 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Visual Grounding in 3D Gaussians via View Retrieval
Sep 19, 2025


3D Visual Grounding (3DVG) aims to locate objects in 3D scenes based on text prompts, which is essential for applications such as robotics. However, existing 3DVG methods encounter two main challenges: first, they struggle to handle the implicit representation of spatial textures in 3D Gaussian Splatting (3DGS), making per-scene training indispensable; second, they typically require larges amounts of labeled data for effective training. To this end, we propose \underline{G}rounding via \underline{V}iew \underline{R}etrieval (GVR), a novel zero-shot visual grounding framework for 3DGS to transform 3DVG as a 2D retrieval task that leverages object-level view retrieval to collect grounding clues from multiple views, which not only avoids the costly process of 3D annotation, but also eliminates the need for per-scene training. Extensive experiments demonstrate that our method achieves state-of-the-art visual grounding performance while avoiding per-scene training, providing a solid foundation for zero-shot 3DVG research. Video demos can be found in https://github.com/leviome/GVR_demos.
Efficient Generative Model Training via Embedded Representation Warmup
Apr 14, 2025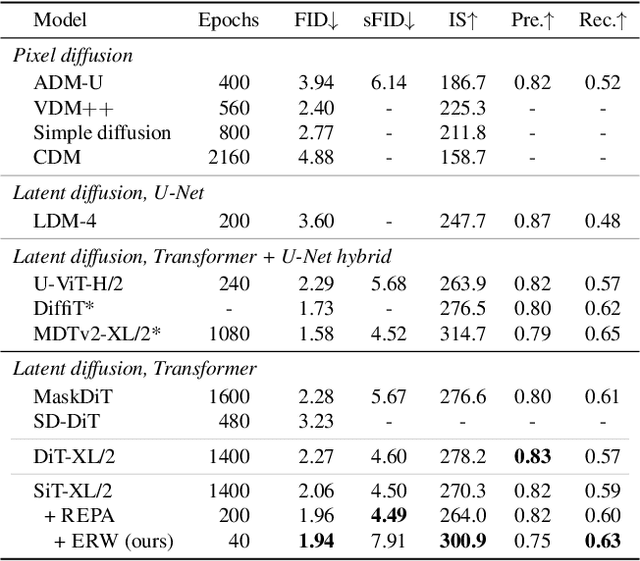



Diffusion models excel at generating high-dimensional data but fall short in training efficiency and representation quality compared to self-supervised methods. We identify a key bottleneck: the underutilization of high-quality, semantically rich representations during training notably slows down convergence. Our systematic analysis reveals a critical representation processing region -- primarily in the early layers -- where semantic and structural pattern learning takes place before generation can occur. To address this, we propose Embedded Representation Warmup (ERW), a plug-and-play framework where in the first stage we get the ERW module serves as a warmup that initializes the early layers of the diffusion model with high-quality, pretrained representations. This warmup minimizes the burden of learning representations from scratch, thereby accelerating convergence and boosting performance. Our theoretical analysis demonstrates that ERW's efficacy depends on its precise integration into specific neural network layers -- termed the representation processing region -- where the model primarily processes and transforms feature representations for later generation. We further establish that ERW not only accelerates training convergence but also enhances representation quality: empirically, our method achieves a 40$\times$ acceleration in training speed compared to REPA, the current state-of-the-art methods. Code is available at https://github.com/LINs-lab/ERW.
PKU-DyMVHumans: A Multi-View Video Benchmark for High-Fidelity Dynamic Human Modeling
Apr 02, 2024High-quality human reconstruction and photo-realistic rendering of a dynamic scene is a long-standing problem in computer vision and graphics. Despite considerable efforts invested in developing various capture systems and reconstruction algorithms, recent advancements still struggle with loose or oversized clothing and overly complex poses. In part, this is due to the challenges of acquiring high-quality human datasets. To facilitate the development of these fields, in this paper, we present PKU-DyMVHumans, a versatile human-centric dataset for high-fidelity reconstruction and rendering of dynamic human scenarios from dense multi-view videos. It comprises 8.2 million frames captured by more than 56 synchronized cameras across diverse scenarios. These sequences comprise 32 human subjects across 45 different scenarios, each with a high-detailed appearance and realistic human motion. Inspired by recent advancements in neural radiance field (NeRF)-based scene representations, we carefully set up an off-the-shelf framework that is easy to provide those state-of-the-art NeRF-based implementations and benchmark on PKU-DyMVHumans dataset. It is paving the way for various applications like fine-grained foreground/background decomposition, high-quality human reconstruction and photo-realistic novel view synthesis of a dynamic scene. Extensive studies are performed on the benchmark, demonstrating new observations and challenges that emerge from using such high-fidelity dynamic data.