 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
Jan 14, 2025Recent advancements in multimodal large language models (MLLMs) have shown promising results, yet existing approaches struggle to effectively handle both temporal and spatial localization simultaneously. This challenge stems from two key issues: first, incorporating spatial-temporal localization introduces a vast number of coordinate combinations, complicating the alignment of linguistic and visual coordinate representations; second, encoding fine-grained temporal and spatial information during video feature compression is inherently difficult. To address these issues, we propose LLaVA-ST, a MLLM for fine-grained spatial-temporal multimodal understanding. In LLaVA-ST, we propose Language-Aligned Positional Embedding, which embeds the textual coordinate special token into the visual space, simplifying the alignment of fine-grained spatial-temporal correspondences. Additionally, we design the Spatial-Temporal Packer, which decouples the feature compression of temporal and spatial resolutions into two distinct point-to-region attention processing streams. Furthermore, we propose ST-Align dataset with 4.3M training samples for fine-grained spatial-temporal multimodal understanding. With ST-align, we present a progressive training pipeline that aligns the visual and textual feature through sequential coarse-to-fine stages.Additionally, we introduce an ST-Align benchmark to evaluate spatial-temporal interleaved fine-grained understanding tasks, which include Spatial-Temporal Video Grounding (STVG) , Event Localization and Captioning (ELC) and Spatial Video Grounding (SVG). LLaVA-ST achieves outstanding performance on 11 benchmarks requiring fine-grained temporal, spatial, or spatial-temporal interleaving multimodal understanding. Our code, data and benchmark will be released at Our code, data and benchmark will be released at https://github.com/appletea233/LLaVA-ST .
Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative Grounding
Sep 12, 2024



Panoptic narrative grounding (PNG), whose core target is fine-grained image-text alignment, requires a panoptic segmentation of referred objects given a narrative caption. Previous discriminative methods achieve only weak or coarse-grained alignment by panoptic segmentation pretraining or CLIP model adaptation. Given the recent progress of text-to-image Diffusion models, several works have shown their capability to achieve fine-grained image-text alignment through cross-attention maps and improved general segmentation performance. However, the direct use of phrase features as static prompts to apply frozen Diffusion models to the PNG task still suffers from a large task gap and insufficient vision-language interaction, yielding inferior performance. Therefore, we propose an Extractive-Injective Phrase Adapter (EIPA) bypass within the Diffusion UNet to dynamically update phrase prompts with image features and inject the multimodal cues back, which leverages the fine-grained image-text alignment capability of Diffusion models more sufficiently. In addition, we also design a Multi-Level Mutual Aggregation (MLMA) module to reciprocally fuse multi-level image and phrase features for segmentation refinement. Extensive experiments on the PNG benchmark show that our method achieves new state-of-the-art performance.
Unleashing the Temporal-Spatial Reasoning Capacity of GPT for Training-Free Audio and Language Referenced Video Object Segmentation
Aug 28, 2024



In this paper, we propose an Audio-Language-Referenced SAM 2 (AL-Ref-SAM 2) pipeline to explore the training-free paradigm for audio and language-referenced video object segmentation, namely AVS and RVOS tasks. The intuitive solution leverages GroundingDINO to identify the target object from a single frame and SAM 2 to segment the identified object throughout the video, which is less robust to spatiotemporal variations due to a lack of video context exploration. Thus, in our AL-Ref-SAM 2 pipeline, we propose a novel GPT-assisted Pivot Selection (GPT-PS) module to instruct GPT-4 to perform two-step temporal-spatial reasoning for sequentially selecting pivot frames and pivot boxes, thereby providing SAM 2 with a high-quality initial object prompt. Within GPT-PS, two task-specific Chain-of-Thought prompts are designed to unleash GPT's temporal-spatial reasoning capacity by guiding GPT to make selections based on a comprehensive understanding of video and reference information. Furthermore, we propose a Language-Binded Reference Unification (LBRU) module to convert audio signals into language-formatted references, thereby unifying the formats of AVS and RVOS tasks in the same pipeline. Extensive experiments on both tasks show that our training-free AL-Ref-SAM 2 pipeline achieves performances comparable to or even better than fully-supervised fine-tuning methods. The code is available at: https://github.com/appletea233/AL-Ref-SAM2.
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023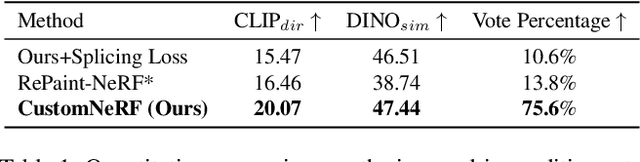
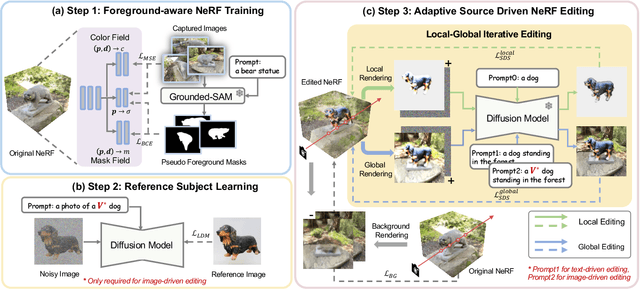


In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.
Cross-Modality Domain Adaptation for Freespace Detection: A Simple yet Effective Baseline
Oct 06, 2022
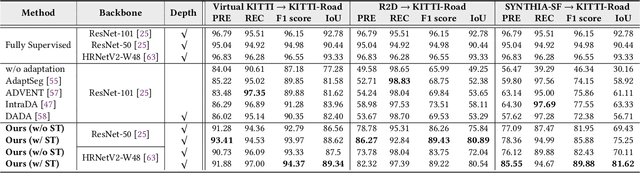
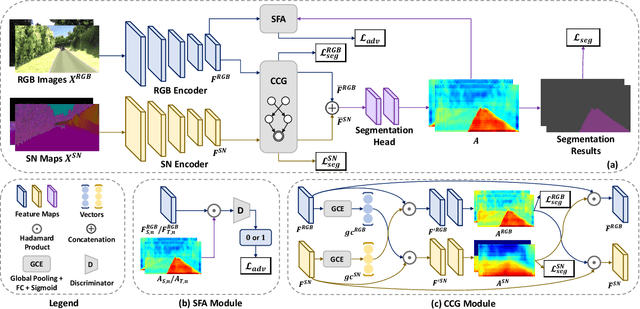
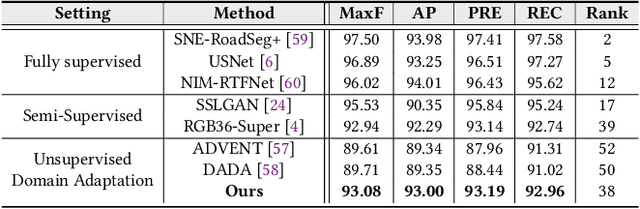
As one of the fundamental functions of autonomous driving system, freespace detection aims at classifying each pixel of the image captured by the camera as drivable or non-drivable. Current works of freespace detection heavily rely on large amount of densely labeled training data for accuracy and robustness, which is time-consuming and laborious to collect and annotate. To the best of our knowledge, we are the first work to explore unsupervised domain adaptation for freespace detection to alleviate the data limitation problem with synthetic data. We develop a cross-modality domain adaptation framework which exploits both RGB images and surface normal maps generated from depth images. A Collaborative Cross Guidance (CCG) module is proposed to leverage the context information of one modality to guide the other modality in a cross manner, thus realizing inter-modality intra-domain complement. To better bridge the domain gap between source domain (synthetic data) and target domain (real-world data), we also propose a Selective Feature Alignment (SFA) module which only aligns the features of consistent foreground area between the two domains, thus realizing inter-domain intra-modality adaptation. Extensive experiments are conducted by adapting three different synthetic datasets to one real-world dataset for freespace detection respectively. Our method performs closely to fully supervised freespace detection methods (93.08 v.s. 97.50 F1 score) and outperforms other general unsupervised domain adaptation methods for semantic segmentation with large margins, which shows the promising potential of domain adaptation for freespace detection.
PPMN: Pixel-Phrase Matching Network for One-Stage Panoptic Narrative Grounding
Aug 11, 2022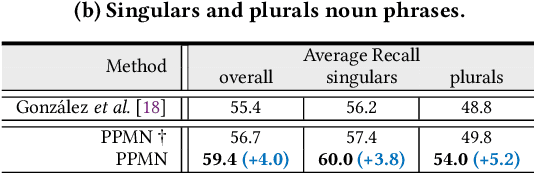
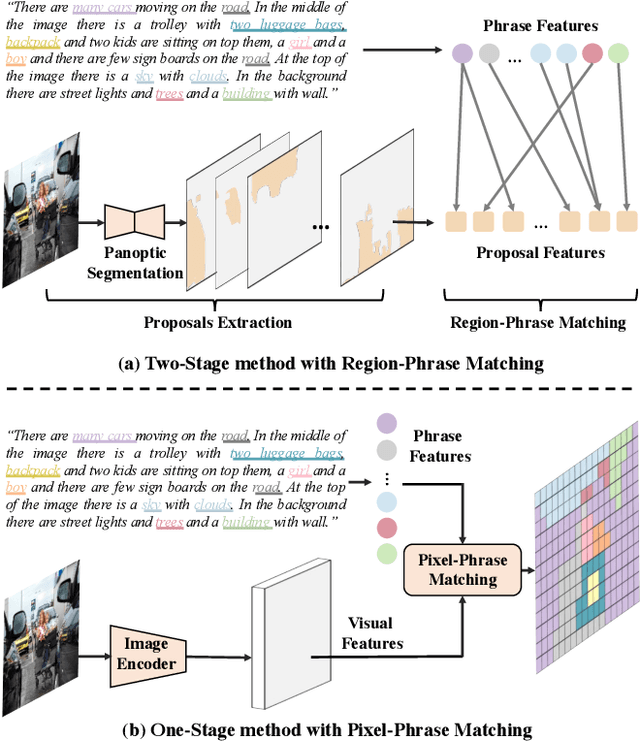
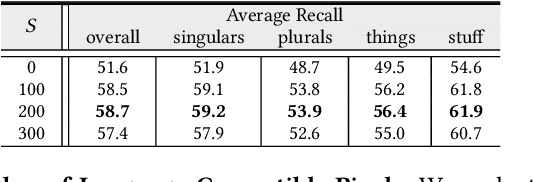
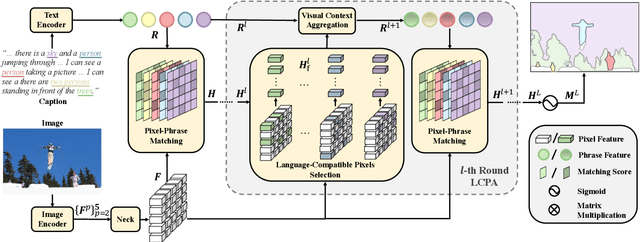
Panoptic Narrative Grounding (PNG) is an emerging task whose goal is to segment visual objects of things and stuff categories described by dense narrative captions of a still image. The previous two-stage approach first extracts segmentation region proposals by an off-the-shelf panoptic segmentation model, then conducts coarse region-phrase matching to ground the candidate regions for each noun phrase. However, the two-stage pipeline usually suffers from the performance limitation of low-quality proposals in the first stage and the loss of spatial details caused by region feature pooling, as well as complicated strategies designed for things and stuff categories separately. To alleviate these drawbacks, we propose a one-stage end-to-end Pixel-Phrase Matching Network (PPMN), which directly matches each phrase to its corresponding pixels instead of region proposals and outputs panoptic segmentation by simple combination. Thus, our model can exploit sufficient and finer cross-modal semantic correspondence from the supervision of densely annotated pixel-phrase pairs rather than sparse region-phrase pairs. In addition, we also propose a Language-Compatible Pixel Aggregation (LCPA) module to further enhance the discriminative ability of phrase features through multi-round refinement, which selects the most compatible pixels for each phrase to adaptively aggregate the corresponding visual context. Extensive experiments show that our method achieves new state-of-the-art performance on the PNG benchmark with 4.0 absolute Average Recall gains.
Language-Bridged Spatial-Temporal Interaction for Referring Video Object Segmentation
Jun 08, 2022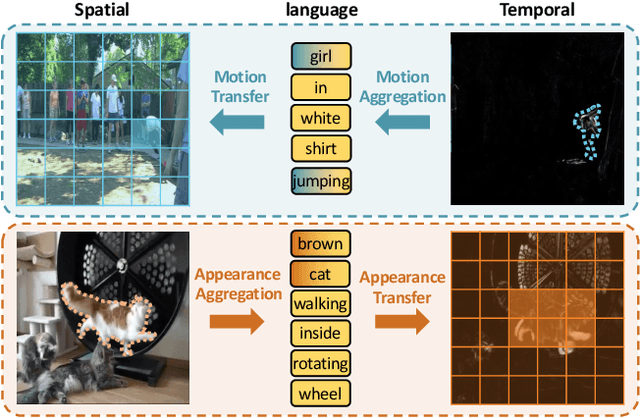
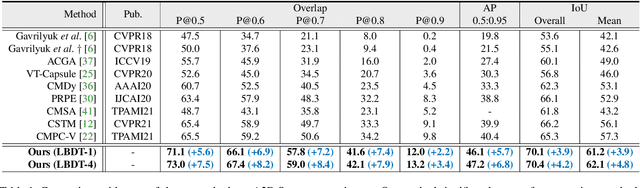
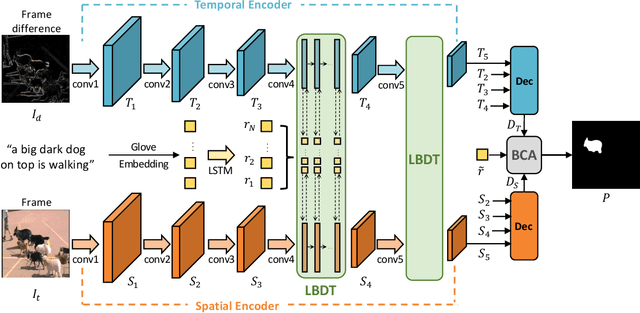
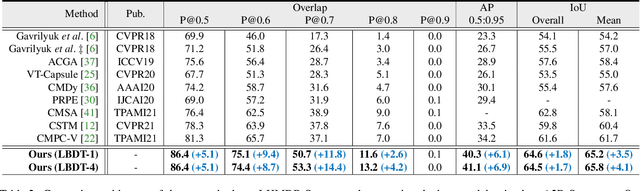
Referring video object segmentation aims to predict foreground labels for objects referred by natural language expressions in videos. Previous methods either depend on 3D ConvNets or incorporate additional 2D ConvNets as encoders to extract mixed spatial-temporal features. However, these methods suffer from spatial misalignment or false distractors due to delayed and implicit spatial-temporal interaction occurring in the decoding phase. To tackle these limitations, we propose a Language-Bridged Duplex Transfer (LBDT) module which utilizes language as an intermediary bridge to accomplish explicit and adaptive spatial-temporal interaction earlier in the encoding phase. Concretely, cross-modal attention is performed among the temporal encoder, referring words and the spatial encoder to aggregate and transfer language-relevant motion and appearance information. In addition, we also propose a Bilateral Channel Activation (BCA) module in the decoding phase for further denoising and highlighting the spatial-temporal consistent features via channel-wise activation. Extensive experiments show our method achieves new state-of-the-art performances on four popular benchmarks with 6.8% and 6.9% absolute AP gains on A2D Sentences and J-HMDB Sentences respectively, while consuming around 7x less computational overhead.
A Keypoint-based Global Association Network for Lane Detection
Apr 15, 2022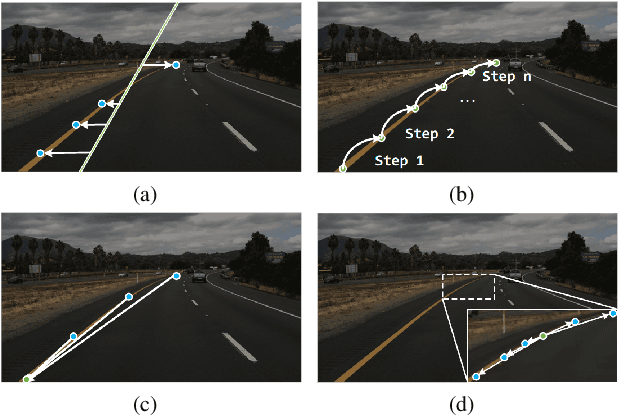

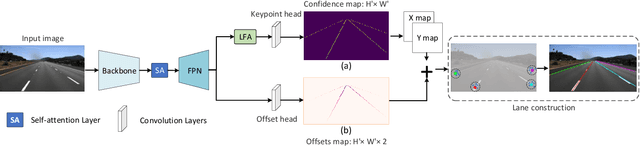
Lane detection is a challenging task that requires predicting complex topology shapes of lane lines and distinguishing different types of lanes simultaneously. Earlier works follow a top-down roadmap to regress predefined anchors into various shapes of lane lines, which lacks enough flexibility to fit complex shapes of lanes due to the fixed anchor shapes. Lately, some works propose to formulate lane detection as a keypoint estimation problem to describe the shapes of lane lines more flexibly and gradually group adjacent keypoints belonging to the same lane line in a point-by-point manner, which is inefficient and time-consuming during postprocessing. In this paper, we propose a Global Association Network (GANet) to formulate the lane detection problem from a new perspective, where each keypoint is directly regressed to the starting point of the lane line instead of point-by-point extension. Concretely, the association of keypoints to their belonged lane line is conducted by predicting their offsets to the corresponding starting points of lanes globally without dependence on each other, which could be done in parallel to greatly improve efficiency. In addition, we further propose a Lane-aware Feature Aggregator (LFA), which adaptively captures the local correlations between adjacent keypoints to supplement local information to the global association. Extensive experiments on two popular lane detection benchmarks show that our method outperforms previous methods with F1 score of 79.63% on CULane and 97.71% on Tusimple dataset with high FPS. The code will be released at https://github.com/Wolfwjs/GANet.
TransRefer3D: Entity-and-Relation Aware Transformer for Fine-Grained 3D Visual Grounding
Aug 11, 2021
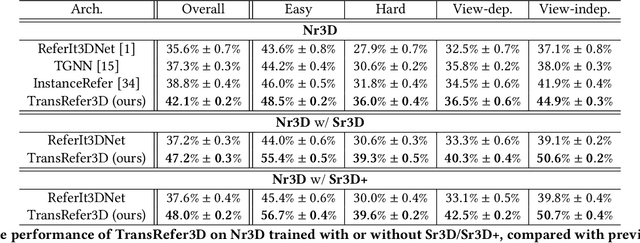
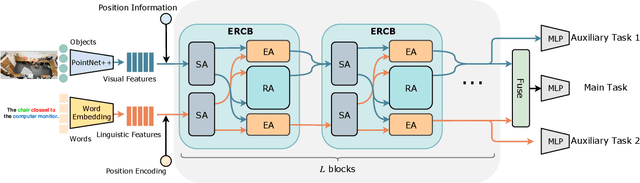

Recently proposed fine-grained 3D visual grounding is an essential and challenging task, whose goal is to identify the 3D object referred by a natural language sentence from other distractive objects of the same category. Existing works usually adopt dynamic graph networks to indirectly model the intra/inter-modal interactions, making the model difficult to distinguish the referred object from distractors due to the monolithic representations of visual and linguistic contents. In this work, we exploit Transformer for its natural suitability on permutation-invariant 3D point clouds data and propose a TransRefer3D network to extract entity-and-relation aware multimodal context among objects for more discriminative feature learning. Concretely, we devise an Entity-aware Attention (EA) module and a Relation-aware Attention (RA) module to conduct fine-grained cross-modal feature matching. Facilitated by co-attention operation, our EA module matches visual entity features with linguistic entity features while RA module matches pair-wise visual relation features with linguistic relation features, respectively. We further integrate EA and RA modules into an Entity-and-Relation aware Contextual Block (ERCB) and stack several ERCBs to form our TransRefer3D for hierarchical multimodal context modeling. Extensive experiments on both Nr3D and Sr3D datasets demonstrate that our proposed model significantly outperforms existing approaches by up to 10.6% and claims the new state-of-the-art. To the best of our knowledge, this is the first work investigating Transformer architecture for fine-grained 3D visual grounding task.