 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLLA: Optimizing the Lifetime and Location of Arrays to Reduce the Memory Usage of Neural Networks
Nov 02, 2022The size of deep neural networks has grown exponentially in recent years. Unfortunately, hardware devices have not kept pace with the rapidly increasing memory requirements. To cope with this, researchers have turned to techniques such as spilling and recomputation, which increase training time, or reduced precision and model pruning, which can affect model accuracy. We present OLLA, an algorithm that optimizes the lifetime and memory location of the tensors used to train neural networks. Our method reduces the memory usage of existing neural networks, without needing any modification to the models or their training procedures. We formulate the problem as a joint integer linear program (ILP). We present several techniques to simplify the encoding of the problem, and enable our approach to scale to the size of state-of-the-art neural networks using an off-the-shelf ILP solver. We experimentally demonstrate that OLLA only takes minutes if not seconds to allow the training of neural networks using one-third less memory on average.
Using Graph Neural Networks to model the performance of Deep Neural Networks
Aug 27, 2021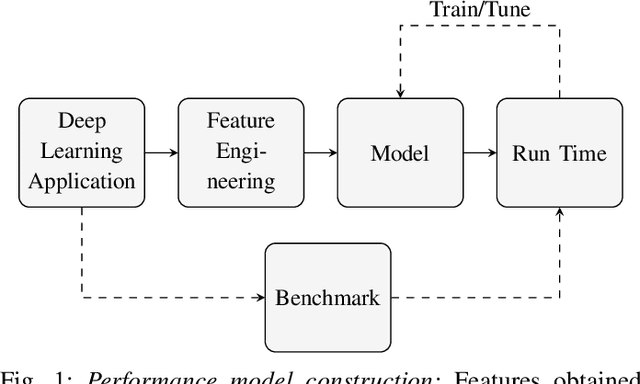
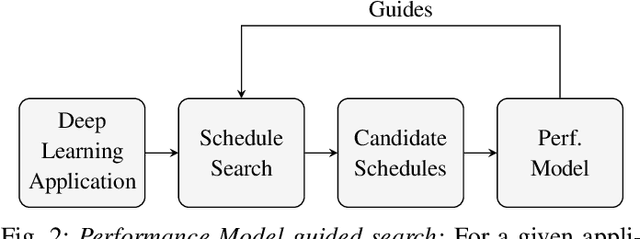
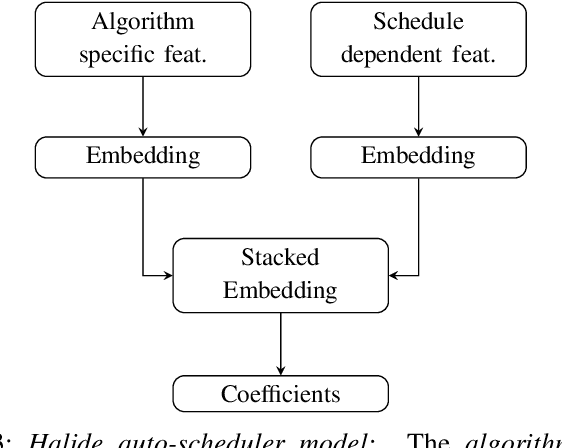
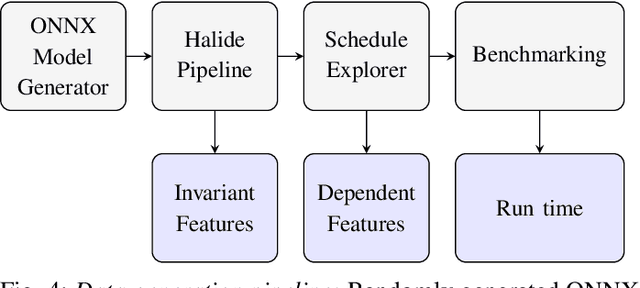
With the unprecedented proliferation of machine learning software, there is an ever-increasing need to generate efficient code for such applications. State-of-the-art deep-learning compilers like TVM and Halide incorporate a learning-based performance model to search the space of valid implementations of a given deep learning algorithm. For a given application, the model generates a performance metric such as the run time without executing the application on hardware. Such models speed up the compilation process by obviating the need to benchmark an enormous number of candidate implementations, referred to as schedules, on hardware. Existing performance models employ feed-forward networks, recurrent networks, or decision tree ensembles to estimate the performance of different implementations of a neural network. Graphs present a natural and intuitive way to model deep-learning networks where each node represents a computational stage or operation. Incorporating the inherent graph structure of these workloads in the performance model can enable a better representation and learning of inter-stage interactions. The accuracy of a performance model has direct implications on the efficiency of the search strategy, making it a crucial component of this class of deep-learning compilers. In this work, we develop a novel performance model that adopts a graph representation. In our model, each stage of computation represents a node characterized by features that capture the operations performed by the stage. The interaction between nodes is achieved using graph convolutions. Experimental evaluation shows a 7:75x and 12x reduction in prediction error compared to the Halide and TVM models, respectively.