 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkewRoute: Training-Free LLM Routing for Knowledge Graph Retrieval-Augmented Generation via Score Skewness of Retrieved Context
May 28, 2025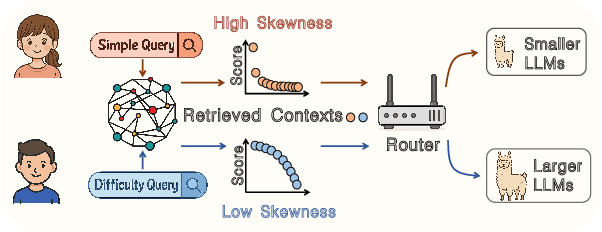

Large language models excel at many tasks but often incur high inference costs during deployment. To mitigate hallucination, many systems use a knowledge graph to enhance retrieval-augmented generation (KG-RAG). However, the large amount of retrieved knowledge contexts increase these inference costs further. A promising solution to balance performance and cost is LLM routing, which directs simple queries to smaller LLMs and complex ones to larger LLMs. However, no dedicated routing methods currently exist for RAG, and existing training-based routers face challenges scaling to this domain due to the need for extensive training data. We observe that the score distributions produced by the retrieval scorer strongly correlate with query difficulty. Based on this, we propose a novel, training-free routing framework, the first tailored to KG-RAG that effectively balances performance and cost in a plug-and-play manner. Experiments show our method reduces calls to larger LLMs by up to 50% without sacrificing response quality, demonstrating its potential for efficient and scalable LLM deployment.
Lego Sketch: A Scalable Memory-augmented Neural Network for Sketching Data Streams
May 26, 2025Sketches, probabilistic structures for estimating item frequencies in infinite data streams with limited space, are widely used across various domains. Recent studies have shifted the focus from handcrafted sketches to neural sketches, leveraging memory-augmented neural networks (MANNs) to enhance the streaming compression capabilities and achieve better space-accuracy trade-offs.However, existing neural sketches struggle to scale across different data domains and space budgets due to inflexible MANN configurations. In this paper, we introduce a scalable MANN architecture that brings to life the {\it Lego sketch}, a novel sketch with superior scalability and accuracy. Much like assembling creations with modular Lego bricks, the Lego sketch dynamically coordinates multiple memory bricks to adapt to various space budgets and diverse data domains. Our theoretical analysis guarantees its high scalability and provides the first error bound for neural sketch. Furthermore, extensive experimental evaluations demonstrate that the Lego sketch exhibits superior space-accuracy trade-offs, outperforming existing handcrafted and neural sketches. Our code is available at https://github.com/FFY0/LegoSketch_ICML.
Path Pooling: Train-Free Structure Enhancement for Efficient Knowledge Graph Retrieval-Augmented Generation
Mar 07, 2025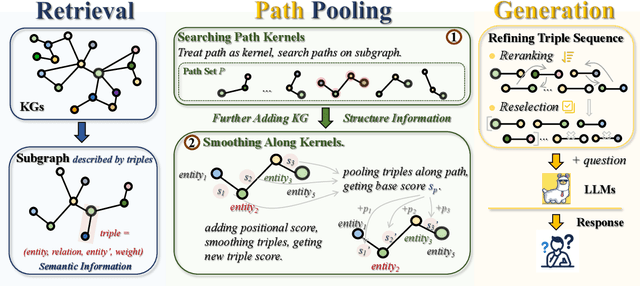
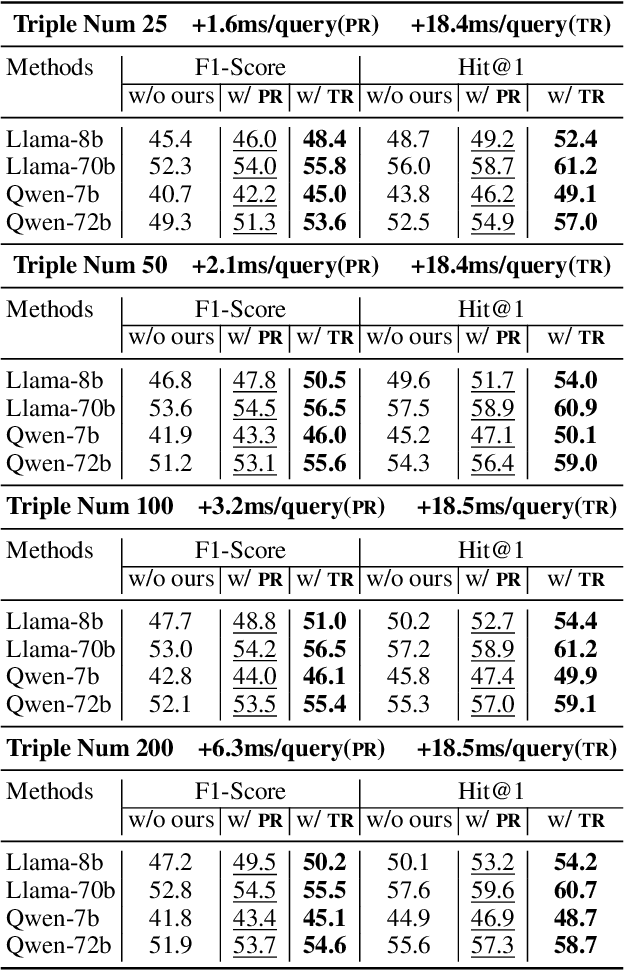
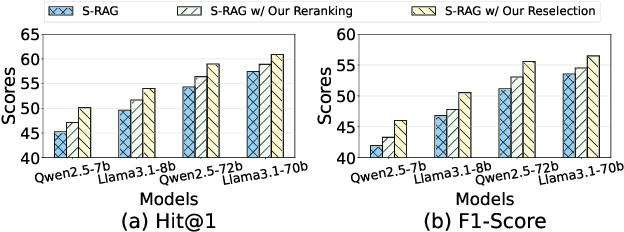

Although Large Language Models achieve strong success in many tasks, they still suffer from hallucinations and knowledge deficiencies in real-world applications. Many knowledge graph-based retrieval-augmented generation (KG-RAG) methods enhance the quality and credibility of LLMs by leveraging structure and semantic information in KGs as external knowledge bases. However, these methods struggle to effectively incorporate structure information, either incurring high computational costs or underutilizing available knowledge. Inspired by smoothing operations in graph representation learning, we propose path pooling, a simple, train-free strategy that introduces structure information through a novel path-centric pooling operation. It seamlessly integrates into existing KG-RAG methods in a plug-and-play manner, enabling richer structure information utilization. Extensive experiments demonstrate that incorporating the path pooling into the state-of-the-art KG-RAG method consistently improves performance across various settings while introducing negligible additional cost. Code is coming soon at https://github.com/hrwang00/path-pooling.
FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs
Jan 17, 2025



To mitigate the hallucination and knowledge deficiency in large language models (LLMs), Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) has shown promising potential by utilizing KGs as external resource to enhance LLMs reasoning.However, existing KG-RAG approaches struggle with a trade-off between flexibility and retrieval quality.Modular methods prioritize flexibility by avoiding the use of KG-fine-tuned models during retrieval, leading to fixed retrieval strategies and suboptimal retrieval quality.Conversely, coupled methods embed KG information within models to improve retrieval quality, but at the expense of flexibility.In this paper, we propose a novel flexible modular KG-RAG framework, termed FRAG, which synergizes the advantages of both approaches.FRAG estimates the hop range of reasoning paths based solely on the query and classify it as either simple or complex.To match the complexity of the query, tailored pipelines are applied to ensure efficient and accurate reasoning path retrieval, thus fostering the final reasoning process.By using the query text instead of the KG to infer the structural information of reasoning paths and employing adaptable retrieval strategies, FRAG improves retrieval quality while maintaining flexibility.Moreover, FRAG does not require extra LLMs fine-tuning or calls, significantly boosting efficiency and conserving resources.Extensive experiments show that FRAG achieves state-of-the-art performance with high efficiency and low resource consumption.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.