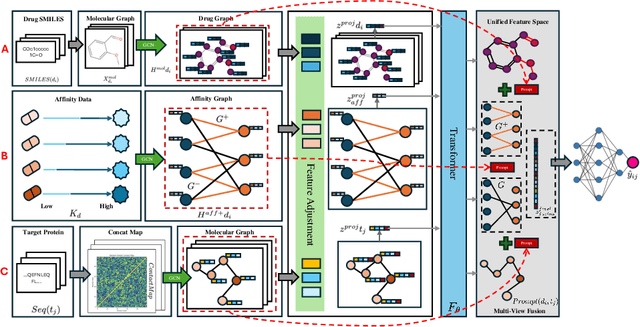
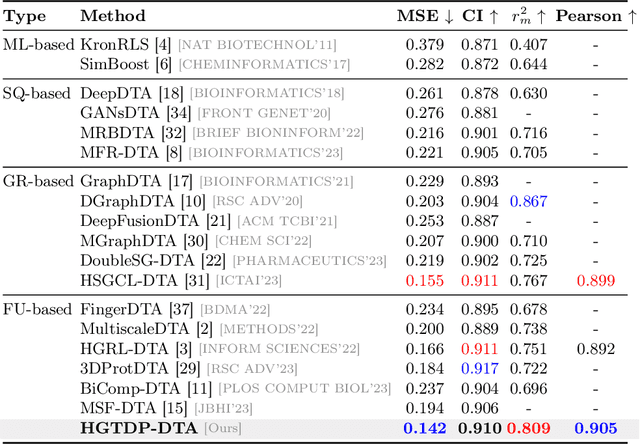
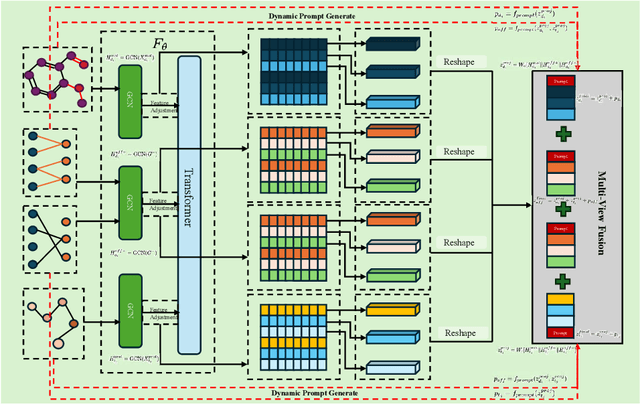
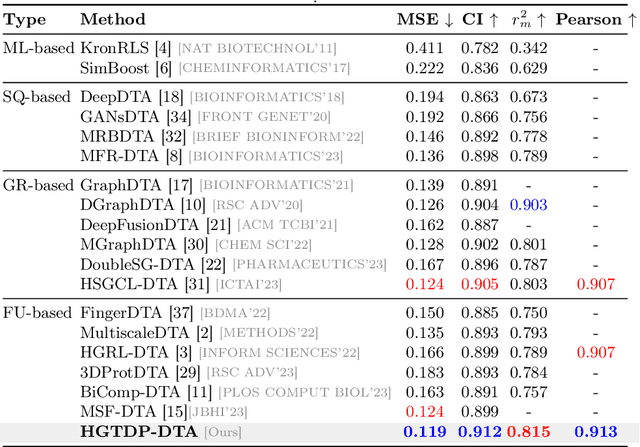
Drug target binding affinity (DTA) is a key criterion for drug screening. Existing experimental methods are time-consuming and rely on limited structural and domain information. While learning-based methods can model sequence and structural information, they struggle to integrate contextual data and often lack comprehensive modeling of drug-target interactions. In this study, we propose a novel DTA prediction method, termed HGTDP-DTA, which utilizes dynamic prompts within a hybrid Graph-Transformer framework. Our method generates context-specific prompts for each drug-target pair, enhancing the model's ability to capture unique interactions. The introduction of prompt tuning further optimizes the prediction process by filtering out irrelevant noise and emphasizing task-relevant information, dynamically adjusting the input features of the molecular graph. The proposed hybrid Graph-Transformer architecture combines structural information from Graph Convolutional Networks (GCNs) with sequence information captured by Transformers, facilitating the interaction between global and local information. Additionally, we adopted the multi-view feature fusion method to project molecular graph views and affinity subgraph views into a common feature space, effectively combining structural and contextual information. Experiments on two widely used public datasets, Davis and KIBA, show that HGTDP-DTA outperforms state-of-the-art DTA prediction methods in both prediction performance and generalization ability.