 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFTF: Locating First and Then Fine-Tuning for Mitigating Gender Bias in Large Language Models
May 21, 2025Nowadays, Large Language Models (LLMs) have attracted widespread attention due to their powerful performance. However, due to the unavoidable exposure to socially biased data during training, LLMs tend to exhibit social biases, particularly gender bias. To better explore and quantifying the degree of gender bias in LLMs, we propose a pair of datasets named GenBiasEval and GenHintEval, respectively. The GenBiasEval is responsible for evaluating the degree of gender bias in LLMs, accompanied by an evaluation metric named AFGB-Score (Absolutely Fair Gender Bias Score). Meanwhile, the GenHintEval is used to assess whether LLMs can provide responses consistent with prompts that contain gender hints, along with the accompanying evaluation metric UB-Score (UnBias Score). Besides, in order to mitigate gender bias in LLMs more effectively, we present the LFTF (Locating First and Then Fine-Tuning) algorithm.The algorithm first ranks specific LLM blocks by their relevance to gender bias in descending order using a metric called BMI (Block Mitigating Importance Score). Based on this ranking, the block most strongly associated with gender bias is then fine-tuned using a carefully designed loss function. Numerous experiments have shown that our proposed LFTF algorithm can significantly mitigate gender bias in LLMs while maintaining their general capabilities.
Efficient Generative Model Training via Embedded Representation Warmup
Apr 14, 2025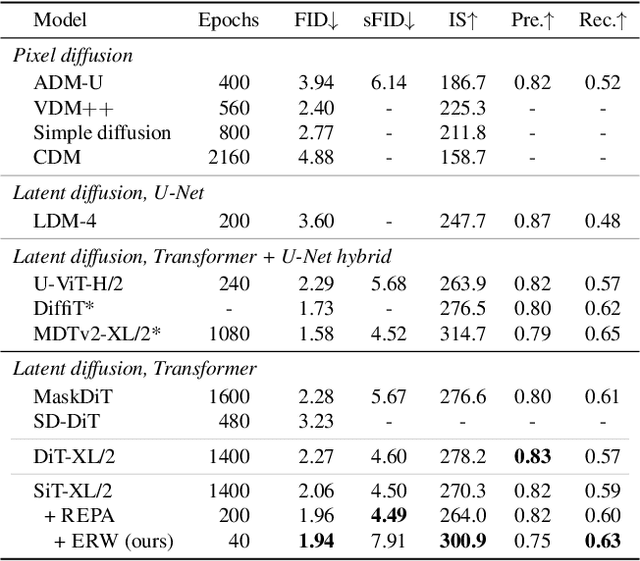



Diffusion models excel at generating high-dimensional data but fall short in training efficiency and representation quality compared to self-supervised methods. We identify a key bottleneck: the underutilization of high-quality, semantically rich representations during training notably slows down convergence. Our systematic analysis reveals a critical representation processing region -- primarily in the early layers -- where semantic and structural pattern learning takes place before generation can occur. To address this, we propose Embedded Representation Warmup (ERW), a plug-and-play framework where in the first stage we get the ERW module serves as a warmup that initializes the early layers of the diffusion model with high-quality, pretrained representations. This warmup minimizes the burden of learning representations from scratch, thereby accelerating convergence and boosting performance. Our theoretical analysis demonstrates that ERW's efficacy depends on its precise integration into specific neural network layers -- termed the representation processing region -- where the model primarily processes and transforms feature representations for later generation. We further establish that ERW not only accelerates training convergence but also enhances representation quality: empirically, our method achieves a 40$\times$ acceleration in training speed compared to REPA, the current state-of-the-art methods. Code is available at https://github.com/LINs-lab/ERW.
Mitigating Gender Bias in Code Large Language Models via Model Editing
Oct 10, 2024In recent years, with the maturation of large language model (LLM) technology and the emergence of high-quality programming code datasets, researchers have become increasingly confident in addressing the challenges of program synthesis automatically. However, since most of the training samples for LLMs are unscreened, it is inevitable that LLMs' performance may not align with real-world scenarios, leading to the presence of social bias. To evaluate and quantify the gender bias in code LLMs, we propose a dataset named CodeGenBias (Gender Bias in the Code Generation) and an evaluation metric called FB-Score (Factual Bias Score) based on the actual gender distribution of correlative professions. With the help of CodeGenBias and FB-Score, we evaluate and analyze the gender bias in eight mainstream Code LLMs. Previous work has demonstrated that model editing methods that perform well in knowledge editing have the potential to mitigate social bias in LLMs. Therefore, we develop a model editing approach named MG-Editing (Multi-Granularity model Editing), which includes the locating and editing phases. Our model editing method MG-Editing can be applied at five different levels of model parameter granularity: full parameters level, layer level, module level, row level, and neuron level. Extensive experiments not only demonstrate that our MG-Editing can effectively mitigate the gender bias in code LLMs while maintaining their general code generation capabilities, but also showcase its excellent generalization. At the same time, the experimental results show that, considering both the gender bias of the model and its general code generation capability, MG-Editing is most effective when applied at the row and neuron levels of granularity.
UNO Arena for Evaluating Sequential Decision-Making Capability of Large Language Models
Jun 24, 2024Sequential decision-making refers to algorithms that take into account the dynamics of the environment, where early decisions affect subsequent decisions. With large language models (LLMs) demonstrating powerful capabilities between tasks, we can't help but ask: Can Current LLMs Effectively Make Sequential Decisions? In order to answer this question, we propose the UNO Arena based on the card game UNO to evaluate the sequential decision-making capability of LLMs and explain in detail why we choose UNO. In UNO Arena, We evaluate the sequential decision-making capability of LLMs dynamically with novel metrics based Monte Carlo methods. We set up random players, DQN-based reinforcement learning players, and LLM players (e.g. GPT-4, Gemini-pro) for comparison testing. Furthermore, in order to improve the sequential decision-making capability of LLMs, we propose the TUTRI player, which can involves having LLMs reflect their own actions wtih the summary of game history and the game strategy. Numerous experiments demonstrate that the TUTRI player achieves a notable breakthrough in the performance of sequential decision-making compared to the vanilla LLM player.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
Checkpoint Merging via Bayesian Optimization in LLM Pretraining
Mar 28, 2024The rapid proliferation of large language models (LLMs) such as GPT-4 and Gemini underscores the intense demand for resources during their training processes, posing significant challenges due to substantial computational and environmental costs. To alleviate this issue, we propose checkpoint merging in pretraining LLM. This method utilizes LLM checkpoints with shared training trajectories, and is rooted in an extensive search space exploration for the best merging weight via Bayesian optimization. Through various experiments, we demonstrate that: (1) Our proposed methodology exhibits the capacity to augment pretraining, presenting an opportunity akin to obtaining substantial benefits at minimal cost; (2) Our proposed methodology, despite requiring a given held-out dataset, still demonstrates robust generalization capabilities across diverse domains, a pivotal aspect in pretraining.