 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Finance: The Influence of Artificial Intelligence (AI) and Machine Learning (ML)
Oct 21, 2024With rapid transformation of technologies, the fusion of Artificial Intelligence (AI) and Machine Learning (ML) in finance is disrupting the entire ecosystem and operations which were followed for decades. The current landscape is where decisions are increasingly data-driven by financial institutions with an appetite for automation while mitigating risks. The segments of financial institutions which are getting heavily influenced are retail banking, wealth management, corporate banking & payment ecosystem. The solution ranges from onboarding the customers all the way fraud detection & prevention to enhancing the customer services. Financial Institutes are leap frogging with integration of Artificial Intelligence and Machine Learning in mainstream applications and enhancing operational efficiency through advanced predictive analytics, extending personalized customer experiences, and automation to minimize risk with fraud detection techniques. However, with Adoption of AI & ML, it is imperative that the financial institute also needs to address ethical and regulatory challenges, by putting in place robust governance frameworks and responsible AI practices.
* 10 pages, 1 figure
AI-Driven Innovations in Modern Cloud Computing
Oct 21, 2024The world has witnessed rapid technological transformation, past couple of decades and with Advent of Cloud computing the landscape evolved exponentially leading to efficient and scalable application development. Now, the past couple of years the digital ecosystem has brought in numerous innovations with integration of Artificial Intelligence commonly known as AI. This paper explores how AI and cloud computing intersect to deliver transformative capabilities for modernizing applications by providing services and infrastructure. Harnessing the combined potential of both AI & Cloud technologies, technology providers can now exploit intelligent resource management, predictive analytics, automated deployment & scaling with enhanced security leading to offering innovative solutions to their customers. Furthermore, by leveraging such technologies of cloud & AI businesses can reap rich rewards in the form of reducing operational costs and improving service delivery. This paper further addresses challenges associated such as data privacy concerns and how it can be mitigated with robust AI governance frameworks.
* 5 pages, 3 figures
Data Contamination Can Cross Language Barriers
Jun 19, 2024The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be \emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from \url{https://github.com/ShangDataLab/Deep-Contam}.
Beyond Scaling: Predicting Patent Approval with Domain-specific Fine-grained Claim Dependency Graph
Apr 22, 2024Model scaling is becoming the default choice for many language tasks due to the success of large language models (LLMs). However, it can fall short in specific scenarios where simple customized methods excel. In this paper, we delve into the patent approval pre-diction task and unveil that simple domain-specific graph methods outperform enlarging the model, using the intrinsic dependencies within the patent data. Specifically, we first extend the embedding-based state-of-the-art (SOTA) by scaling up its backbone model with various sizes of open-source LLMs, then explore prompt-based methods to harness proprietary LLMs' potential, but find the best results close to random guessing, underlining the ineffectiveness of model scaling-up. Hence, we propose a novel Fine-grained cLAim depeNdency (FLAN) Graph through meticulous patent data analyses, capturing the inherent dependencies across segments of the patent text. As it is model-agnostic, we apply cost-effective graph models to our FLAN Graph to obtain representations for approval prediction. Extensive experiments and detailed analyses prove that incorporating FLAN Graph via various graph models consistently outperforms all LLM baselines significantly. We hope that our observations and analyses in this paper can bring more attention to this challenging task and prompt further research into the limitations of LLMs. Our source code and dataset can be obtained from http://github.com/ShangDataLab/FLAN-Graph.
Signal Reconstruction from Quantized Noisy Samples of the Discrete Fourier Transform
Jan 09, 2022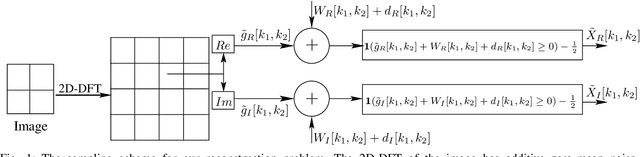

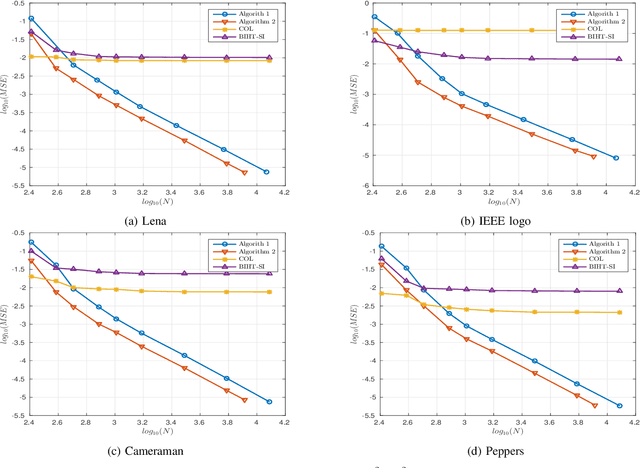

In this paper, we present two variations of an algorithm for signal reconstruction from one-bit or two-bit noisy observations of the discrete Fourier transform (DFT). The one-bit observations of the DFT correspond to the sign of its real part, whereas, the two-bit observations of the DFT correspond to the signs of both the real and imaginary parts of the DFT. We focus on images for analysis and simulations, thus using the sign of the 2D-DFT. This choice of the class of signals is inspired by previous works on this problem. For our algorithm, we show that the expected mean squared error (MSE) in signal reconstruction is asymptotically proportional to the inverse of the sampling rate. The samples are affected by additive zero-mean noise of known distribution. We solve this signal estimation problem by designing an algorithm that uses contraction mapping, based on the Banach fixed point theorem. Numerical tests with four benchmark images are provided to show the effectiveness of our algorithm. Various metrics for image reconstruction quality assessment such as PSNR, SSIM, ESSIM, and MS-SSIM are employed. On all four benchmark images, our algorithm outperforms the state-of-the-art in all of these metrics by a significant margin.
Estimation of Bandlimited Grayscale Images From the Single Bit Observations of Pixels Affected by Additive Gaussian Noise
Oct 27, 2016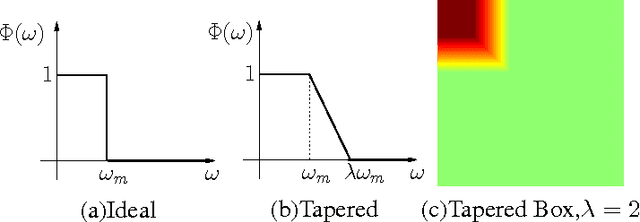
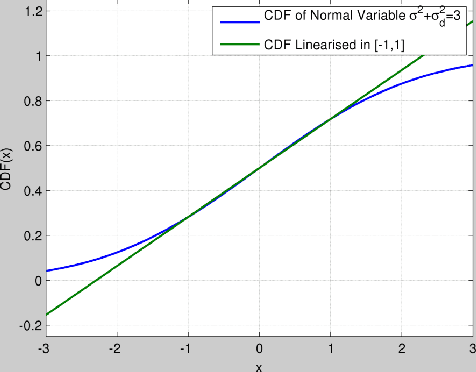
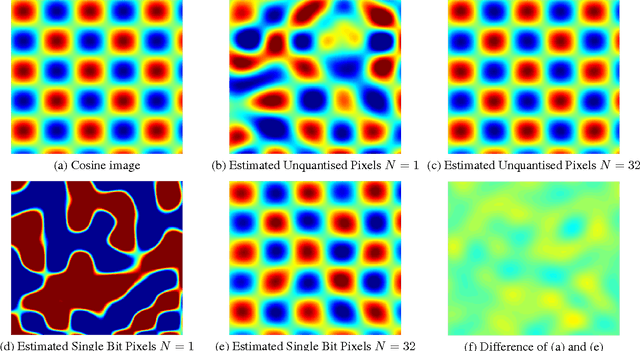

The estimation of grayscale images using their single-bit zero mean Gaussian noise-affected pixels is presented in this paper. The images are assumed to be bandlimited in the Fourier Cosine transform (FCT) domain. The images are oversampled over their Nyquist rate in the FCT domain. We propose a non-recursive approach based on first order approximation of Cumulative Distribution Function (CDF) to estimate the image from single bit pixels which itself is based on Banach's contraction theorem. The decay rate for mean squared error of estimating such images is found to be independent of the precision of the quantizer and it varies as $O(1/N)$ where $N$ is the "effective" oversampling ratio with respect to the Nyquist rate in the FCT domain.