 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoST: Efficient Collaborative Perception From Unified Spatiotemporal Perspective
Aug 01, 2025Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
Knowledge Distillation via Query Selection for Detection Transformer
Sep 10, 2024



Transformers have revolutionized the object detection landscape by introducing DETRs, acclaimed for their simplicity and efficacy. Despite their advantages, the substantial size of these models poses significant challenges for practical deployment, particularly in resource-constrained environments. This paper addresses the challenge of compressing DETR by leveraging knowledge distillation, a technique that holds promise for maintaining model performance while reducing size. A critical aspect of DETRs' performance is their reliance on queries to interpret object representations accurately. Traditional distillation methods often focus exclusively on positive queries, identified through bipartite matching, neglecting the rich information present in hard-negative queries. Our visual analysis indicates that hard-negative queries, focusing on foreground elements, are crucial for enhancing distillation outcomes. To this end, we introduce a novel Group Query Selection strategy, which diverges from traditional query selection in DETR distillation by segmenting queries based on their Generalized Intersection over Union (GIoU) with ground truth objects, thereby uncovering valuable hard-negative queries for distillation. Furthermore, we present the Knowledge Distillation via Query Selection for DETR (QSKD) framework, which incorporates Attention-Guided Feature Distillation (AGFD) and Local Alignment Prediction Distillation (LAPD). These components optimize the distillation process by focusing on the most informative aspects of the teacher model's intermediate features and output. Our comprehensive experimental evaluation of the MS-COCO dataset demonstrates the effectiveness of our approach, significantly improving average precision (AP) across various DETR architectures without incurring substantial computational costs. Specifically, the AP of Conditional DETR ResNet-18 increased from 35.8 to 39.9.
Unleashing the Temporal-Spatial Reasoning Capacity of GPT for Training-Free Audio and Language Referenced Video Object Segmentation
Aug 28, 2024



In this paper, we propose an Audio-Language-Referenced SAM 2 (AL-Ref-SAM 2) pipeline to explore the training-free paradigm for audio and language-referenced video object segmentation, namely AVS and RVOS tasks. The intuitive solution leverages GroundingDINO to identify the target object from a single frame and SAM 2 to segment the identified object throughout the video, which is less robust to spatiotemporal variations due to a lack of video context exploration. Thus, in our AL-Ref-SAM 2 pipeline, we propose a novel GPT-assisted Pivot Selection (GPT-PS) module to instruct GPT-4 to perform two-step temporal-spatial reasoning for sequentially selecting pivot frames and pivot boxes, thereby providing SAM 2 with a high-quality initial object prompt. Within GPT-PS, two task-specific Chain-of-Thought prompts are designed to unleash GPT's temporal-spatial reasoning capacity by guiding GPT to make selections based on a comprehensive understanding of video and reference information. Furthermore, we propose a Language-Binded Reference Unification (LBRU) module to convert audio signals into language-formatted references, thereby unifying the formats of AVS and RVOS tasks in the same pipeline. Extensive experiments on both tasks show that our training-free AL-Ref-SAM 2 pipeline achieves performances comparable to or even better than fully-supervised fine-tuning methods. The code is available at: https://github.com/appletea233/AL-Ref-SAM2.
DETR with Additional Global Aggregation for Cross-domain Weakly Supervised Object Detection
Apr 14, 2023This paper presents a DETR-based method for cross-domain weakly supervised object detection (CDWSOD), aiming at adapting the detector from source to target domain through weak supervision. We think DETR has strong potential for CDWSOD due to an insight: the encoder and the decoder in DETR are both based on the attention mechanism and are thus capable of aggregating semantics across the entire image. The aggregation results, i.e., image-level predictions, can naturally exploit the weak supervision for domain alignment. Such motivated, we propose DETR with additional Global Aggregation (DETR-GA), a CDWSOD detector that simultaneously makes "instance-level + image-level" predictions and utilizes "strong + weak" supervisions. The key point of DETR-GA is very simple: for the encoder / decoder, we respectively add multiple class queries / a foreground query to aggregate the semantics into image-level predictions. Our query-based aggregation has two advantages. First, in the encoder, the weakly-supervised class queries are capable of roughly locating the corresponding positions and excluding the distraction from non-relevant regions. Second, through our design, the object queries and the foreground query in the decoder share consensus on the class semantics, therefore making the strong and weak supervision mutually benefit each other for domain alignment. Extensive experiments on four popular cross-domain benchmarks show that DETR-GA significantly improves CSWSOD and advances the states of the art (e.g., 29.0% --> 79.4% mAP on PASCAL VOC --> Clipart_all dataset).
Human-centric Spatio-Temporal Video Grounding With Visual Transformers
Nov 10, 2020

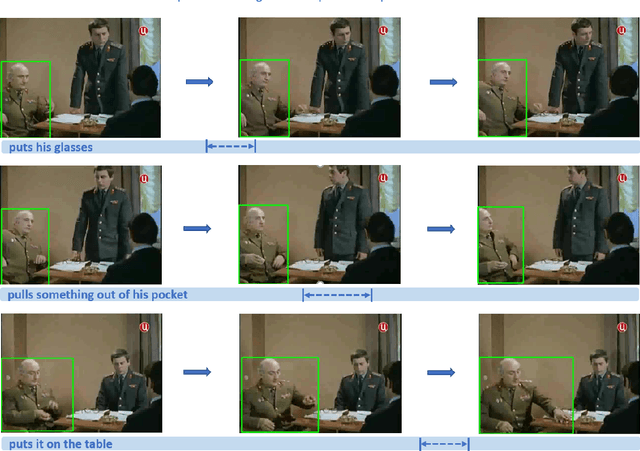
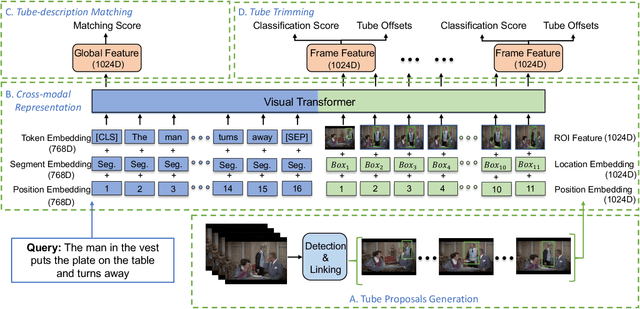
In this work, we introduce a novel task - Humancentric Spatio-Temporal Video Grounding (HC-STVG). Unlike the existing referring expression tasks in images or videos, by focusing on humans, HC-STVG aims to localize a spatiotemporal tube of the target person from an untrimmed video based on a given textural description. This task is useful, especially for healthcare and security-related applications, where the surveillance videos can be extremely long but only a specific person during a specific period of time is concerned. HC-STVG is a video grounding task that requires both spatial (where) and temporal (when) localization. Unfortunately, the existing grounding methods cannot handle this task well. We tackle this task by proposing an effective baseline method named Spatio-Temporal Grounding with Visual Transformers (STGVT), which utilizes Visual Transformers to extract cross-modal representations for video-sentence matching and temporal localization. To facilitate this task, we also contribute an HC-STVG dataset consisting of 5,660 video-sentence pairs on complex multi-person scenes. Specifically, each video lasts for 20 seconds, pairing with a natural query sentence with an average of 17.25 words. Extensive experiments are conducted on this dataset, demonstrating the newly-proposed method outperforms the existing baseline methods.