 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuMoCon: Concept Discovery for Human Motion Understanding
May 27, 2025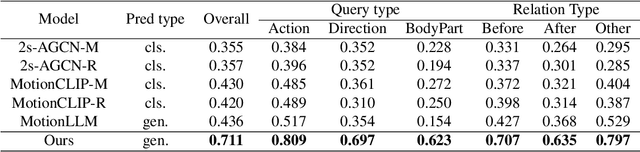
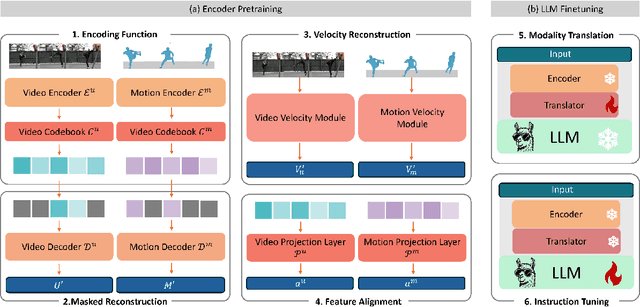
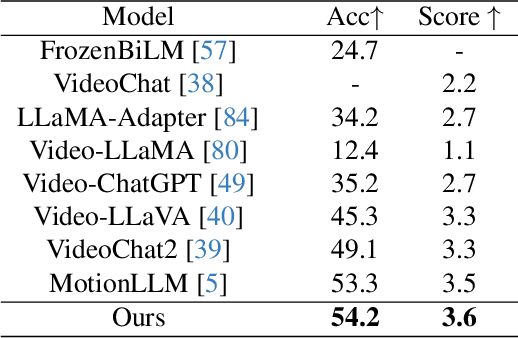
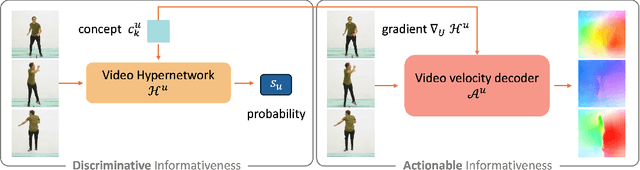
We present HuMoCon, a novel motion-video understanding framework designed for advanced human behavior analysis. The core of our method is a human motion concept discovery framework that efficiently trains multi-modal encoders to extract semantically meaningful and generalizable features. HuMoCon addresses key challenges in motion concept discovery for understanding and reasoning, including the lack of explicit multi-modality feature alignment and the loss of high-frequency information in masked autoencoding frameworks. Our approach integrates a feature alignment strategy that leverages video for contextual understanding and motion for fine-grained interaction modeling, further with a velocity reconstruction mechanism to enhance high-frequency feature expression and mitigate temporal over-smoothing. Comprehensive experiments on standard benchmarks demonstrate that HuMoCon enables effective motion concept discovery and significantly outperforms state-of-the-art methods in training large models for human motion understanding. We will open-source the associated code with our paper.
* 18 pages, 10 figures
CigTime: Corrective Instruction Generation Through Inverse Motion Editing
Dec 06, 2024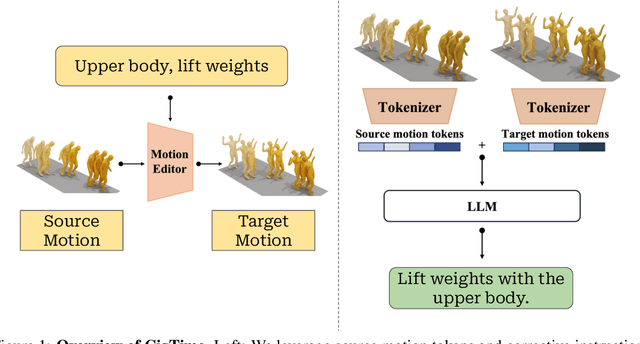
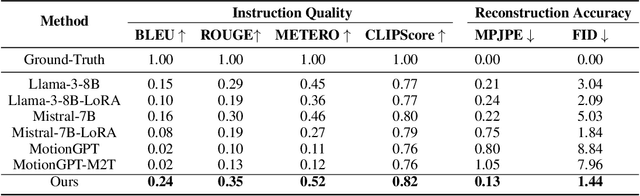

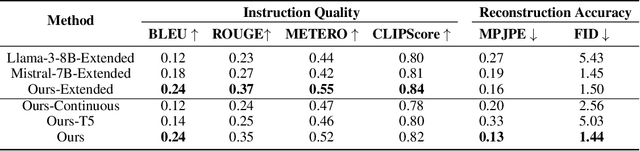
Recent advancements in models linking natural language with human motions have shown significant promise in motion generation and editing based on instructional text. Motivated by applications in sports coaching and motor skill learning, we investigate the inverse problem: generating corrective instructional text, leveraging motion editing and generation models. We introduce a novel approach that, given a user's current motion (source) and the desired motion (target), generates text instructions to guide the user towards achieving the target motion. We leverage large language models to generate corrective texts and utilize existing motion generation and editing frameworks to compile datasets of triplets (source motion, target motion, and corrective text). Using this data, we propose a new motion-language model for generating corrective instructions. We present both qualitative and quantitative results across a diverse range of applications that largely improve upon baselines. Our approach demonstrates its effectiveness in instructional scenarios, offering text-based guidance to correct and enhance user performance.
LaDTalk: Latent Denoising for Synthesizing Talking Head Videos with High Frequency Details
Oct 01, 2024
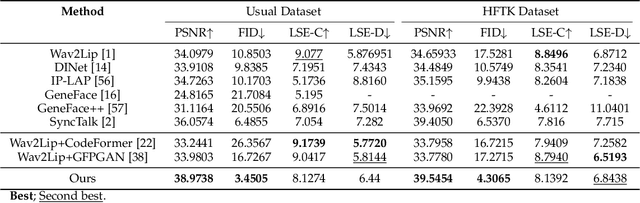


Audio-driven talking head generation is a pivotal area within film-making and Virtual Reality. Although existing methods have made significant strides following the end-to-end paradigm, they still encounter challenges in producing videos with high-frequency details due to their limited expressivity in this domain. This limitation has prompted us to explore an effective post-processing approach to synthesize photo-realistic talking head videos. Specifically, we employ a pretrained Wav2Lip model as our foundation model, leveraging its robust audio-lip alignment capabilities. Drawing on the theory of Lipschitz Continuity, we have theoretically established the noise robustness of Vector Quantised Auto Encoders (VQAEs). Our experiments further demonstrate that the high-frequency texture deficiency of the foundation model can be temporally consistently recovered by the Space-Optimised Vector Quantised Auto Encoder (SOVQAE) we introduced, thereby facilitating the creation of realistic talking head videos. We conduct experiments on both the conventional dataset and the High-Frequency TalKing head (HFTK) dataset that we curated. The results indicate that our method, LaDTalk, achieves new state-of-the-art video quality and out-of-domain lip synchronization performance.
BID: Boundary-Interior Decoding for Unsupervised Temporal Action Localization Pre-Trainin
Mar 12, 2024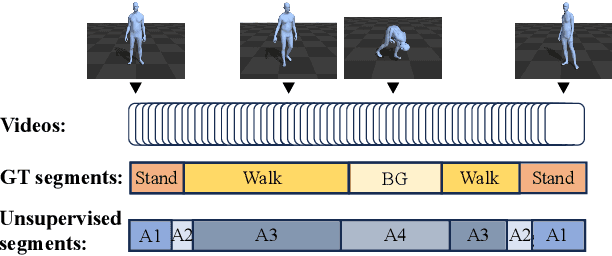
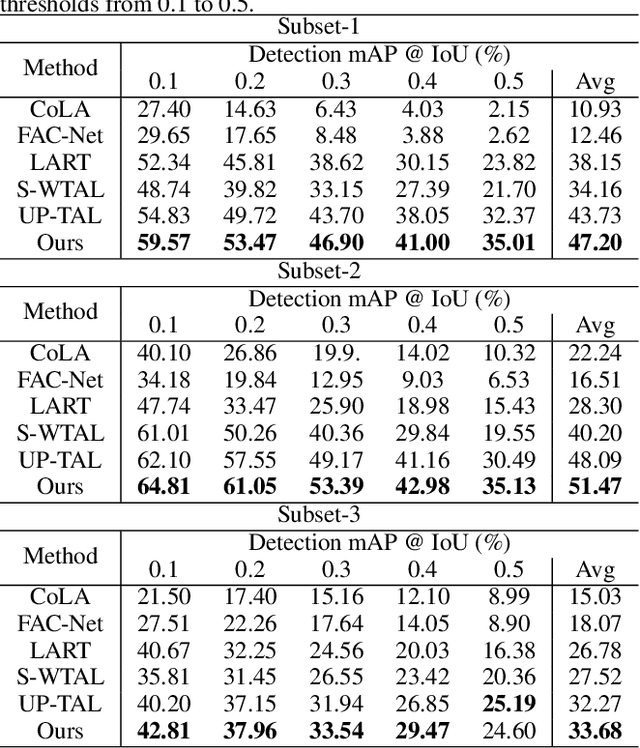
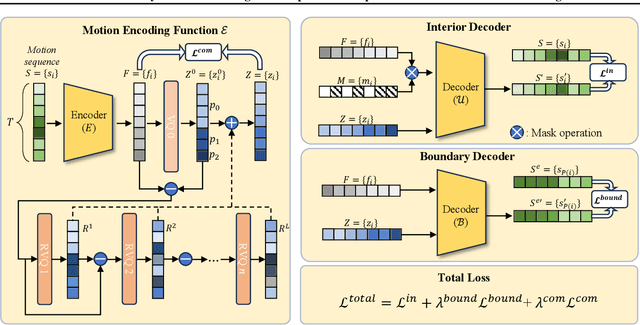
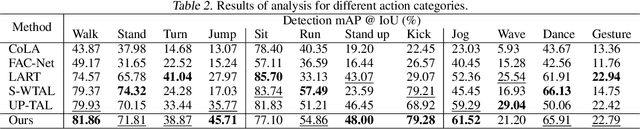
Skeleton-based motion representations are robust for action localization and understanding for their invariance to perspective, lighting, and occlusion, compared with images. Yet, they are often ambiguous and incomplete when taken out of context, even for human annotators. As infants discern gestures before associating them with words, actions can be conceptualized before being grounded with labels. Therefore, we propose the first unsupervised pre-training framework, Boundary-Interior Decoding (BID), that partitions a skeleton-based motion sequence into discovered semantically meaningful pre-action segments. By fine-tuning our pre-training network with a small number of annotated data, we show results out-performing SOTA methods by a large margin.
Reducing Shape-Radiance Ambiguity in Radiance Fields with a Closed-Form Color Estimation Method
Dec 20, 2023Neural radiance field (NeRF) enables the synthesis of cutting-edge realistic novel view images of a 3D scene. It includes density and color fields to model the shape and radiance of a scene, respectively. Supervised by the photometric loss in an end-to-end training manner, NeRF inherently suffers from the shape-radiance ambiguity problem, i.e., it can perfectly fit training views but does not guarantee decoupling the two fields correctly. To deal with this issue, existing works have incorporated prior knowledge to provide an independent supervision signal for the density field, including total variation loss, sparsity loss, distortion loss, etc. These losses are based on general assumptions about the density field, e.g., it should be smooth, sparse, or compact, which are not adaptive to a specific scene. In this paper, we propose a more adaptive method to reduce the shape-radiance ambiguity. The key is a rendering method that is only based on the density field. Specifically, we first estimate the color field based on the density field and posed images in a closed form. Then NeRF's rendering process can proceed. We address the problems in estimating the color field, including occlusion and non-uniformly distributed views. Afterward, it is applied to regularize NeRF's density field. As our regularization is guided by photometric loss, it is more adaptive compared to existing ones. Experimental results show that our method improves the density field of NeRF both qualitatively and quantitatively. Our code is available at https://github.com/qihangGH/Closed-form-color-field.
Evaluate Geometry of Radiance Field with Low-frequency Color Prior
Apr 10, 2023Radiance field is an effective representation of 3D scenes, which has been widely adopted in novel-view synthesis and 3D reconstruction. It is still an open and challenging problem to evaluate the geometry, i.e., the density field, as the ground-truth is almost impossible to be obtained. One alternative indirect solution is to transform the density field into a point-cloud and compute its Chamfer Distance with the scanned ground-truth. However, many widely-used datasets have no point-cloud ground-truth since the scanning process along with the equipment is expensive and complicated. To this end, we propose a novel metric, named Inverse Mean Residual Color (IMRC), which can evaluate the geometry only with the observation images. Our key insight is that the better the geometry is, the lower-frequency the computed color field is. From this insight, given reconstructed density field and the observation images, we design a closed-form method to approximate the color field with low-frequency spherical harmonics and compute the inverse mean residual color. Then the higher the IMRC, the better the geometry. Qualitative and quantitative experimental results verify the effectiveness of our proposed IMRC metric. We also benchmark several state-of-the-art methods using IMRC to promote future related research.
Active Visual Localization in Partially Calibrated Environments
Dec 08, 2020
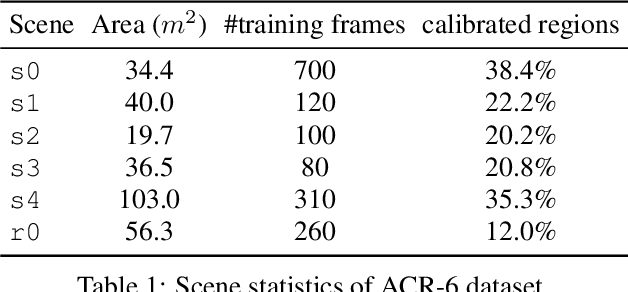
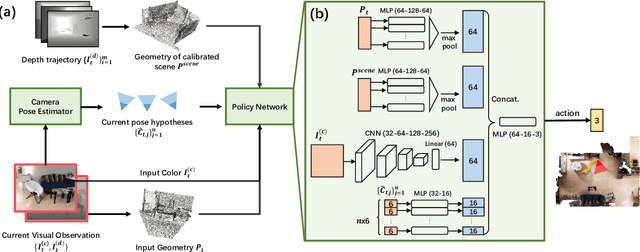

Humans can robustly localize themselves without a map after they get lost following prominent visual cues or landmarks. In this work, we aim at endowing autonomous agents the same ability. Such ability is important in robotics applications yet very challenging when an agent is exposed to partially calibrated environments, where camera images with accurate 6 Degree-of-Freedom pose labels only cover part of the scene. To address the above challenge, we explore using Reinforcement Learning to search for a policy to generate intelligent motions so as to actively localize the agent given visual information in partially calibrated environments. Our core contribution is to formulate the active visual localization problem as a Partially Observable Markov Decision Process and propose an algorithmic framework based on Deep Reinforcement Learning to solve it. We further propose an indoor scene dataset ACR-6, which consists of both synthetic and real data and simulates challenging scenarios for active visual localization. We benchmark our algorithm against handcrafted baselines for localization and demonstrate that our approach significantly outperforms them on localization success rate.