 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality 3D Head Reconstruction from Any Single Portrait Image
Mar 11, 2025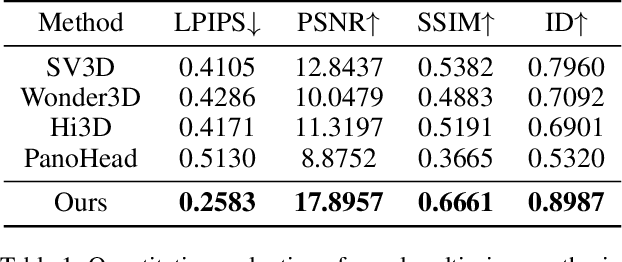
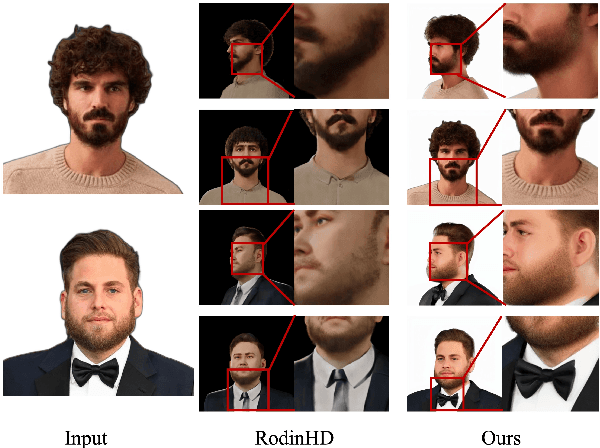
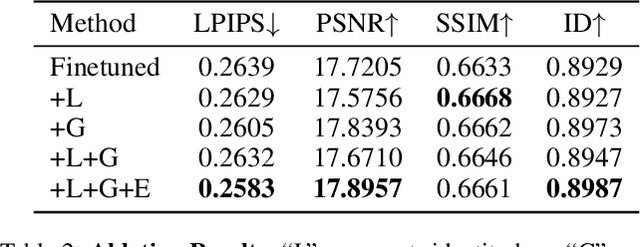
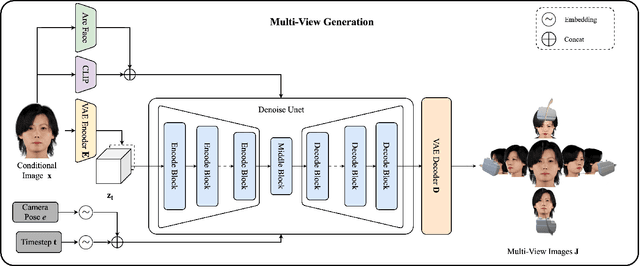
In this work, we introduce a novel high-fidelity 3D head reconstruction method from a single portrait image, regardless of perspective, expression, or accessories. Despite significant efforts in adapting 2D generative models for novel view synthesis and 3D optimization, most methods struggle to produce high-quality 3D portraits. The lack of crucial information, such as identity, expression, hair, and accessories, limits these approaches in generating realistic 3D head models. To address these challenges, we construct a new high-quality dataset containing 227 sequences of digital human portraits captured from 96 different perspectives, totalling 21,792 frames, featuring diverse expressions and accessories. To further improve performance, we integrate identity and expression information into the multi-view diffusion process to enhance facial consistency across views. Specifically, we apply identity- and expression-aware guidance and supervision to extract accurate facial representations, which guide the model and enforce objective functions to ensure high identity and expression consistency during generation. Finally, we generate an orbital video around the portrait consisting of 96 multi-view frames, which can be used for 3D portrait model reconstruction. Our method demonstrates robust performance across challenging scenarios, including side-face angles and complex accessories