 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Apr 30, 2025
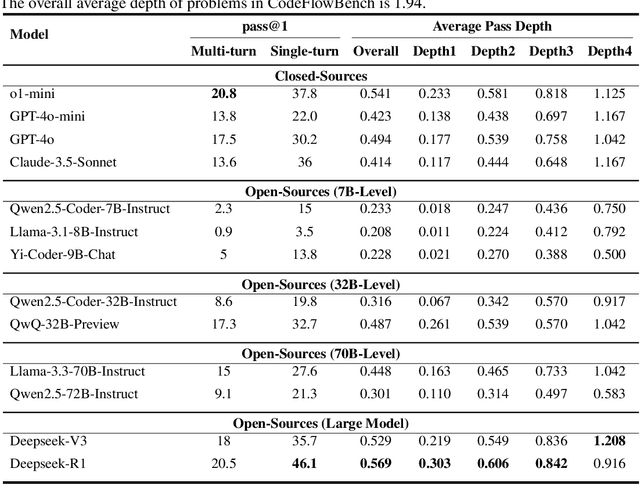


Real world development demands code that is readable, extensible, and testable by organizing the implementation into modular components and iteratively reuse pre-implemented code. We term this iterative, multi-turn process codeflow and introduce CodeFlowBench, the first benchmark designed for comprehensively evaluating LLMs' ability to perform codeflow, namely to implement new functionality by reusing existing functions over multiple turns. CodeFlowBench comprises 5258 problems drawn from Codeforces and is continuously updated via an automated pipeline that decomposes each problem into a series of function-level subproblems based on its dependency tree and each subproblem is paired with unit tests. We further propose a novel evaluation framework with tasks and metrics tailored to multi-turn code reuse to assess model performance. In experiments across various LLMs under both multi-turn and single-turn patterns. We observe models' poor performance on CodeFlowBench, with a substantial performance drop in the iterative codeflow scenario. For instance, o1-mini achieves a pass@1 of 20.8% in multi-turn pattern versus 37.8% in single-turn pattern. Further analysis shows that different models excel at different dependency depths, yet all struggle to correctly solve structurally complex problems, highlighting challenges for current LLMs to serve as code generation tools when performing codeflow. Overall, CodeFlowBench offers a comprehensive benchmark and new insights into LLM capabilities for multi-turn, iterative code generation, guiding future advances in code generation tasks.
MaintainCoder: Maintainable Code Generation Under Dynamic Requirements
Mar 31, 2025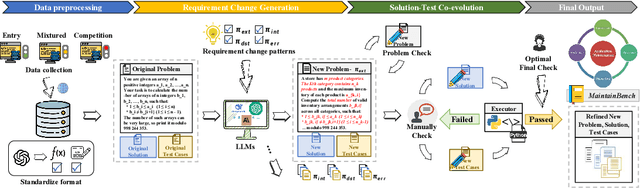
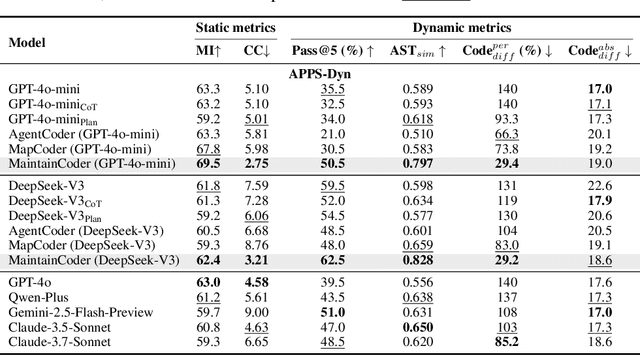
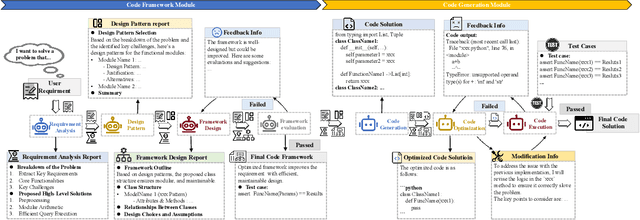
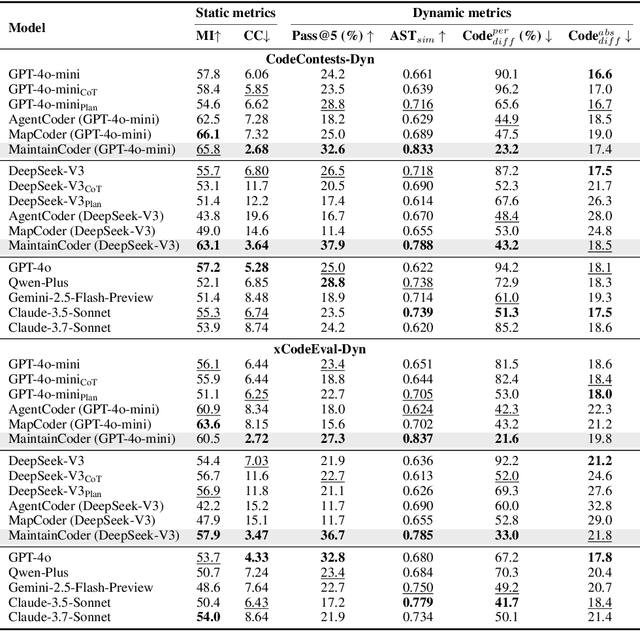
Modern code generation has made significant strides in functional correctness and execution efficiency. However, these systems often overlook a critical dimension in real-world software development: maintainability. To handle dynamic requirements with minimal rework, we propose MaintainCoder as a pioneering solution. It integrates Waterfall model, design patterns, and multi-agent collaboration to systematically enhance cohesion, reduce coupling, and improve adaptability. We also introduce MaintainBench, a benchmark comprising requirement changes and corresponding dynamic metrics on maintainance effort. Experiments demonstrate that existing code generation methods struggle to meet maintainability standards when requirements evolve. In contrast, MaintainCoder improves maintainability metrics by 14-30% with even higher correctness, i.e. pass@k. Our work not only provides the foundation of maintainable code generation, but also highlights the need for more holistic code quality research. Resources: https://github.com/IAAR-Shanghai/MaintainCoder.
Unleashing the Temporal-Spatial Reasoning Capacity of GPT for Training-Free Audio and Language Referenced Video Object Segmentation
Aug 28, 2024



In this paper, we propose an Audio-Language-Referenced SAM 2 (AL-Ref-SAM 2) pipeline to explore the training-free paradigm for audio and language-referenced video object segmentation, namely AVS and RVOS tasks. The intuitive solution leverages GroundingDINO to identify the target object from a single frame and SAM 2 to segment the identified object throughout the video, which is less robust to spatiotemporal variations due to a lack of video context exploration. Thus, in our AL-Ref-SAM 2 pipeline, we propose a novel GPT-assisted Pivot Selection (GPT-PS) module to instruct GPT-4 to perform two-step temporal-spatial reasoning for sequentially selecting pivot frames and pivot boxes, thereby providing SAM 2 with a high-quality initial object prompt. Within GPT-PS, two task-specific Chain-of-Thought prompts are designed to unleash GPT's temporal-spatial reasoning capacity by guiding GPT to make selections based on a comprehensive understanding of video and reference information. Furthermore, we propose a Language-Binded Reference Unification (LBRU) module to convert audio signals into language-formatted references, thereby unifying the formats of AVS and RVOS tasks in the same pipeline. Extensive experiments on both tasks show that our training-free AL-Ref-SAM 2 pipeline achieves performances comparable to or even better than fully-supervised fine-tuning methods. The code is available at: https://github.com/appletea233/AL-Ref-SAM2.