 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Apr 30, 2025
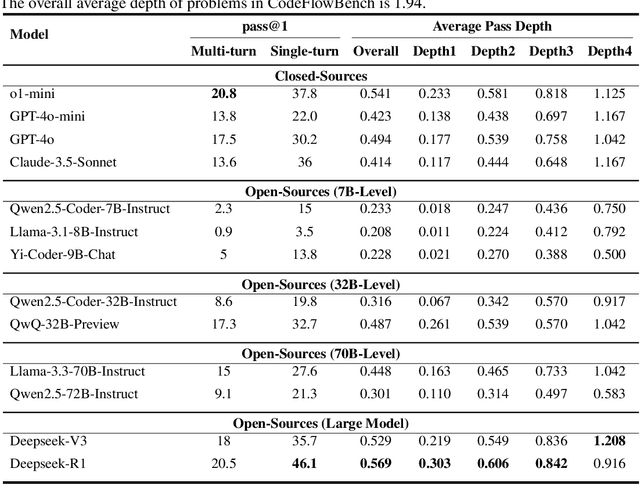


Real world development demands code that is readable, extensible, and testable by organizing the implementation into modular components and iteratively reuse pre-implemented code. We term this iterative, multi-turn process codeflow and introduce CodeFlowBench, the first benchmark designed for comprehensively evaluating LLMs' ability to perform codeflow, namely to implement new functionality by reusing existing functions over multiple turns. CodeFlowBench comprises 5258 problems drawn from Codeforces and is continuously updated via an automated pipeline that decomposes each problem into a series of function-level subproblems based on its dependency tree and each subproblem is paired with unit tests. We further propose a novel evaluation framework with tasks and metrics tailored to multi-turn code reuse to assess model performance. In experiments across various LLMs under both multi-turn and single-turn patterns. We observe models' poor performance on CodeFlowBench, with a substantial performance drop in the iterative codeflow scenario. For instance, o1-mini achieves a pass@1 of 20.8% in multi-turn pattern versus 37.8% in single-turn pattern. Further analysis shows that different models excel at different dependency depths, yet all struggle to correctly solve structurally complex problems, highlighting challenges for current LLMs to serve as code generation tools when performing codeflow. Overall, CodeFlowBench offers a comprehensive benchmark and new insights into LLM capabilities for multi-turn, iterative code generation, guiding future advances in code generation tasks.
RARE: Retrieval-Augmented Reasoning Modeling
Mar 30, 2025Domain-specific intelligence demands specialized knowledge and sophisticated reasoning for problem-solving, posing significant challenges for large language models (LLMs) that struggle with knowledge hallucination and inadequate reasoning capabilities under constrained parameter budgets. Inspired by Bloom's Taxonomy in educational theory, we propose Retrieval-Augmented Reasoning Modeling (RARE), a novel paradigm that decouples knowledge storage from reasoning optimization. RARE externalizes domain knowledge to retrievable sources and internalizes domain-specific reasoning patterns during training. Specifically, by injecting retrieved knowledge into training prompts, RARE transforms learning objectives from rote memorization to contextualized reasoning application. It enables models to bypass parameter-intensive memorization and prioritize the development of higher-order cognitive processes. Our experiments demonstrate that lightweight RARE-trained models (e.g., Llama-3.1-8B) could achieve state-of-the-art performance, surpassing retrieval-augmented GPT-4 and Deepseek-R1 distilled counterparts. RARE establishes a paradigm shift where maintainable external knowledge bases synergize with compact, reasoning-optimized models, collectively driving more scalable domain-specific intelligence. Repo: https://github.com/Open-DataFlow/RARE