 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMTrack: State-Aware Mamba for Efficient Temporal Modeling in Visual Tracking
Feb 02, 2026Visual tracking aims to automatically estimate the state of a target object in a video sequence, which is challenging especially in dynamic scenarios. Thus, numerous methods are proposed to introduce temporal cues to enhance tracking robustness. However, conventional CNN and Transformer architectures exhibit inherent limitations in modeling long-range temporal dependencies in visual tracking, often necessitating either complex customized modules or substantial computational costs to integrate temporal cues. Inspired by the success of the state space model, we propose a novel temporal modeling paradigm for visual tracking, termed State-aware Mamba Tracker (SMTrack), providing a neat pipeline for training and tracking without needing customized modules or substantial computational costs to build long-range temporal dependencies. It enjoys several merits. First, we propose a novel selective state-aware space model with state-wise parameters to capture more diverse temporal cues for robust tracking. Second, SMTrack facilitates long-range temporal interactions with linear computational complexity during training. Third, SMTrack enables each frame to interact with previously tracked frames via hidden state propagation and updating, which releases computational costs of handling temporal cues during tracking. Extensive experimental results demonstrate that SMTrack achieves promising performance with low computational costs.
Contribution-aware Token Compression for Efficient Video Understanding via Reinforcement Learning
Feb 02, 2026Video large language models have demonstrated remarkable capabilities in video understanding tasks. However, the redundancy of video tokens introduces significant computational overhead during inference, limiting their practical deployment. Many compression algorithms are proposed to prioritize retaining features with the highest attention scores to minimize perturbations in attention computations. However, the correlation between attention scores and their actual contribution to correct answers remains ambiguous. To address the above limitation, we propose a novel \textbf{C}ontribution-\textbf{a}ware token \textbf{Co}mpression algorithm for \textbf{VID}eo understanding (\textbf{CaCoVID}) that explicitly optimizes the token selection policy based on the contribution of tokens to correct predictions. First, we introduce a reinforcement learning-based framework that optimizes a policy network to select video token combinations with the greatest contribution to correct predictions. This paradigm shifts the focus from passive token preservation to active discovery of optimal compressed token combinations. Secondly, we propose a combinatorial policy optimization algorithm with online combination space sampling, which dramatically reduces the exploration space for video token combinations and accelerates the convergence speed of policy optimization. Extensive experiments on diverse video understanding benchmarks demonstrate the effectiveness of CaCoVID. Codes will be released.
Unified Thinker: A General Reasoning Modular Core for Image Generation
Jan 06, 2026Despite impressive progress in high-fidelity image synthesis, generative models still struggle with logic-intensive instruction following, exposing a persistent reasoning--execution gap. Meanwhile, closed-source systems (e.g., Nano Banana) have demonstrated strong reasoning-driven image generation, highlighting a substantial gap to current open-source models. We argue that closing this gap requires not merely better visual generators, but executable reasoning: decomposing high-level intents into grounded, verifiable plans that directly steer the generative process. To this end, we propose Unified Thinker, a task-agnostic reasoning architecture for general image generation, designed as a unified planning core that can plug into diverse generators and workflows. Unified Thinker decouples a dedicated Thinker from the image Generator, enabling modular upgrades of reasoning without retraining the entire generative model. We further introduce a two-stage training paradigm: we first build a structured planning interface for the Thinker, then apply reinforcement learning to ground its policy in pixel-level feedback, encouraging plans that optimize visual correctness over textual plausibility. Extensive experiments on text-to-image generation and image editing show that Unified Thinker substantially improves image reasoning and generation quality.
Unifying Visual and Vision-Language Tracking via Contrastive Learning
Jan 20, 2024Single object tracking aims to locate the target object in a video sequence according to the state specified by different modal references, including the initial bounding box (BBOX), natural language (NL), or both (NL+BBOX). Due to the gap between different modalities, most existing trackers are designed for single or partial of these reference settings and overspecialize on the specific modality. Differently, we present a unified tracker called UVLTrack, which can simultaneously handle all three reference settings (BBOX, NL, NL+BBOX) with the same parameters. The proposed UVLTrack enjoys several merits. First, we design a modality-unified feature extractor for joint visual and language feature learning and propose a multi-modal contrastive loss to align the visual and language features into a unified semantic space. Second, a modality-adaptive box head is proposed, which makes full use of the target reference to mine ever-changing scenario features dynamically from video contexts and distinguish the target in a contrastive way, enabling robust performance in different reference settings. Extensive experimental results demonstrate that UVLTrack achieves promising performance on seven visual tracking datasets, three vision-language tracking datasets, and three visual grounding datasets. Codes and models will be open-sourced at https://github.com/OpenSpaceAI/UVLTrack.
A Keypoint-based Global Association Network for Lane Detection
Apr 15, 2022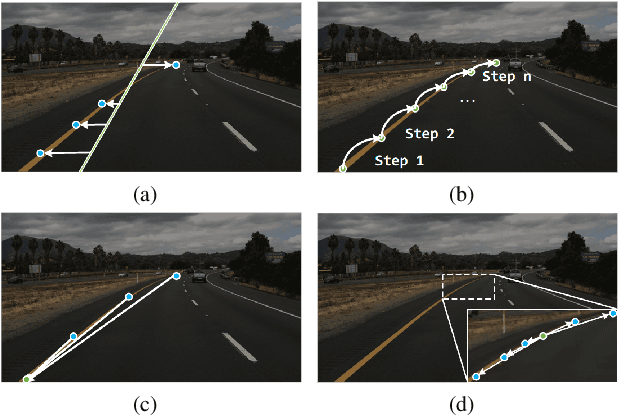

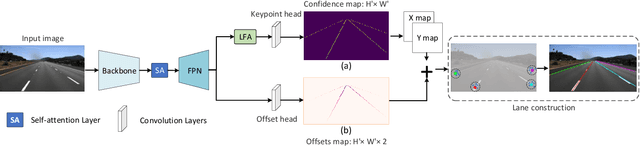
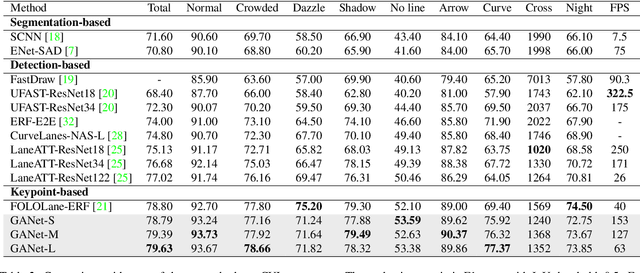
Lane detection is a challenging task that requires predicting complex topology shapes of lane lines and distinguishing different types of lanes simultaneously. Earlier works follow a top-down roadmap to regress predefined anchors into various shapes of lane lines, which lacks enough flexibility to fit complex shapes of lanes due to the fixed anchor shapes. Lately, some works propose to formulate lane detection as a keypoint estimation problem to describe the shapes of lane lines more flexibly and gradually group adjacent keypoints belonging to the same lane line in a point-by-point manner, which is inefficient and time-consuming during postprocessing. In this paper, we propose a Global Association Network (GANet) to formulate the lane detection problem from a new perspective, where each keypoint is directly regressed to the starting point of the lane line instead of point-by-point extension. Concretely, the association of keypoints to their belonged lane line is conducted by predicting their offsets to the corresponding starting points of lanes globally without dependence on each other, which could be done in parallel to greatly improve efficiency. In addition, we further propose a Lane-aware Feature Aggregator (LFA), which adaptively captures the local correlations between adjacent keypoints to supplement local information to the global association. Extensive experiments on two popular lane detection benchmarks show that our method outperforms previous methods with F1 score of 79.63% on CULane and 97.71% on Tusimple dataset with high FPS. The code will be released at https://github.com/Wolfwjs/GANet.
Interpreting and Boosting Dropout from a Game-Theoretic View
Oct 10, 2020

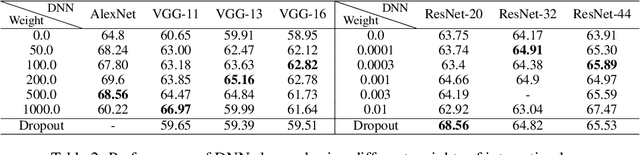
This paper aims to understand and improve the utility of the dropout operation from the perspective of game-theoretic interactions. We prove that dropout can suppress the strength of interactions between input variables of deep neural networks (DNNs). The theoretic proof is also verified by various experiments. Furthermore, we find that such interactions were strongly related to the over-fitting problem in deep learning. Thus, the utility of dropout can be regarded as decreasing interactions to alleviate the significance of over-fitting. Based on this understanding, we propose an interaction loss to further improve the utility of dropout. Experimental results have shown that the interaction loss can effectively improve the utility of dropout and boost the performance of DNNs.