 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Tagging for Scientific Evidence Extraction
Paper and Code
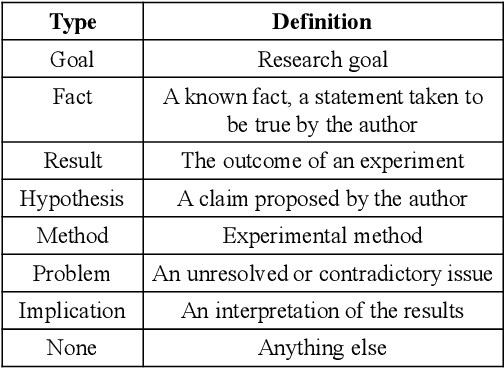

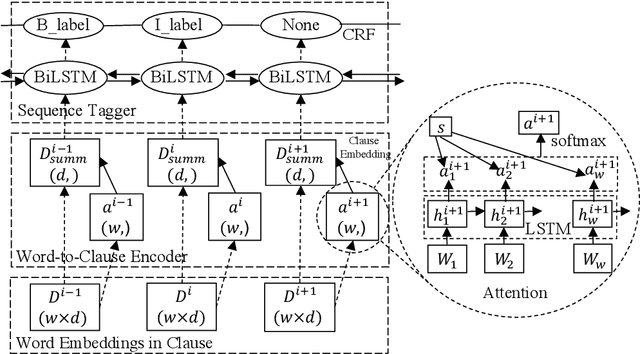

The biomedical scientific literature comprises a crucial, sometimes life-saving, natural language resource whose size is accelerating over time. The information in this resource tends to follow a style of discourse that is intended to provide scientific explanations for various pieces of evidence derived from experimental findings. Studying the rhetorical structure of the narrative discourse could enable more powerful information extraction methods to automatically construct models of scientific argument from full-text papers. In this paper, we apply richly contextualized deep representation learning to the analysis of scientific discourse structures as a clause-tagging task. We improve the current state-of-the-art clause-level sequence tagging over text clauses for a set of discourse types (e.g. "hypothesis", "result", "implication", etc.) on scientific paragraphs. Our model uses contextualized embeddings, word-to-clause encoder, and clause-level sequence tagging models and achieves F1 performance of 0.784.