 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoutesplain: Towards Faithful and Intervenable Routing for Software-related Tasks
Nov 12, 2025



LLMs now tackle a wide range of software-related tasks, yet we show that their performance varies markedly both across and within these tasks. Routing user queries to the appropriate LLMs can therefore help improve response quality while reducing cost. Prior work, however, has focused mainly on general-purpose LLM routing via black-box models. We introduce Routesplain, the first LLM router for software-related tasks, including multilingual code generation and repair, input/output prediction, and computer science QA. Unlike existing routing approaches, Routesplain first extracts human-interpretable concepts from each query (e.g., task, domain, reasoning complexity) and only routes based on these concepts, thereby providing intelligible, faithful rationales. We evaluate Routesplain on 16 state-of-the-art LLMs across eight software-related tasks; Routesplain outperforms individual models both in terms of accuracy and cost, and equals or surpasses all black-box baselines, with concept-level intervention highlighting avenues for further router improvements.
LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
Oct 08, 2025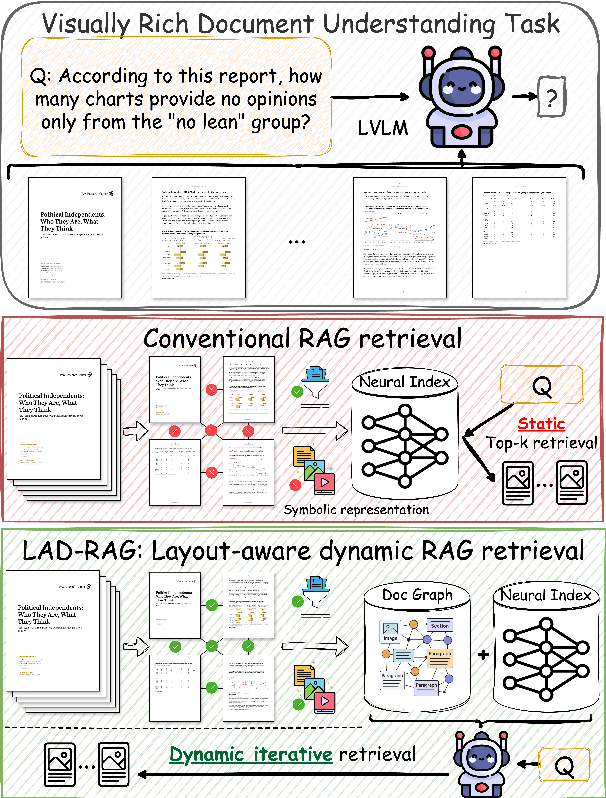
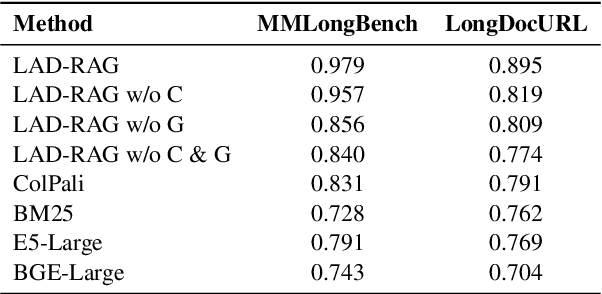
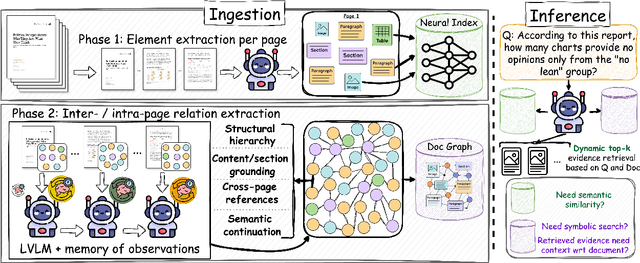
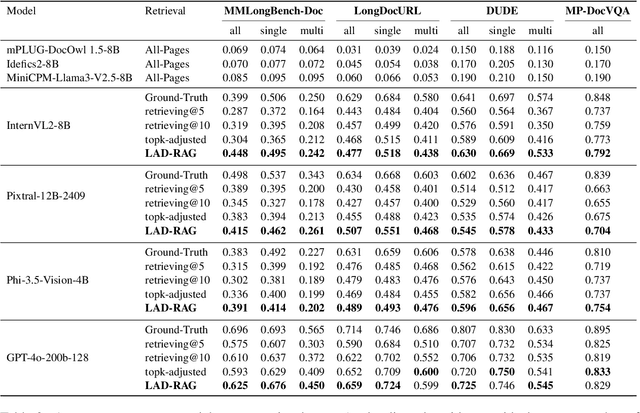
Question answering over visually rich documents (VRDs) requires reasoning not only over isolated content but also over documents' structural organization and cross-page dependencies. However, conventional retrieval-augmented generation (RAG) methods encode content in isolated chunks during ingestion, losing structural and cross-page dependencies, and retrieve a fixed number of pages at inference, regardless of the specific demands of the question or context. This often results in incomplete evidence retrieval and degraded answer quality for multi-page reasoning tasks. To address these limitations, we propose LAD-RAG, a novel Layout-Aware Dynamic RAG framework. During ingestion, LAD-RAG constructs a symbolic document graph that captures layout structure and cross-page dependencies, adding it alongside standard neural embeddings to yield a more holistic representation of the document. During inference, an LLM agent dynamically interacts with the neural and symbolic indices to adaptively retrieve the necessary evidence based on the query. Experiments on MMLongBench-Doc, LongDocURL, DUDE, and MP-DocVQA demonstrate that LAD-RAG improves retrieval, achieving over 90% perfect recall on average without any top-k tuning, and outperforming baseline retrievers by up to 20% in recall at comparable noise levels, yielding higher QA accuracy with minimal latency.
Inducing a hierarchy for multi-class classification problems
Feb 20, 2021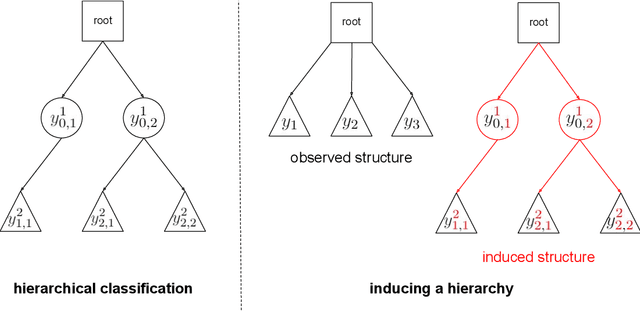
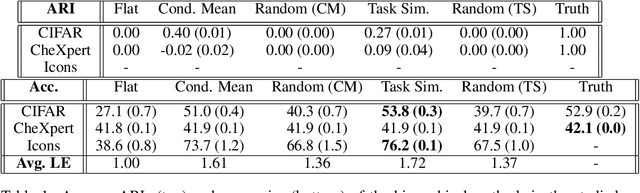
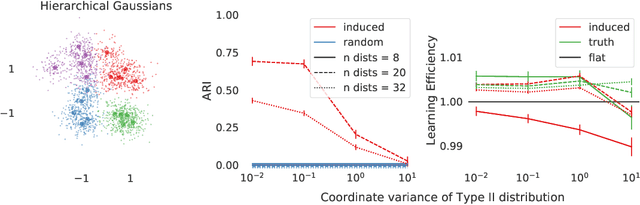
In applications where categorical labels follow a natural hierarchy, classification methods that exploit the label structure often outperform those that do not. Un-fortunately, the majority of classification datasets do not come pre-equipped with a hierarchical structure and classical flat classifiers must be employed. In this paper, we investigate a class of methods that induce a hierarchy that can similarly improve classification performance over flat classifiers. The class of methods follows the structure of first clustering the conditional distributions and subsequently using a hierarchical classifier with the induced hierarchy. We demonstrate the effectiveness of the class of methods both for discovering a latent hierarchy and for improving accuracy in principled simulation settings and three real data applications.
Training Large Neural Networks with Constant Memory using a New Execution Algorithm
Feb 22, 2020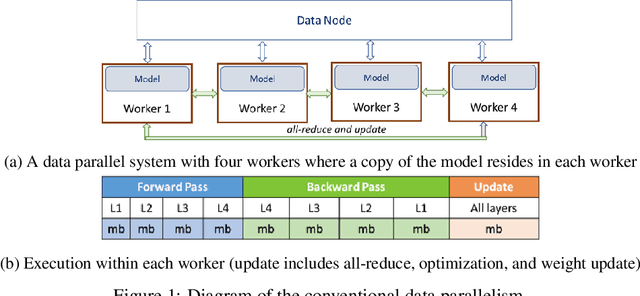

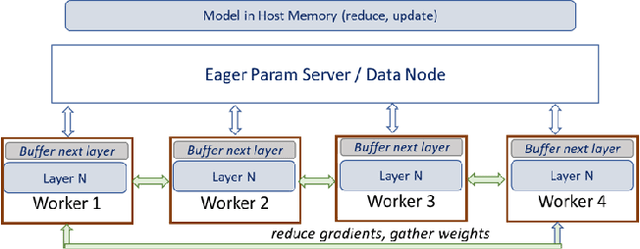
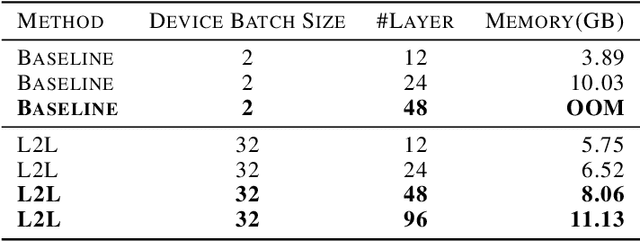
Widely popular transformer-based NLP models such as BERT and GPT have enormous capacity trending to billions of parameters. Current execution methods demand brute-force resources such as HBM devices and high speed interconnectivity for data parallelism. In this paper, we introduce a new relay-style execution technique called L2L (layer-to-layer) where at any given moment, the device memory is primarily populated only with the executing layer(s)'s footprint. The model resides in the DRAM memory attached to either a CPU or an FPGA as an entity we call eager param-server (EPS). Unlike a traditional param-server, EPS transmits the model piecemeal to the devices thereby allowing it to perform other tasks in the background such as reduction and distributed optimization. To overcome the bandwidth issues of shuttling parameters to and from EPS, the model is executed a layer at a time across many micro-batches instead of the conventional method of minibatches over whole model. In this paper, we explore a conservative version of L2L that is implemented on a modest Azure instance for BERT-Large running it with a batch size of 32 on a single V100 GPU using less than 8GB memory. Our results show a more stable learning curve, faster convergence, better accuracy and 35% reduction in memory compared to the state-of-the-art baseline. Our method reproduces BERT results on any mid-level GPU that was hitherto not feasible. L2L scales to arbitrary depth without impacting memory or devices allowing researchers to develop affordable devices. It also enables dynamic approaches such as neural architecture search. This work has been performed on GPUs first but also targeted towards high TFLOPS/Watt accelerators such as Graphcore IPUs. The code will soon be available on github.