 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
A Paragraph-level Multi-task Learning Model for Scientific Fact-Verification
Jan 25, 2021
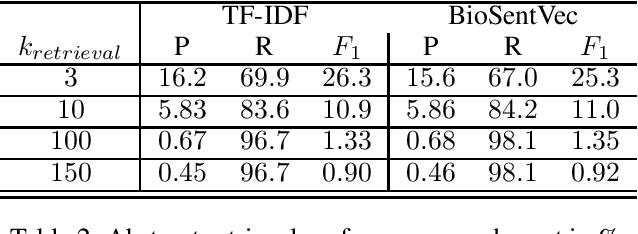
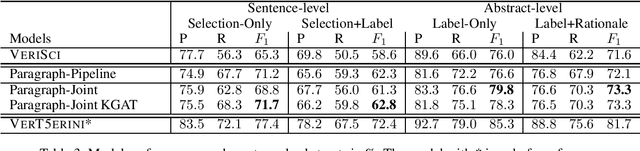
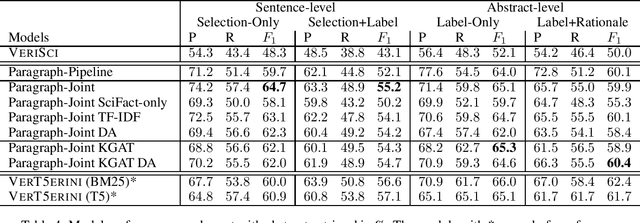
Even for domain experts, it is a non-trivial task to verify a scientific claim by providing supporting or refuting evidence rationales. The situation worsens as misinformation is proliferated on social media or news websites, manually or programmatically, at every moment. As a result, an automatic fact-verification tool becomes crucial for combating the spread of misinformation. In this work, we propose a novel, paragraph-level, multi-task learning model for the SciFact task by directly computing a sequence of contextualized sentence embeddings from a BERT model and jointly training the model on rationale selection and stance prediction.
MELINDA: A Multimodal Dataset for Biomedical Experiment Method Classification
Dec 16, 2020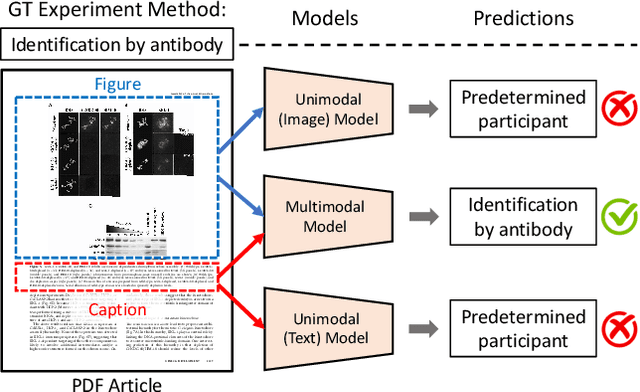
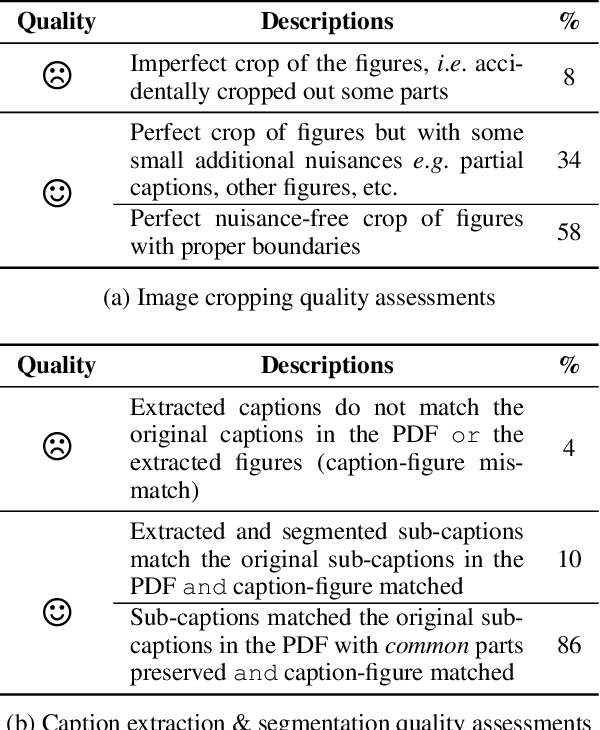

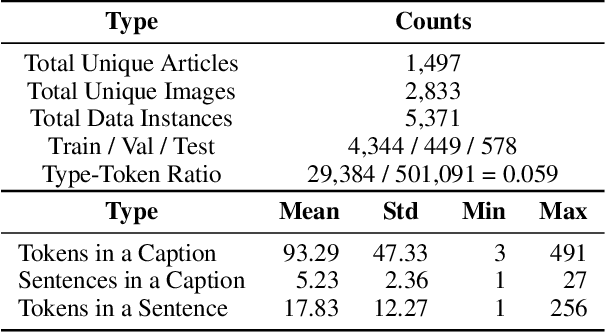
We introduce a new dataset, MELINDA, for Multimodal biomEdicaL experImeNt methoD clAssification. The dataset is collected in a fully automated distant supervision manner, where the labels are obtained from an existing curated database, and the actual contents are extracted from papers associated with each of the records in the database. We benchmark various state-of-the-art NLP and computer vision models, including unimodal models which only take either caption texts or images as inputs, and multimodal models. Extensive experiments and analysis show that multimodal models, despite outperforming unimodal ones, still need improvements especially on a less-supervised way of grounding visual concepts with languages, and better transferability to low resource domains. We release our dataset and the benchmarks to facilitate future research in multimodal learning, especially to motivate targeted improvements for applications in scientific domains.
Discourse Tagging for Scientific Evidence Extraction
Sep 10, 2019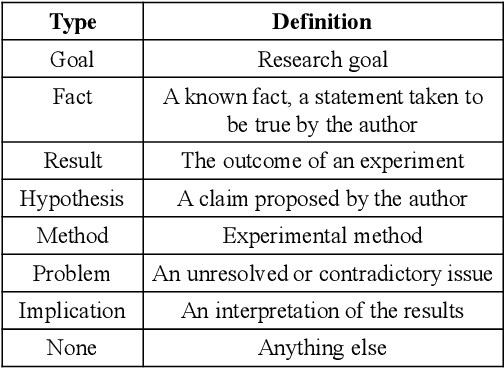

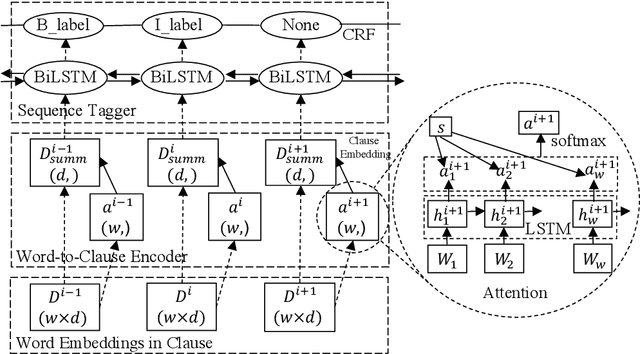

The biomedical scientific literature comprises a crucial, sometimes life-saving, natural language resource whose size is accelerating over time. The information in this resource tends to follow a style of discourse that is intended to provide scientific explanations for various pieces of evidence derived from experimental findings. Studying the rhetorical structure of the narrative discourse could enable more powerful information extraction methods to automatically construct models of scientific argument from full-text papers. In this paper, we apply richly contextualized deep representation learning to the analysis of scientific discourse structures as a clause-tagging task. We improve the current state-of-the-art clause-level sequence tagging over text clauses for a set of discourse types (e.g. "hypothesis", "result", "implication", etc.) on scientific paragraphs. Our model uses contextualized embeddings, word-to-clause encoder, and clause-level sequence tagging models and achieves F1 performance of 0.784.
An Investigation into the Pedagogical Features of Documents
Aug 01, 2017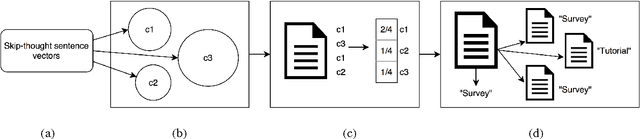

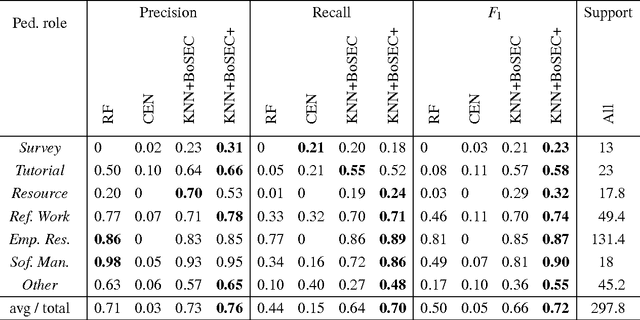
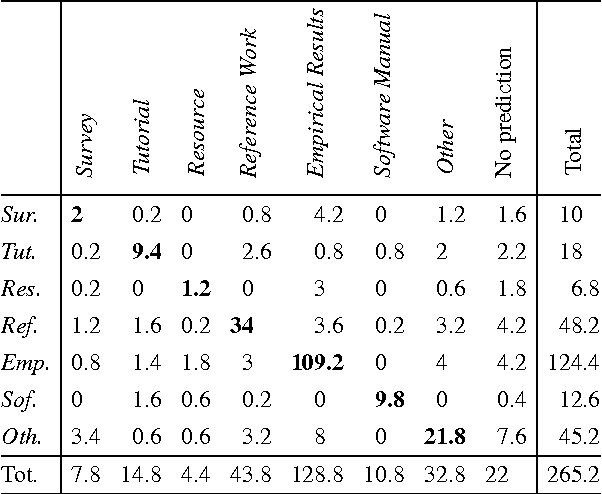
Characterizing the content of a technical document in terms of its learning utility can be useful for applications related to education, such as generating reading lists from large collections of documents. We refer to this learning utility as the "pedagogical value" of the document to the learner. While pedagogical value is an important concept that has been studied extensively within the education domain, there has been little work exploring it from a computational, i.e., natural language processing (NLP), perspective. To allow a computational exploration of this concept, we introduce the notion of "pedagogical roles" of documents (e.g., Tutorial and Survey) as an intermediary component for the study of pedagogical value. Given the lack of available corpora for our exploration, we create the first annotated corpus of pedagogical roles and use it to test baseline techniques for automatic prediction of such roles.