 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth-Empathy: Towards High-Quality Synthetic Empathy Data
Paper and Code
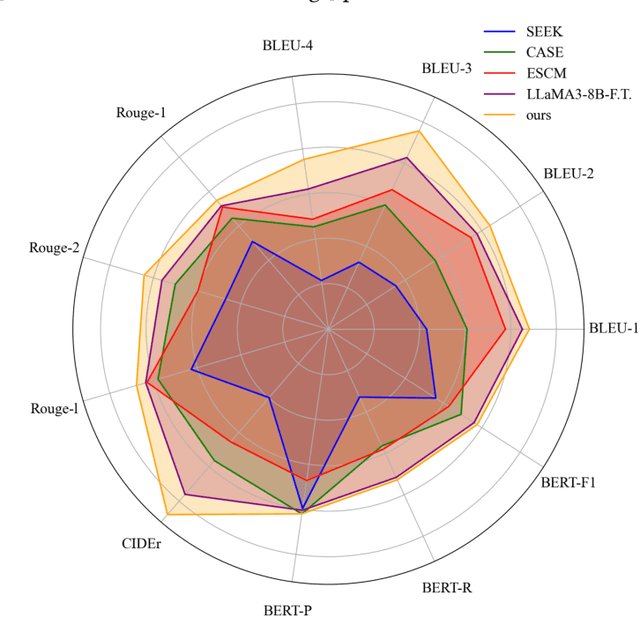

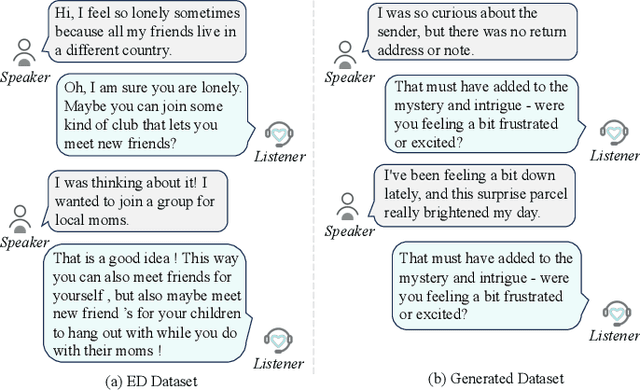

In recent years, with the rapid advancements in large language models (LLMs), achieving excellent empathetic response capabilities has become a crucial prerequisite. Consequently, managing and understanding empathetic datasets have gained increasing significance. However, empathetic data are typically human-labeled, leading to insufficient datasets and wasted human labor. In this work, we present Synth-Empathy, an LLM-based data generation and quality and diversity selection pipeline that automatically generates high-quality empathetic data while discarding low-quality data. With the data generated from a low empathetic model, we are able to further improve empathetic response performance and achieve state-of-the-art (SoTA) results across multiple benchmarks. Moreover, our model achieves SoTA performance on various human evaluation benchmarks, demonstrating its effectiveness and robustness in real-world applications. Furthermore, we show the trade-off between data quantity and quality, providing insights into empathetic data generation and selection.