 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPHY: Probing "Visible" Physical Commonsense Knowledge
Sep 15, 2022
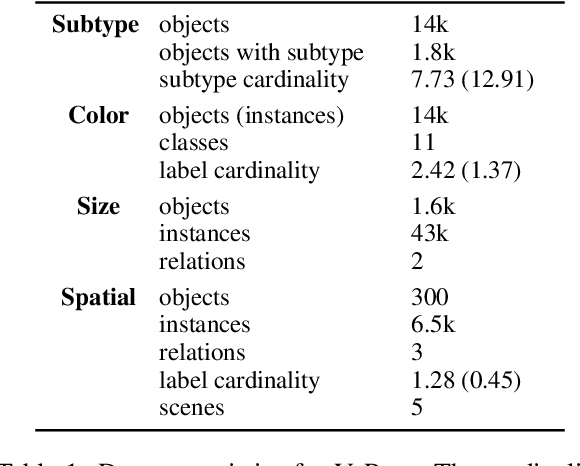
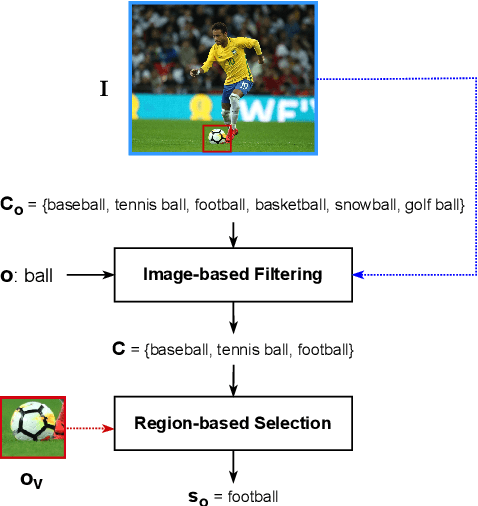

In recent years, vision-language models (VLMs) have shown remarkable performance on visual reasoning tasks (e.g. attributes, location). While such tasks measure the requisite knowledge to ground and reason over a given visual instance, they do not, however, measure the ability of VLMs to retain and generalize such knowledge. In this work, we evaluate their ability to acquire "visible" physical knowledge -- the information that is easily accessible from images of static scenes, particularly across the dimensions of object color, size and space. We build an automatic pipeline to derive a comprehensive knowledge resource for calibrating and probing these models. Our results indicate a severe gap between model and human performance across all three tasks. Furthermore, our caption pretrained baseline (CapBERT) significantly outperforms VLMs on both size and spatial tasks -- highlighting that despite sufficient access to ground language with visual modality, they struggle to retain such knowledge. The dataset and code are available at https://github.com/Axe--/ViPhy .
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Using Graph Neural Networks to model the performance of Deep Neural Networks
Aug 27, 2021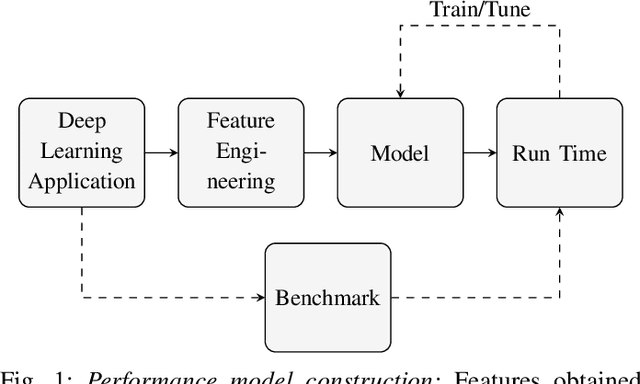
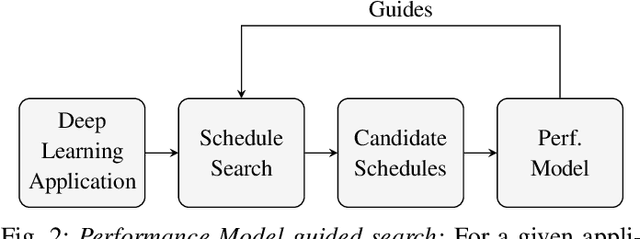
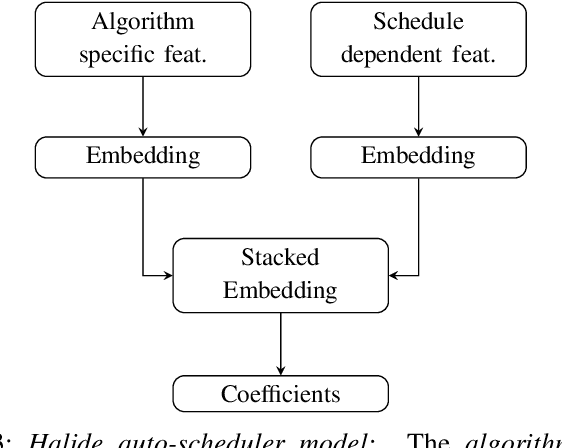
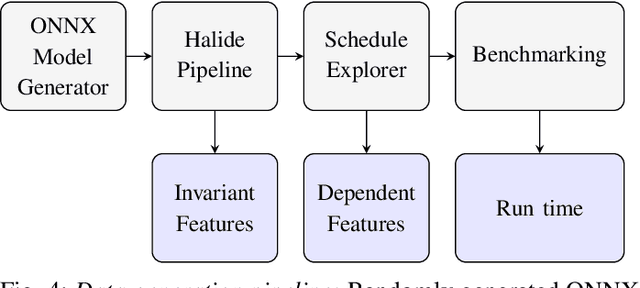
With the unprecedented proliferation of machine learning software, there is an ever-increasing need to generate efficient code for such applications. State-of-the-art deep-learning compilers like TVM and Halide incorporate a learning-based performance model to search the space of valid implementations of a given deep learning algorithm. For a given application, the model generates a performance metric such as the run time without executing the application on hardware. Such models speed up the compilation process by obviating the need to benchmark an enormous number of candidate implementations, referred to as schedules, on hardware. Existing performance models employ feed-forward networks, recurrent networks, or decision tree ensembles to estimate the performance of different implementations of a neural network. Graphs present a natural and intuitive way to model deep-learning networks where each node represents a computational stage or operation. Incorporating the inherent graph structure of these workloads in the performance model can enable a better representation and learning of inter-stage interactions. The accuracy of a performance model has direct implications on the efficiency of the search strategy, making it a crucial component of this class of deep-learning compilers. In this work, we develop a novel performance model that adopts a graph representation. In our model, each stage of computation represents a node characterized by features that capture the operations performed by the stage. The interaction between nodes is achieved using graph convolutions. Experimental evaluation shows a 7:75x and 12x reduction in prediction error compared to the Halide and TVM models, respectively.
COM2SENSE: A Commonsense Reasoning Benchmark with Complementary Sentences
Jun 02, 2021Commonsense reasoning is intuitive for humans but has been a long-term challenge for artificial intelligence (AI). Recent advancements in pretrained language models have shown promising results on several commonsense benchmark datasets. However, the reliability and comprehensiveness of these benchmarks towards assessing model's commonsense reasoning ability remains unclear. To this end, we introduce a new commonsense reasoning benchmark dataset comprising natural language true/false statements, with each sample paired with its complementary counterpart, resulting in 4k sentence pairs. We propose a pairwise accuracy metric to reliably measure an agent's ability to perform commonsense reasoning over a given situation. The dataset is crowdsourced and enhanced with an adversarial model-in-the-loop setup to incentivize challenging samples. To facilitate a systematic analysis of commonsense capabilities, we design our dataset along the dimensions of knowledge domains, reasoning scenarios and numeracy. Experimental results demonstrate that our strongest baseline (UnifiedQA-3B), after fine-tuning, achieves ~71% standard accuracy and ~51% pairwise accuracy, well below human performance (~95% for both metrics). The dataset is available at https://github.com/PlusLabNLP/Com2Sense.
EventPlus: A Temporal Event Understanding Pipeline
Jan 13, 2021
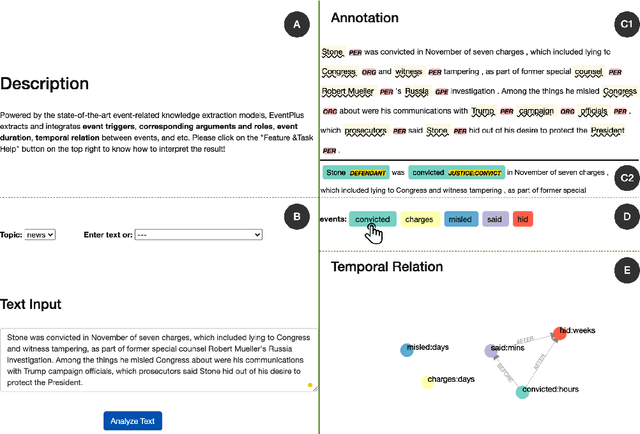
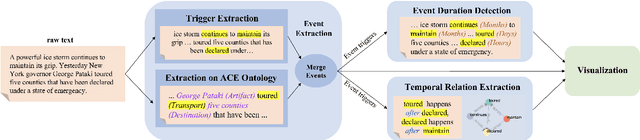
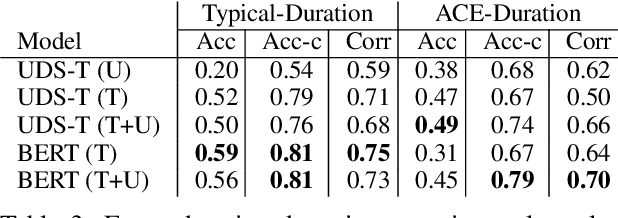
We present EventPlus, a temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction. Event information, especially event temporal knowledge, is a type of common sense knowledge that helps people understand how stories evolve and provides predictive hints for future events. EventPlus as the first comprehensive temporal event understanding pipeline provides a convenient tool for users to quickly obtain annotations about events and their temporal information for any user-provided document. Furthermore, we show EventPlus can be easily adapted to other domains (e.g., biomedical domain). We make EventPlus publicly available to facilitate event-related information extraction and downstream applications.
MELINDA: A Multimodal Dataset for Biomedical Experiment Method Classification
Dec 16, 2020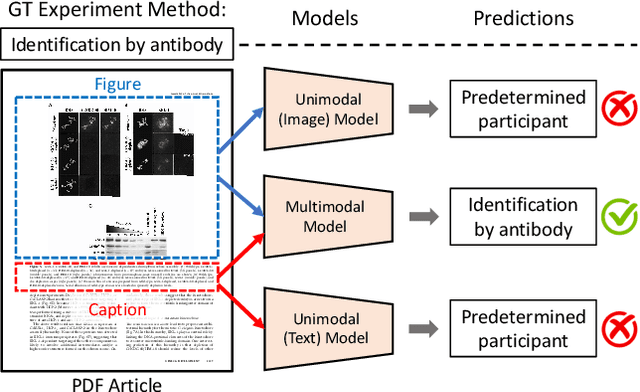
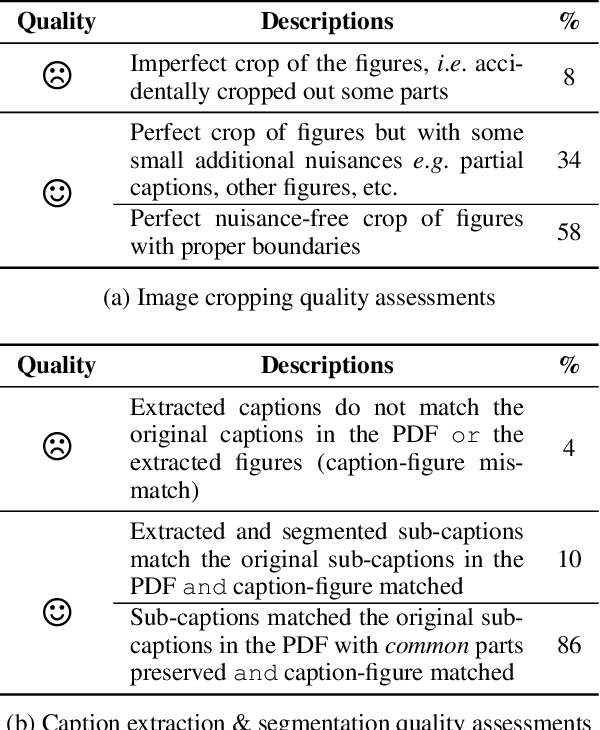

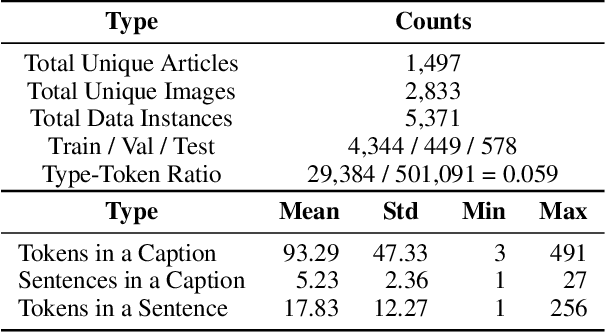
We introduce a new dataset, MELINDA, for Multimodal biomEdicaL experImeNt methoD clAssification. The dataset is collected in a fully automated distant supervision manner, where the labels are obtained from an existing curated database, and the actual contents are extracted from papers associated with each of the records in the database. We benchmark various state-of-the-art NLP and computer vision models, including unimodal models which only take either caption texts or images as inputs, and multimodal models. Extensive experiments and analysis show that multimodal models, despite outperforming unimodal ones, still need improvements especially on a less-supervised way of grounding visual concepts with languages, and better transferability to low resource domains. We release our dataset and the benchmarks to facilitate future research in multimodal learning, especially to motivate targeted improvements for applications in scientific domains.