 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$R_\text{dm}$: Re-conceptualizing Distribution Matching as a Reward for Diffusion Distillation
Mar 31, 2026Diffusion models achieve state-of-the-art generative performance but are fundamentally bottlenecked by their slow, iterative sampling process. While diffusion distillation techniques enable high-fidelity, few-step generation, traditional objectives often restrict the student's performance by anchoring it solely to the teacher. Recent approaches have attempted to break this ceiling by integrating Reinforcement Learning (RL), typically through a simple summation of distillation and RL objectives. In this work, we propose a novel paradigm by re-conceptualizing distribution matching as a reward, denoted as $R_\text{dm}$. This unified perspective bridges the algorithmic gap between Diffusion Matching Distillation (DMD) and RL, providing several primary benefits. (1) Enhanced Optimization Stability: We introduce Group Normalized Distribution Matching (GNDM), which adapts standard RL group normalization to stabilize $R_\text{dm}$ estimation. By leveraging group-mean statistics, GNDM establishes a more robust and effective optimization direction. (2) Seamless Reward Integration: Our reward-centric formulation inherently supports adaptive weighting mechanisms, allowing for the fluid combination of DMD with external reward models. (3) Improved Sampling Efficiency: By aligning with RL principles, the framework readily incorporates Importance Sampling (IS), leading to a significant boost in sampling efficiency. Extensive experiments demonstrate that GNDM outperforms vanilla DMD, reducing the FID by 1.87. Furthermore, our multi-reward variant, GNDMR, surpasses existing baselines by striking an optimal balance between aesthetic quality and fidelity, achieving a peak HPS of 30.37 and a low FID-SD of 12.21. Ultimately, $R_\text{dm}$ provides a flexible, stable, and efficient framework for real-time, high-fidelity synthesis. Codes are coming soon.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
UNIV: Unified Foundation Model for Infrared and Visible Modalities
Sep 19, 2025The demand for joint RGB-visible and infrared perception is growing rapidly, particularly to achieve robust performance under diverse weather conditions. Although pre-trained models for RGB-visible and infrared data excel in their respective domains, they often underperform in multimodal scenarios, such as autonomous vehicles equipped with both sensors. To address this challenge, we propose a biologically inspired UNified foundation model for Infrared and Visible modalities (UNIV), featuring two key innovations. First, we introduce Patch-wise Cross-modality Contrastive Learning (PCCL), an attention-guided distillation framework that mimics retinal horizontal cells' lateral inhibition, which enables effective cross-modal feature alignment while remaining compatible with any transformer-based architecture. Second, our dual-knowledge preservation mechanism emulates the retina's bipolar cell signal routing - combining LoRA adapters (2% added parameters) with synchronous distillation to prevent catastrophic forgetting, thereby replicating the retina's photopic (cone-driven) and scotopic (rod-driven) functionality. To support cross-modal learning, we introduce the MVIP dataset, the most comprehensive visible-infrared benchmark to date. It contains 98,992 precisely aligned image pairs spanning diverse scenarios. Extensive experiments demonstrate UNIV's superior performance on infrared tasks (+1.7 mIoU in semantic segmentation and +0.7 mAP in object detection) while maintaining 99%+ of the baseline performance on visible RGB tasks. Our code is available at https://github.com/fangyuanmao/UNIV.
MASTER: Multimodal Segmentation with Text Prompts
Mar 06, 2025



RGB-Thermal fusion is a potential solution for various weather and light conditions in challenging scenarios. However, plenty of studies focus on designing complex modules to fuse different modalities. With the widespread application of large language models (LLMs), valuable information can be more effectively extracted from natural language. Therefore, we aim to leverage the advantages of large language models to design a structurally simple and highly adaptable multimodal fusion model architecture. We proposed MultimodAl Segmentation with TExt PRompts (MASTER) architecture, which integrates LLM into the fusion of RGB-Thermal multimodal data and allows complex query text to participate in the fusion process. Our model utilizes a dual-path structure to extract information from different modalities of images. Additionally, we employ LLM as the core module for multimodal fusion, enabling the model to generate learnable codebook tokens from RGB, thermal images, and textual information. A lightweight image decoder is used to obtain semantic segmentation results. The proposed MASTER performs exceptionally well in benchmark tests across various automated driving scenarios, yielding promising results.
PID: Physics-Informed Diffusion Model for Infrared Image Generation
Jul 12, 2024



Infrared imaging technology has gained significant attention for its reliable sensing ability in low visibility conditions, prompting many studies to convert the abundant RGB images to infrared images. However, most existing image translation methods treat infrared images as a stylistic variation, neglecting the underlying physical laws, which limits their practical application. To address these issues, we propose a Physics-Informed Diffusion (PID) model for translating RGB images to infrared images that adhere to physical laws. Our method leverages the iterative optimization of the diffusion model and incorporates strong physical constraints based on prior knowledge of infrared laws during training. This approach enhances the similarity between translated infrared images and the real infrared domain without increasing extra training parameters. Experimental results demonstrate that PID significantly outperforms existing state-of-the-art methods. Our code is available at https://github.com/fangyuanmao/PID.
PA&DA: Jointly Sampling PAth and DAta for Consistent NAS
Feb 28, 2023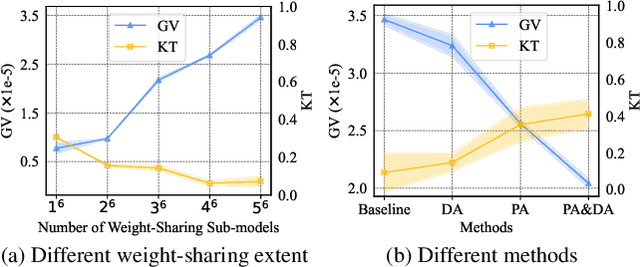
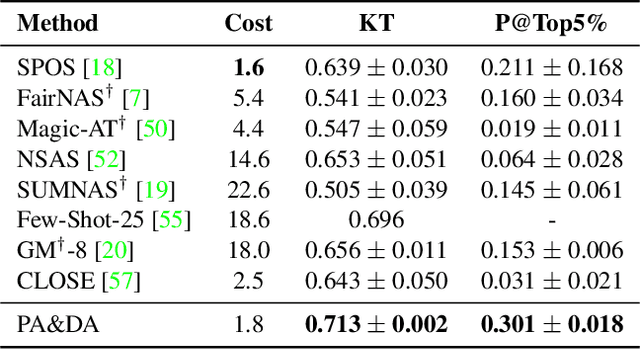
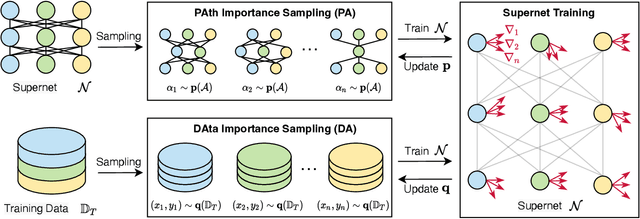

Based on the weight-sharing mechanism, one-shot NAS methods train a supernet and then inherit the pre-trained weights to evaluate sub-models, largely reducing the search cost. However, several works have pointed out that the shared weights suffer from different gradient descent directions during training. And we further find that large gradient variance occurs during supernet training, which degrades the supernet ranking consistency. To mitigate this issue, we propose to explicitly minimize the gradient variance of the supernet training by jointly optimizing the sampling distributions of PAth and DAta (PA&DA). We theoretically derive the relationship between the gradient variance and the sampling distributions, and reveal that the optimal sampling probability is proportional to the normalized gradient norm of path and training data. Hence, we use the normalized gradient norm as the importance indicator for path and training data, and adopt an importance sampling strategy for the supernet training. Our method only requires negligible computation cost for optimizing the sampling distributions of path and data, but achieves lower gradient variance during supernet training and better generalization performance for the supernet, resulting in a more consistent NAS. We conduct comprehensive comparisons with other improved approaches in various search spaces. Results show that our method surpasses others with more reliable ranking performance and higher accuracy of searched architectures, showing the effectiveness of our method. Code is available at https://github.com/ShunLu91/PA-DA.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021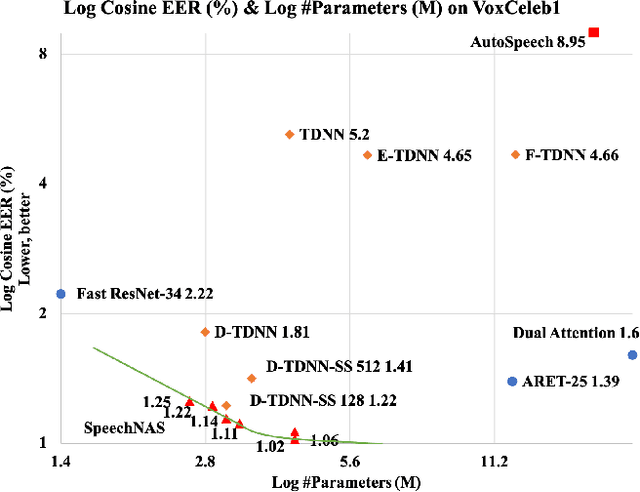
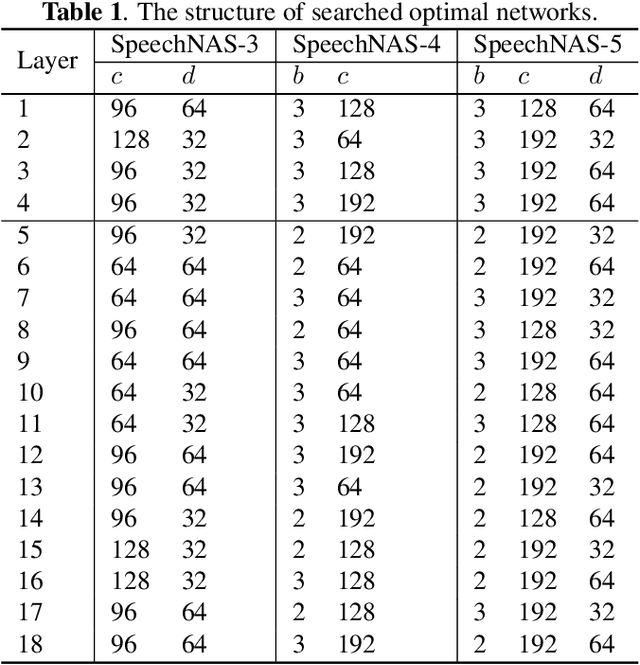
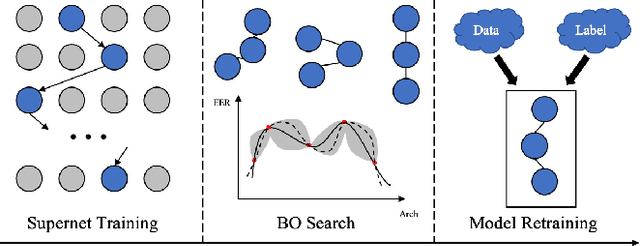
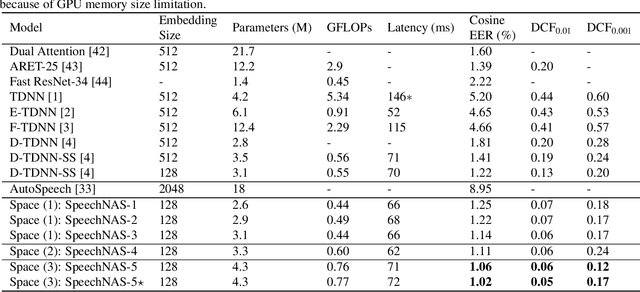
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
DARTS-: Robustly Stepping out of Performance Collapse Without Indicators
Sep 02, 2020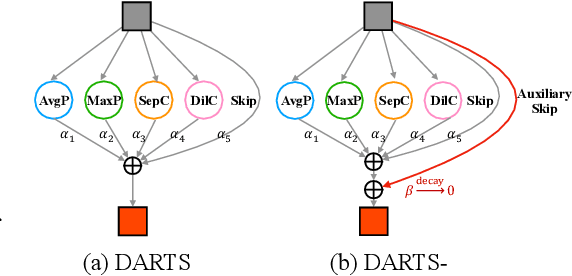
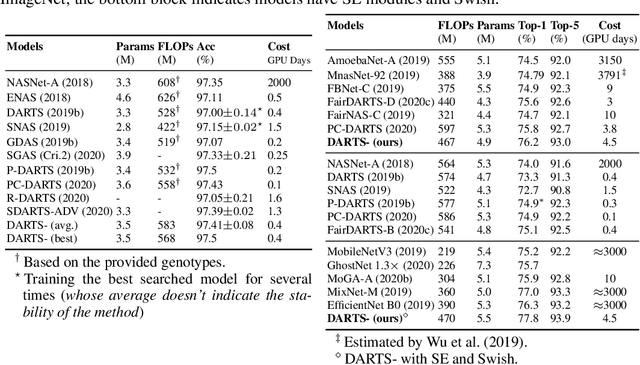

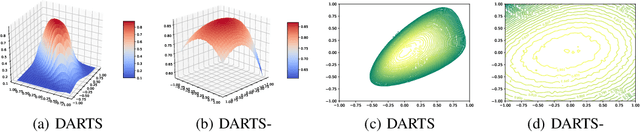
Despite the fast development of differentiable architecture search (DARTS), it suffers from a standing instability issue regarding searching performance, which extremely limits its application. Existing robustifying methods draw clues from the outcome instead of finding out the causing factor. Various indicators such as Hessian eigenvalues are proposed as a signal of performance collapse, and the searching should be stopped once an indicator reaches a preset threshold. However, these methods tend to easily reject good architectures if thresholds are inappropriately set, let alone the searching is intrinsically noisy. In this paper, we undertake a more subtle and direct approach to resolve the collapse. We first demonstrate that skip connections with a learnable architectural coefficient can easily recover from a disadvantageous state and become dominant. We conjecture that skip connections profit too much from this privilege, hence causing the collapse for the derived model. Therefore, we propose to factor out this benefit with an auxiliary skip connection, ensuring a fairer competition for all operations. Extensive experiments on various datasets verify that our approach can substantially improve the robustness of DARTS.