 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long Short-Term Intention within Human Daily Behaviors
Apr 10, 2025In the domain of autonomous household robots, it is of utmost importance for robots to understand human behaviors and provide appropriate services. This requires the robots to possess the capability to analyze complex human behaviors and predict the true intentions of humans. Traditionally, humans are perceived as flawless, with their decisions acting as the standards that robots should strive to align with. However, this raises a pertinent question: What if humans make mistakes? In this research, we present a unique task, termed "long short-term intention prediction". This task requires robots can predict the long-term intention of humans, which aligns with human values, and the short term intention of humans, which reflects the immediate action intention. Meanwhile, the robots need to detect the potential non-consistency between the short-term and long-term intentions, and provide necessary warnings and suggestions. To facilitate this task, we propose a long short-term intention model to represent the complex intention states, and build a dataset to train this intention model. Then we propose a two-stage method to integrate the intention model for robots: i) predicting human intentions of both value-based long-term intentions and action-based short-term intentions; and 2) analyzing the consistency between the long-term and short-term intentions. Experimental results indicate that the proposed long short-term intention model can assist robots in comprehending human behavioral patterns over both long-term and short-term durations, which helps determine the consistency between long-term and short-term intentions of humans.
LongViTU: Instruction Tuning for Long-Form Video Understanding
Jan 09, 2025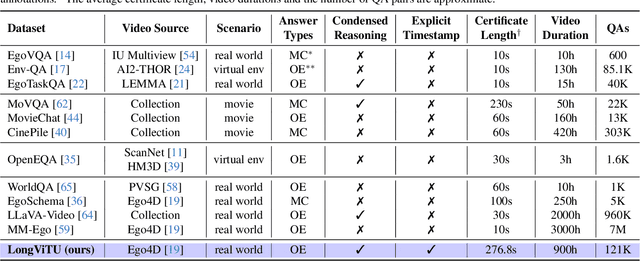
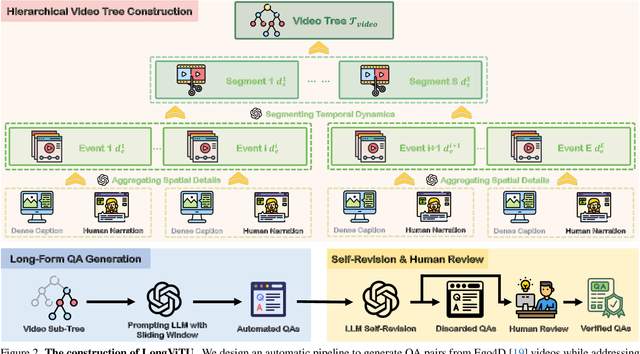
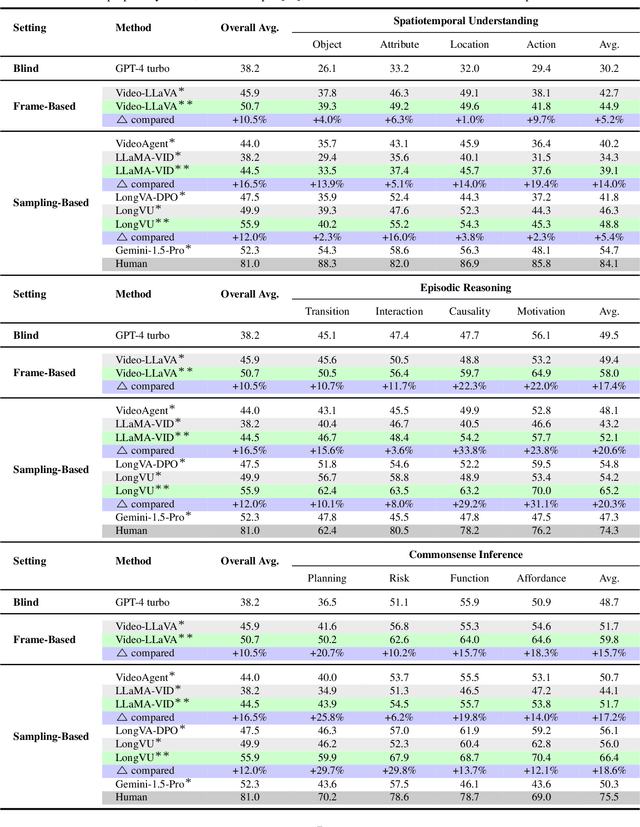
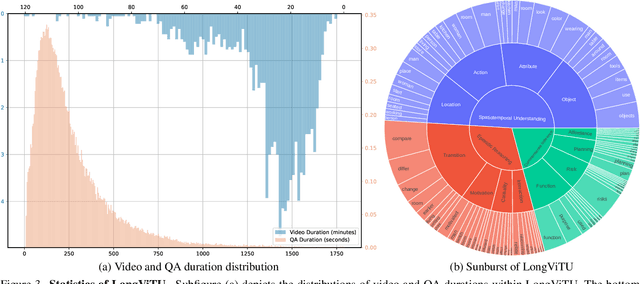
This paper introduce LongViTU, a large-scale (~121k QA pairs, ~900h videos), automatically generated dataset for long-form video understanding. We developed a systematic approach that organizes videos into a hierarchical tree structure and incorporates self-revision mechanisms to ensure high-quality QA pairs. Each QA pair in LongViTU features: 1) long-term context (average certificate length of 4.6 minutes); 2) rich knowledge and condensed reasoning (commonsense, causality, planning, etc.); and 3) explicit timestamp labels for relevant events. LongViTU also serves as a benchmark for instruction following in long-form and streaming video understanding. We evaluate the open-source state-of-the-art long video understanding model, LongVU, and the commercial model, Gemini-1.5-Pro, on our benchmark. They achieve GPT-4 scores of 49.9 and 52.3, respectively, underscoring the substantial challenge posed by our benchmark. Further supervised fine-tuning (SFT) on LongVU led to performance improvements of 12.0% on our benchmark, 2.2% on the in-distribution (ID) benchmark EgoSchema, 1.0%, 2.2% and 1.2% on the out-of-distribution (OOD) benchmarks VideoMME (Long), WorldQA and OpenEQA, respectively. These outcomes demonstrate LongViTU's high data quality and robust OOD generalizability.
Embodied VideoAgent: Persistent Memory from Egocentric Videos and Embodied Sensors Enables Dynamic Scene Understanding
Dec 31, 2024



This paper investigates the problem of understanding dynamic 3D scenes from egocentric observations, a key challenge in robotics and embodied AI. Unlike prior studies that explored this as long-form video understanding and utilized egocentric video only, we instead propose an LLM-based agent, Embodied VideoAgent, which constructs scene memory from both egocentric video and embodied sensory inputs (e.g. depth and pose sensing). We further introduce a VLM-based approach to automatically update the memory when actions or activities over objects are perceived. Embodied VideoAgent attains significant advantages over counterparts in challenging reasoning and planning tasks in 3D scenes, achieving gains of 4.9% on Ego4D-VQ3D, 5.8% on OpenEQA, and 11.7% on EnvQA. We have also demonstrated its potential in various embodied AI tasks including generating embodied interactions and perception for robot manipulation. The code and demo will be made public.
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale
Jul 07, 2024



This paper presents UltraEdit, a large-scale (approximately 4 million editing samples), automatically generated dataset for instruction-based image editing. Our key idea is to address the drawbacks in existing image editing datasets like InstructPix2Pix and MagicBrush, and provide a systematic approach to producing massive and high-quality image editing samples. UltraEdit offers several distinct advantages: 1) It features a broader range of editing instructions by leveraging the creativity of large language models (LLMs) alongside in-context editing examples from human raters; 2) Its data sources are based on real images, including photographs and artworks, which provide greater diversity and reduced bias compared to datasets solely generated by text-to-image models; 3) It also supports region-based editing, enhanced by high-quality, automatically produced region annotations. Our experiments show that canonical diffusion-based editing baselines trained on UltraEdit set new records on MagicBrush and Emu-Edit benchmarks. Our analysis further confirms the crucial role of real image anchors and region-based editing data. The dataset, code, and models can be found in https://ultra-editing.github.io.
VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding
Mar 18, 2024



We explore how reconciling several foundation models (large language models and vision-language models) with a novel unified memory mechanism could tackle the challenging video understanding problem, especially capturing the long-term temporal relations in lengthy videos. In particular, the proposed multimodal agent VideoAgent: 1) constructs a structured memory to store both the generic temporal event descriptions and object-centric tracking states of the video; 2) given an input task query, it employs tools including video segment localization and object memory querying along with other visual foundation models to interactively solve the task, utilizing the zero-shot tool-use ability of LLMs. VideoAgent demonstrates impressive performances on several long-horizon video understanding benchmarks, an average increase of 6.6% on NExT-QA and 26.0% on EgoSchema over baselines, closing the gap between open-sourced models and private counterparts including Gemini 1.5 Pro.
Bongard-OpenWorld: Few-Shot Reasoning for Free-form Visual Concepts in the Real World
Oct 16, 2023



We introduce Bongard-OpenWorld, a new benchmark for evaluating real-world few-shot reasoning for machine vision. It originates from the classical Bongard Problems (BPs): Given two sets of images (positive and negative), the model needs to identify the set that query images belong to by inducing the visual concepts, which is exclusively depicted by images from the positive set. Our benchmark inherits the few-shot concept induction of the original BPs while adding the two novel layers of challenge: 1) open-world free-form concepts, as the visual concepts in Bongard-OpenWorld are unique compositions of terms from an open vocabulary, ranging from object categories to abstract visual attributes and commonsense factual knowledge; 2) real-world images, as opposed to the synthetic diagrams used by many counterparts. In our exploration, Bongard-OpenWorld already imposes a significant challenge to current few-shot reasoning algorithms. We further investigate to which extent the recently introduced Large Language Models (LLMs) and Vision-Language Models (VLMs) can solve our task, by directly probing VLMs, and combining VLMs and LLMs in an interactive reasoning scheme. We even designed a neuro-symbolic reasoning approach that reconciles LLMs & VLMs with logical reasoning to emulate the human problem-solving process for Bongard Problems. However, none of these approaches manage to close the human-machine gap, as the best learner achieves 64% accuracy while human participants easily reach 91%. We hope Bongard-OpenWorld can help us better understand the limitations of current visual intelligence and facilitate future research on visual agents with stronger few-shot visual reasoning capabilities.
Faster VoxelPose: Real-time 3D Human Pose Estimation by Orthographic Projection
Jul 22, 2022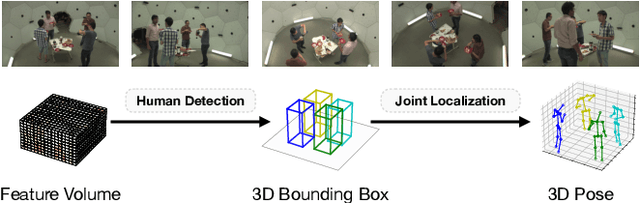


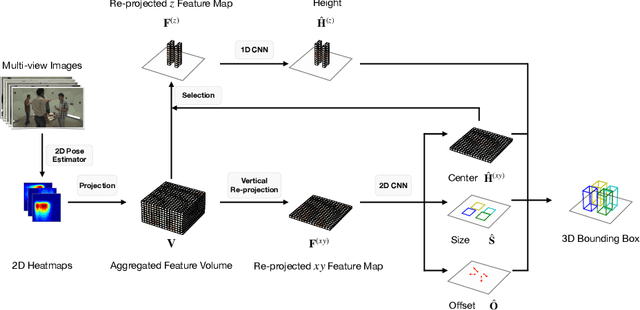
While the voxel-based methods have achieved promising results for multi-person 3D pose estimation from multi-cameras, they suffer from heavy computation burdens, especially for large scenes. We present Faster VoxelPose to address the challenge by re-projecting the feature volume to the three two-dimensional coordinate planes and estimating X, Y, Z coordinates from them separately. To that end, we first localize each person by a 3D bounding box by estimating a 2D box and its height based on the volume features projected to the xy-plane and z-axis, respectively. Then for each person, we estimate partial joint coordinates from the three coordinate planes separately which are then fused to obtain the final 3D pose. The method is free from costly 3D-CNNs and improves the speed of VoxelPose by ten times and meanwhile achieves competitive accuracy as the state-of-the-art methods, proving its potential in real-time applications.