 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResonant Minds: Closed-Loop Social Avatars with Theory of Mind
Jun 04, 2026Creating lifelike digital humans with genuine social intelligence requires unifying cognitive reasoning and multimodal generation within a coherent framework. Current approaches treat these as separate tasks: Large Language Models excel at dialogue but lack embodied expression, while diffusion-based talking head models achieve visual fidelity but ignore social cognition. To bridge this gap, we propose a closed-loop dual-agent framework integrating perception, social reasoning, and expression into a continuous interaction cycle. The perception module analyzes partners' multimodal behaviors from video, while the social reasoning module infers hidden mental states through Theory of Mind and selects responses via an ensemble mechanism. The expression module then generates emotion-controllable dual-agent videos synthesizing both speaker speech and expression alongside listener reactive behaviors, capturing bidirectional dynamics absent in prior work. We construct a hierarchical Persona-Scenario dataset with psychologically grounded personas and private social goals to support evaluation under information asymmetry. Experiments on this dataset demonstrate competitive or superior performance on both dialogue quality and video generation metrics. Notably, our method surpasses even the full-information Script mode on key dialogue quality dimensions, suggesting that explicit mental state inference under uncertainty can elicit more thoughtful dialogue than unrestricted information access.
SUGAR: A Scalable Human-Video-Driven Generalizable Humanoid Loco-Manipulation Learning Framework
May 19, 2026Building humanoid robots capable of generalizable whole-body loco-manipulation in the real world remains a fundamental challenge. Existing methods either rely on laborious task-specific reward engineering, rigidly replay reference motions that fail to generalize, or depend on costly teleoperation that limits scalability. While human videos capture diverse human behaviors, motion priors inferred from them are inherently imperfect, suffering from occlusion, contact artifacts, and retargeting errors that render them unsuitable for direct policy learning. To address this, we present SUGAR, a scalable data-driven framework that converts diverse human videos into deployable humanoid loco-manipulation skills, without any task-specific reward engineering or reference-motion conditioning at inference. SUGAR proceeds in three stages. First, a fully automated pipeline extracts kinematic interaction priors including human-object motion trajectories and contact labels from unstructured human videos. Second, a privileged physics-based refiner uses a unified mimic reward and progressive state pool to transform imperfect priors into physically feasible, high-fidelity skills. Third, refined skills are distilled into a hierarchical autonomous policy consisting of a command generator and a command tracker. We evaluate SUGAR on six representative loco-manipulation tasks in simulation and real-world humanoid hardware. Our method substantially outperforms reference-tracking baselines, and performance scales clearly with the amount of human video data. It also achieves zero-shot real-world transfer with reliable closed-loop execution, autonomous failure recovery, and stable long-horizon performance under external perturbations. Project Page: https://tianshuwu.github.io/sugar-humanoid/
Visually-grounded Humanoid Agents
Apr 09, 2026Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
RichControl: Structure- and Appearance-Rich Training-Free Spatial Control for Text-to-Image Generation
Jul 03, 2025Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., depth or pose maps) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. By revisiting existing methods, we identify a core limitation: the synchronous injection of condition features fails to account for the trade-off between domain alignment and structural preservation during denoising. Inspired by this observation, we propose a flexible feature injection framework that decouples the injection timestep from the denoising process. At its core is a structure-rich injection module, which enables the model to better adapt to the evolving interplay between alignment and structure preservation throughout the diffusion steps, resulting in more faithful structural generation. In addition, we introduce appearance-rich prompting and a restart refinement strategy to further enhance appearance control and visual quality. Together, these designs enable training-free generation that is both structure-rich and appearance-rich. Extensive experiments show that our approach achieves state-of-the-art performance across diverse zero-shot conditioning scenarios.
KARMA: A Multilevel Decomposition Hybrid Mamba Framework for Multivariate Long-Term Time Series Forecasting
Jun 10, 2025Multivariate long-term and efficient time series forecasting is a key requirement for a variety of practical applications, and there are complex interleaving time dynamics in time series data that require decomposition modeling. Traditional time series decomposition methods are single and rely on fixed rules, which are insufficient for mining the potential information of the series and adapting to the dynamic characteristics of complex series. On the other hand, the Transformer-based models for time series forecasting struggle to effectively model long sequences and intricate dynamic relationships due to their high computational complexity. To overcome these limitations, we introduce KARMA, with an Adaptive Time Channel Decomposition module (ATCD) to dynamically extract trend and seasonal components. It further integrates a Hybrid Frequency-Time Decomposition module (HFTD) to further decompose Series into frequency-domain and time-domain. These components are coupled with multi-scale Mamba-based KarmaBlock to efficiently process global and local information in a coordinated manner. Experiments on eight real-world datasets from diverse domains well demonstrated that KARMA significantly outperforms mainstream baseline methods in both predictive accuracy and computational efficiency. Code and full results are available at this repository: https://github.com/yedadasd/KARMA
HICD: Hallucination-Inducing via Attention Dispersion for Contrastive Decoding to Mitigate Hallucinations in Large Language Models
Mar 17, 2025



Large Language Models (LLMs) often generate hallucinations, producing outputs that are contextually inaccurate or factually incorrect. We introduce HICD, a novel method designed to induce hallucinations for contrastive decoding to mitigate hallucinations. Unlike existing contrastive decoding methods, HICD selects attention heads crucial to the model's prediction as inducing heads, then induces hallucinations by dispersing attention of these inducing heads and compares the hallucinated outputs with the original outputs to obtain the final result. Our approach significantly improves performance on tasks requiring contextual faithfulness, such as context completion, reading comprehension, and question answering. It also improves factuality in tasks requiring accurate knowledge recall. We demonstrate that our inducing heads selection and attention dispersion method leads to more "contrast-effective" hallucinations for contrastive decoding, outperforming other hallucination-inducing methods. Our findings provide a promising strategy for reducing hallucinations by inducing hallucinations in a controlled manner, enhancing the performance of LLMs in a wide range of tasks.
Free-form Generation Enhances Challenging Clothed Human Modeling
Nov 29, 2024



Achieving realistic animated human avatars requires accurate modeling of pose-dependent clothing deformations. Existing learning-based methods heavily rely on the Linear Blend Skinning (LBS) of minimally-clothed human models like SMPL to model deformation. However, these methods struggle to handle loose clothing, such as long dresses, where the canonicalization process becomes ill-defined when the clothing is far from the body, leading to disjointed and fragmented results. To overcome this limitation, we propose a novel hybrid framework to model challenging clothed humans. Our core idea is to use dedicated strategies to model different regions, depending on whether they are close to or distant from the body. Specifically, we segment the human body into three categories: unclothed, deformed, and generated. We simply replicate unclothed regions that require no deformation. For deformed regions close to the body, we leverage LBS to handle the deformation. As for the generated regions, which correspond to loose clothing areas, we introduce a novel free-form, part-aware generator to model them, as they are less affected by movements. This free-form generation paradigm brings enhanced flexibility and expressiveness to our hybrid framework, enabling it to capture the intricate geometric details of challenging loose clothing, such as skirts and dresses. Experimental results on the benchmark dataset featuring loose clothing demonstrate that our method achieves state-of-the-art performance with superior visual fidelity and realism, particularly in the most challenging cases.
GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data
Nov 27, 2024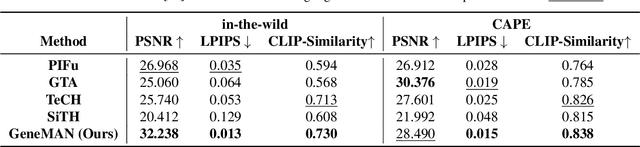


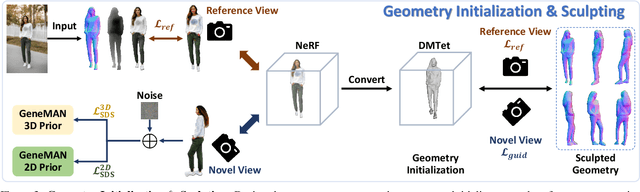
Given a single in-the-wild human photo, it remains a challenging task to reconstruct a high-fidelity 3D human model. Existing methods face difficulties including a) the varying body proportions captured by in-the-wild human images; b) diverse personal belongings within the shot; and c) ambiguities in human postures and inconsistency in human textures. In addition, the scarcity of high-quality human data intensifies the challenge. To address these problems, we propose a Generalizable image-to-3D huMAN reconstruction framework, dubbed GeneMAN, building upon a comprehensive multi-source collection of high-quality human data, including 3D scans, multi-view videos, single photos, and our generated synthetic human data. GeneMAN encompasses three key modules. 1) Without relying on parametric human models (e.g., SMPL), GeneMAN first trains a human-specific text-to-image diffusion model and a view-conditioned diffusion model, serving as GeneMAN 2D human prior and 3D human prior for reconstruction, respectively. 2) With the help of the pretrained human prior models, the Geometry Initialization-&-Sculpting pipeline is leveraged to recover high-quality 3D human geometry given a single image. 3) To achieve high-fidelity 3D human textures, GeneMAN employs the Multi-Space Texture Refinement pipeline, consecutively refining textures in the latent and the pixel spaces. Extensive experimental results demonstrate that GeneMAN could generate high-quality 3D human models from a single image input, outperforming prior state-of-the-art methods. Notably, GeneMAN could reveal much better generalizability in dealing with in-the-wild images, often yielding high-quality 3D human models in natural poses with common items, regardless of the body proportions in the input images.
CLoG: Benchmarking Continual Learning of Image Generation Models
Jun 07, 2024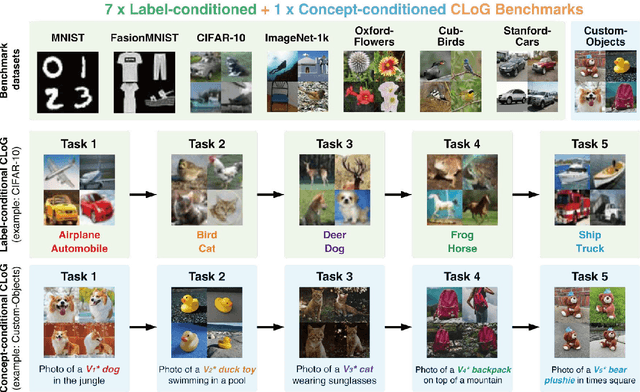
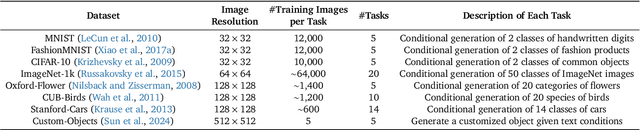
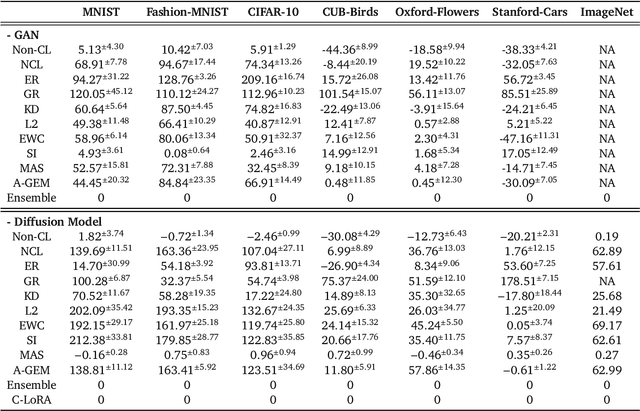

Continual Learning (CL) poses a significant challenge in Artificial Intelligence, aiming to mirror the human ability to incrementally acquire knowledge and skills. While extensive research has focused on CL within the context of classification tasks, the advent of increasingly powerful generative models necessitates the exploration of Continual Learning of Generative models (CLoG). This paper advocates for shifting the research focus from classification-based CL to CLoG. We systematically identify the unique challenges presented by CLoG compared to traditional classification-based CL. We adapt three types of existing CL methodologies, replay-based, regularization-based, and parameter-isolation-based methods to generative tasks and introduce comprehensive benchmarks for CLoG that feature great diversity and broad task coverage. Our benchmarks and results yield intriguing insights that can be valuable for developing future CLoG methods. Additionally, we will release a codebase designed to facilitate easy benchmarking and experimentation in CLoG publicly at https://github.com/linhaowei1/CLoG. We believe that shifting the research focus to CLoG will benefit the continual learning community and illuminate the path for next-generation AI-generated content (AIGC) in a lifelong learning paradigm.
Social Motion Prediction with Cognitive Hierarchies
Nov 08, 2023Humans exhibit a remarkable capacity for anticipating the actions of others and planning their own actions accordingly. In this study, we strive to replicate this ability by addressing the social motion prediction problem. We introduce a new benchmark, a novel formulation, and a cognition-inspired framework. We present Wusi, a 3D multi-person motion dataset under the context of team sports, which features intense and strategic human interactions and diverse pose distributions. By reformulating the problem from a multi-agent reinforcement learning perspective, we incorporate behavioral cloning and generative adversarial imitation learning to boost learning efficiency and generalization. Furthermore, we take into account the cognitive aspects of the human social action planning process and develop a cognitive hierarchy framework to predict strategic human social interactions. We conduct comprehensive experiments to validate the effectiveness of our proposed dataset and approach. Code and data are available at https://walter0807.github.io/Social-CH/.