 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
Dec 10, 2025Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into Large Language Models (LLMs), typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.
FGNet: Leveraging Feature-Guided Attention to Refine SAM2 for 3D EM Neuron Segmentation
Nov 17, 2025Accurate segmentation of neural structures in Electron Microscopy (EM) images is paramount for neuroscience. However, this task is challenged by intricate morphologies, low signal-to-noise ratios, and scarce annotations, limiting the accuracy and generalization of existing methods. To address these challenges, we seek to leverage the priors learned by visual foundation models on a vast amount of natural images to better tackle this task. Specifically, we propose a novel framework that can effectively transfer knowledge from Segment Anything 2 (SAM2), which is pre-trained on natural images, to the EM domain. We first use SAM2 to extract powerful, general-purpose features. To bridge the domain gap, we introduce a Feature-Guided Attention module that leverages semantic cues from SAM2 to guide a lightweight encoder, the Fine-Grained Encoder (FGE), in focusing on these challenging regions. Finally, a dual-affinity decoder generates both coarse and refined affinity maps. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art (SOTA) approaches with the SAM2 weights frozen. Upon further fine-tuning on EM data, our method significantly outperforms existing SOTA methods. This study validates that transferring representations pre-trained on natural images, when combined with targeted domain-adaptive guidance, can effectively address the specific challenges in neuron segmentation.
Memorization in Large Language Models in Medicine: Prevalence, Characteristics, and Implications
Sep 10, 2025Large Language Models (LLMs) have demonstrated significant potential in medicine. To date, LLMs have been widely applied to tasks such as diagnostic assistance, medical question answering, and clinical information synthesis. However, a key open question remains: to what extent do LLMs memorize medical training data. In this study, we present the first comprehensive evaluation of memorization of LLMs in medicine, assessing its prevalence (how frequently it occurs), characteristics (what is memorized), volume (how much content is memorized), and potential downstream impacts (how memorization may affect medical applications). We systematically analyze common adaptation scenarios: (1) continued pretraining on medical corpora, (2) fine-tuning on standard medical benchmarks, and (3) fine-tuning on real-world clinical data, including over 13,000 unique inpatient records from Yale New Haven Health System. The results demonstrate that memorization is prevalent across all adaptation scenarios and significantly higher than reported in the general domain. Memorization affects both the development and adoption of LLMs in medicine and can be categorized into three types: beneficial (e.g., accurate recall of clinical guidelines and biomedical references), uninformative (e.g., repeated disclaimers or templated medical document language), and harmful (e.g., regeneration of dataset-specific or sensitive clinical content). Based on these findings, we offer practical recommendations to facilitate beneficial memorization that enhances domain-specific reasoning and factual accuracy, minimize uninformative memorization to promote deeper learning beyond surface-level patterns, and mitigate harmful memorization to prevent the leakage of sensitive or identifiable patient information.
WebArXiv: Evaluating Multimodal Agents on Time-Invariant arXiv Tasks
Jul 01, 2025Recent progress in large language models (LLMs) has enabled the development of autonomous web agents capable of navigating and interacting with real websites. However, evaluating such agents remains challenging due to the instability and inconsistency of existing benchmarks, which often rely on dynamic content or oversimplified simulations. In this work, we introduce WebArXiv, a static and time-invariant benchmark comprising 275 web-based tasks grounded in the arXiv platform. WebArXiv ensures reproducible and reliable evaluation by anchoring tasks in fixed web snapshots with deterministic ground truths and standardized action trajectories. Through behavioral analysis, we identify a common failure mode, Rigid History Reflection, where agents over-rely on fixed interaction histories. To address this, we propose a lightweight dynamic reflection mechanism that allows agents to selectively retrieve relevant past steps during decision-making. We evaluate ten state-of-the-art web agents on WebArXiv. Results demonstrate clear performance differences across agents and validate the effectiveness of our proposed reflection strategy.
Data Contamination Can Cross Language Barriers
Jun 19, 2024The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be \emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from \url{https://github.com/ShangDataLab/Deep-Contam}.
PA&DA: Jointly Sampling PAth and DAta for Consistent NAS
Feb 28, 2023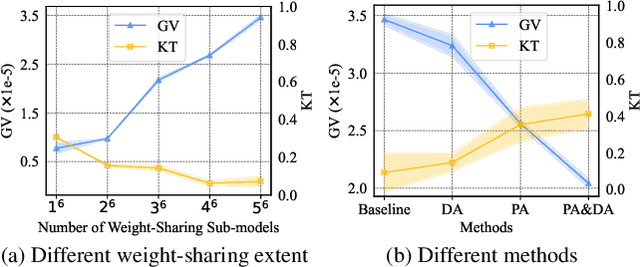
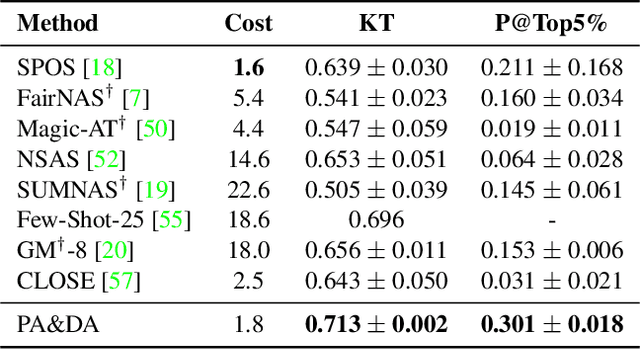
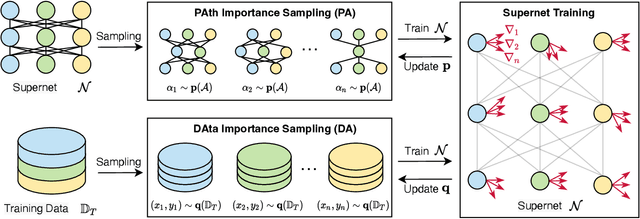

Based on the weight-sharing mechanism, one-shot NAS methods train a supernet and then inherit the pre-trained weights to evaluate sub-models, largely reducing the search cost. However, several works have pointed out that the shared weights suffer from different gradient descent directions during training. And we further find that large gradient variance occurs during supernet training, which degrades the supernet ranking consistency. To mitigate this issue, we propose to explicitly minimize the gradient variance of the supernet training by jointly optimizing the sampling distributions of PAth and DAta (PA&DA). We theoretically derive the relationship between the gradient variance and the sampling distributions, and reveal that the optimal sampling probability is proportional to the normalized gradient norm of path and training data. Hence, we use the normalized gradient norm as the importance indicator for path and training data, and adopt an importance sampling strategy for the supernet training. Our method only requires negligible computation cost for optimizing the sampling distributions of path and data, but achieves lower gradient variance during supernet training and better generalization performance for the supernet, resulting in a more consistent NAS. We conduct comprehensive comparisons with other improved approaches in various search spaces. Results show that our method surpasses others with more reliable ranking performance and higher accuracy of searched architectures, showing the effectiveness of our method. Code is available at https://github.com/ShunLu91/PA-DA.
ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation
Jan 27, 2022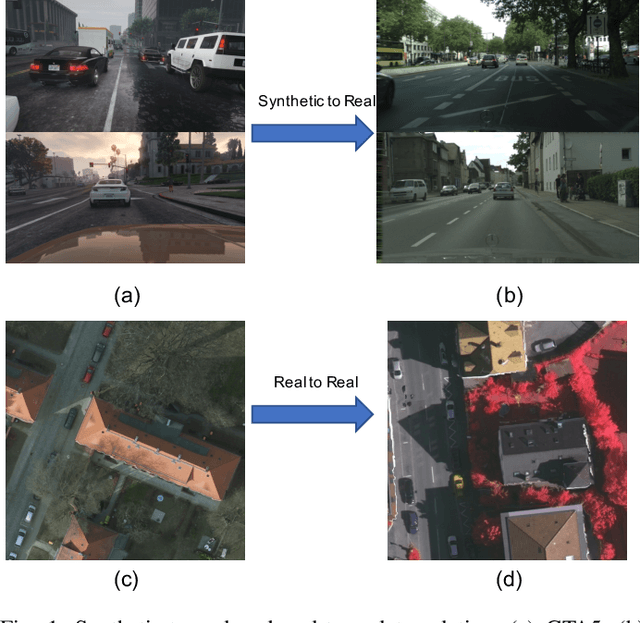
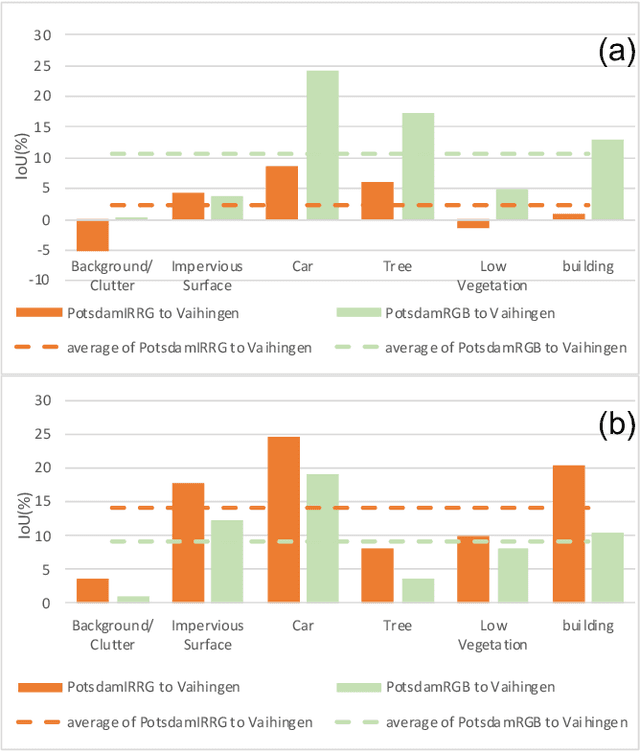
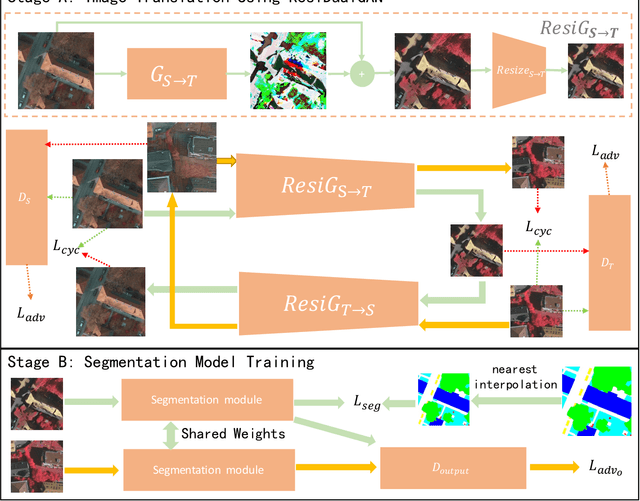

The performance of a semantic segmentation model for remote sensing (RS) images pretrained on an annotated dataset would greatly decrease when testing on another unannotated dataset because of the domain gap. Adversarial generative methods, e.g., DualGAN, are utilized for unpaired image-to-image translation to minimize the pixel-level domain gap, which is one of the common approaches for unsupervised domain adaptation (UDA). However, existing image translation methods are facing two problems when performing RS images translation: 1) ignoring the scale discrepancy between two RS datasets which greatly affect the accuracy performance of scale-invariant objects, 2) ignoring the characteristic of real-to-real translation of RS images which brings an unstable factor for the training of the models. In this paper, ResiDualGAN is proposed for RS images translation, where a resizer module is used for addressing the scale discrepancy of RS datasets, and a residual connection is used for strengthening the stability of real-to-real images translation and improving the performance in cross-domain semantic segmentation tasks. Combining with an output space adaptation method, the proposed method greatly improves the accuracy performance on common benchmarks, which demonstrates the superiority and reliability of ResiDuanGAN. At the end of the paper, a thorough discussion is also conducted to give a reasonable explanation for the improvement of ResiDualGAN.