 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARMA: A Multilevel Decomposition Hybrid Mamba Framework for Multivariate Long-Term Time Series Forecasting
Jun 10, 2025Multivariate long-term and efficient time series forecasting is a key requirement for a variety of practical applications, and there are complex interleaving time dynamics in time series data that require decomposition modeling. Traditional time series decomposition methods are single and rely on fixed rules, which are insufficient for mining the potential information of the series and adapting to the dynamic characteristics of complex series. On the other hand, the Transformer-based models for time series forecasting struggle to effectively model long sequences and intricate dynamic relationships due to their high computational complexity. To overcome these limitations, we introduce KARMA, with an Adaptive Time Channel Decomposition module (ATCD) to dynamically extract trend and seasonal components. It further integrates a Hybrid Frequency-Time Decomposition module (HFTD) to further decompose Series into frequency-domain and time-domain. These components are coupled with multi-scale Mamba-based KarmaBlock to efficiently process global and local information in a coordinated manner. Experiments on eight real-world datasets from diverse domains well demonstrated that KARMA significantly outperforms mainstream baseline methods in both predictive accuracy and computational efficiency. Code and full results are available at this repository: https://github.com/yedadasd/KARMA
HICD: Hallucination-Inducing via Attention Dispersion for Contrastive Decoding to Mitigate Hallucinations in Large Language Models
Mar 17, 2025Large Language Models (LLMs) often generate hallucinations, producing outputs that are contextually inaccurate or factually incorrect. We introduce HICD, a novel method designed to induce hallucinations for contrastive decoding to mitigate hallucinations. Unlike existing contrastive decoding methods, HICD selects attention heads crucial to the model's prediction as inducing heads, then induces hallucinations by dispersing attention of these inducing heads and compares the hallucinated outputs with the original outputs to obtain the final result. Our approach significantly improves performance on tasks requiring contextual faithfulness, such as context completion, reading comprehension, and question answering. It also improves factuality in tasks requiring accurate knowledge recall. We demonstrate that our inducing heads selection and attention dispersion method leads to more "contrast-effective" hallucinations for contrastive decoding, outperforming other hallucination-inducing methods. Our findings provide a promising strategy for reducing hallucinations by inducing hallucinations in a controlled manner, enhancing the performance of LLMs in a wide range of tasks.
Bitformer: An efficient Transformer with bitwise operation-based attention for Big Data Analytics at low-cost low-precision devices
Nov 22, 2023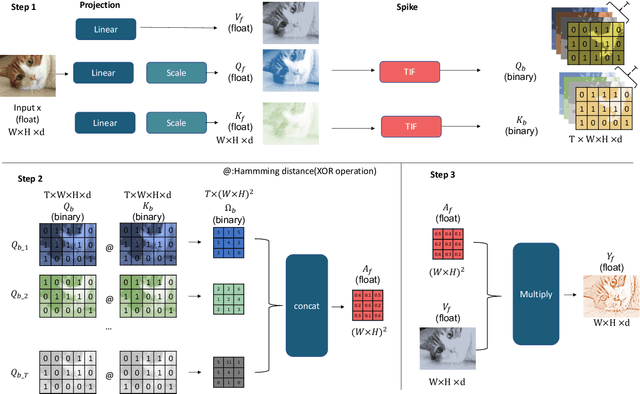

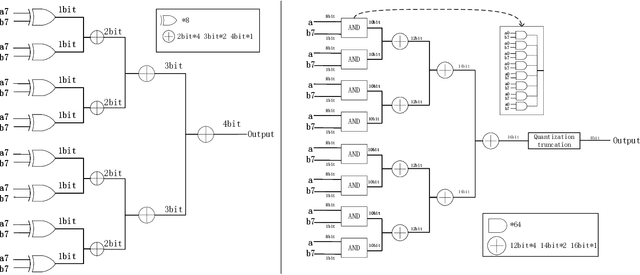
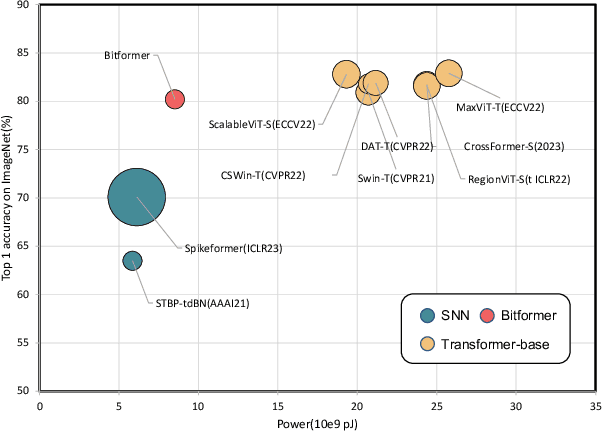
In the current landscape of large models, the Transformer stands as a cornerstone, playing a pivotal role in shaping the trajectory of modern models. However, its application encounters challenges attributed to the substantial computational intricacies intrinsic to its attention mechanism. Moreover, its reliance on high-precision floating-point operations presents specific hurdles, particularly evident in computation-intensive scenarios such as edge computing environments. These environments, characterized by resource-constrained devices and a preference for lower precision, necessitate innovative solutions. To tackle the exacting data processing demands posed by edge devices, we introduce the Bitformer model, an inventive extension of the Transformer paradigm. Central to this innovation is a novel attention mechanism that adeptly replaces conventional floating-point matrix multiplication with bitwise operations. This strategic substitution yields dual advantages. Not only does it maintain the attention mechanism's prowess in capturing intricate long-range information dependencies, but it also orchestrates a profound reduction in the computational complexity inherent in the attention operation. The transition from an $O(n^2d)$ complexity, typical of floating-point operations, to an $O(n^2T)$ complexity characterizing bitwise operations, substantiates this advantage. Notably, in this context, the parameter $T$ remains markedly smaller than the conventional dimensionality parameter $d$. The Bitformer model in essence endeavors to reconcile the indomitable requirements of modern computing landscapes with the constraints posed by edge computing scenarios. By forging this innovative path, we bridge the gap between high-performing models and resource-scarce environments, thus unveiling a promising trajectory for further advancements in the field.