 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradients Must Earn Their Influence: Unifying SFT with Generalized Entropic Objectives
Feb 11, 2026Standard negative log-likelihood (NLL) for Supervised Fine-Tuning (SFT) applies uniform token-level weighting. This rigidity creates a two-fold failure mode: (i) overemphasizing low-probability targets can amplify gradients on noisy supervision and disrupt robust priors, and (ii) uniform weighting provides weak sharpening when the model is already confident. Existing methods fail to resolve the resulting plasticity--stability dilemma, often suppressing necessary learning signals alongside harmful ones. To address this issue, we unify token-level SFT objectives within a generalized deformed-log family and expose a universal gate $\times$ error gradient structure, where the gate controls how much the model trusts its current prediction. By employing the Cayley transform, we map the model's continuously evolving uncertainty onto a continuous focus trajectory, which enables seamless interpolation between scenarios involving uncertain novel concepts and those involving well-established knowledge. We then introduce Dynamic Entropy Fine-Tuning (DEFT), a parameter-free objective that modulates the trust gate using distribution concentration (Rényi-2 entropy) as a practical proxy for the model's predictive state. Extensive experiments and analyses demonstrate that DEFT achieves a better balance between exploration and exploitation, leading to improved overall performance.
Beyond Confidence: The Rhythms of Reasoning in Generative Models
Feb 11, 2026Large Language Models (LLMs) exhibit impressive capabilities yet suffer from sensitivity to slight input context variations, hampering reliability. Conventional metrics like accuracy and perplexity fail to assess local prediction robustness, as normalized output probabilities can obscure the underlying resilience of an LLM's internal state to perturbations. We introduce the Token Constraint Bound ($δ_{\mathrm{TCB}}$), a novel metric that quantifies the maximum internal state perturbation an LLM can withstand before its dominant next-token prediction significantly changes. Intrinsically linked to output embedding space geometry, $δ_{\mathrm{TCB}}$ provides insights into the stability of the model's internal predictive commitment. Our experiments show $δ_{\mathrm{TCB}}$ correlates with effective prompt engineering and uncovers critical prediction instabilities missed by perplexity during in-context learning and text generation. $δ_{\mathrm{TCB}}$ offers a principled, complementary approach to analyze and potentially improve the contextual stability of LLM predictions.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
May 26, 2025Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0\% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Mitigating Gender Bias in Code Large Language Models via Model Editing
Oct 10, 2024In recent years, with the maturation of large language model (LLM) technology and the emergence of high-quality programming code datasets, researchers have become increasingly confident in addressing the challenges of program synthesis automatically. However, since most of the training samples for LLMs are unscreened, it is inevitable that LLMs' performance may not align with real-world scenarios, leading to the presence of social bias. To evaluate and quantify the gender bias in code LLMs, we propose a dataset named CodeGenBias (Gender Bias in the Code Generation) and an evaluation metric called FB-Score (Factual Bias Score) based on the actual gender distribution of correlative professions. With the help of CodeGenBias and FB-Score, we evaluate and analyze the gender bias in eight mainstream Code LLMs. Previous work has demonstrated that model editing methods that perform well in knowledge editing have the potential to mitigate social bias in LLMs. Therefore, we develop a model editing approach named MG-Editing (Multi-Granularity model Editing), which includes the locating and editing phases. Our model editing method MG-Editing can be applied at five different levels of model parameter granularity: full parameters level, layer level, module level, row level, and neuron level. Extensive experiments not only demonstrate that our MG-Editing can effectively mitigate the gender bias in code LLMs while maintaining their general code generation capabilities, but also showcase its excellent generalization. At the same time, the experimental results show that, considering both the gender bias of the model and its general code generation capability, MG-Editing is most effective when applied at the row and neuron levels of granularity.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
Checkpoint Merging via Bayesian Optimization in LLM Pretraining
Mar 28, 2024The rapid proliferation of large language models (LLMs) such as GPT-4 and Gemini underscores the intense demand for resources during their training processes, posing significant challenges due to substantial computational and environmental costs. To alleviate this issue, we propose checkpoint merging in pretraining LLM. This method utilizes LLM checkpoints with shared training trajectories, and is rooted in an extensive search space exploration for the best merging weight via Bayesian optimization. Through various experiments, we demonstrate that: (1) Our proposed methodology exhibits the capacity to augment pretraining, presenting an opportunity akin to obtaining substantial benefits at minimal cost; (2) Our proposed methodology, despite requiring a given held-out dataset, still demonstrates robust generalization capabilities across diverse domains, a pivotal aspect in pretraining.
Pre-training with Synthetic Data Helps Offline Reinforcement Learning
Oct 06, 2023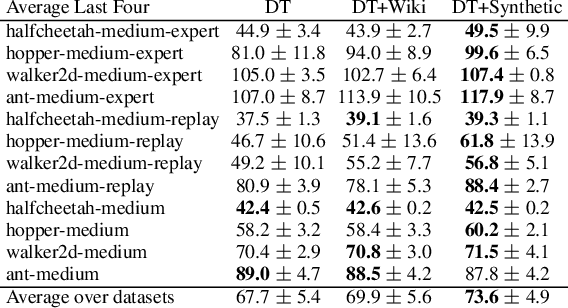
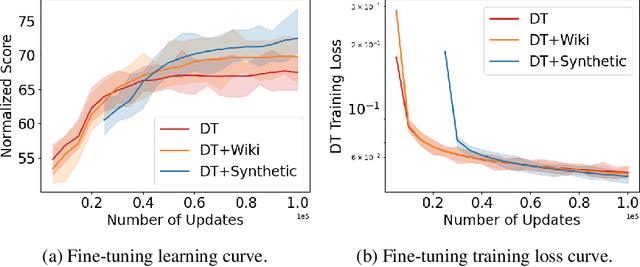
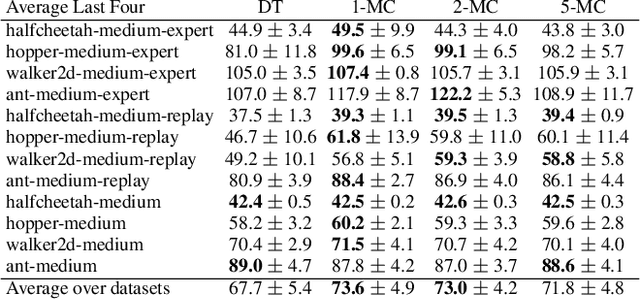
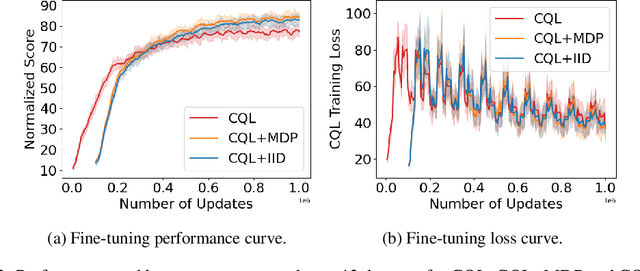
Recently, it has been shown that for offline deep reinforcement learning (DRL), pre-training Decision Transformer with a large language corpus can improve downstream performance (Reid et al., 2022). A natural question to ask is whether this performance gain can only be achieved with language pre-training, or can be achieved with simpler pre-training schemes which do not involve language. In this paper, we first show that language is not essential for improved performance, and indeed pre-training with synthetic IID data for a small number of updates can match the performance gains from pre-training with a large language corpus; moreover, pre-training with data generated by a one-step Markov chain can further improve the performance. Inspired by these experimental results, we then consider pre-training Conservative Q-Learning (CQL), a popular offline DRL algorithm, which is Q-learning-based and typically employs a Multi-Layer Perceptron (MLP) backbone. Surprisingly, pre-training with simple synthetic data for a small number of updates can also improve CQL, providing consistent performance improvement on D4RL Gym locomotion datasets. The results of this paper not only illustrate the importance of pre-training for offline DRL but also show that the pre-training data can be synthetic and generated with remarkably simple mechanisms.
Robust Unstructured Knowledge Access in Conversational Dialogue with ASR Errors
Nov 08, 2022



Performance of spoken language understanding (SLU) can be degraded with automatic speech recognition (ASR) errors. We propose a novel approach to improve SLU robustness by randomly corrupting clean training text with an ASR error simulator, followed by self-correcting the errors and minimizing the target classification loss in a joint manner. In the proposed error simulator, we leverage confusion networks generated from an ASR decoder without human transcriptions to generate a variety of error patterns for model training. We evaluate our approach on the DSTC10 challenge targeted for knowledge-grounded task-oriented conversational dialogues with ASR errors. Experimental results show the effectiveness of our proposed approach, boosting the knowledge-seeking turn detection (KTD) F1 significantly from 0.9433 to 0.9904. Knowledge cluster classification is boosted from 0.7924 to 0.9333 in Recall@1. After knowledge document re-ranking, our approach shows significant improvement in all knowledge selection metrics, from 0.7358 to 0.7806 in Recall@1, from 0.8301 to 0.9333 in Recall@5, and from 0.7798 to 0.8460 in MRR@5 on the test set. In the recent DSTC10 evaluation, our approach demonstrates significant improvement in knowledge selection, boosting Recall@1 from 0.495 to 0.7144 compared to the official baseline. Our source code is released in GitHub https://github.com/yctam/dstc10_track2_task2.git.
* 7 pages, 2 figures. Accepted at ICASSP 2022