 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective and Dynamic Beam Search for Story Generation
Oct 23, 2023



Storytelling's captivating potential makes it a fascinating research area, with implications for entertainment, education, therapy, and cognitive studies. In this paper, we propose Affective Story Generator (AffGen) for generating interesting narratives. AffGen introduces "intriguing twists" in narratives by employing two novel techniques-Dynamic Beam Sizing and Affective Reranking. Dynamic Beam Sizing encourages less predictable, more captivating word choices using a contextual multi-arm bandit model. Affective Reranking prioritizes sentence candidates based on affect intensity. Our empirical evaluations, both automatic and human, demonstrate AffGen's superior performance over existing baselines in generating affectively charged and interesting narratives. Our ablation study and analysis provide insights into the strengths and weaknesses of AffGen.
Traffic-Domain Video Question Answering with Automatic Captioning
Jul 18, 2023


Video Question Answering (VidQA) exhibits remarkable potential in facilitating advanced machine reasoning capabilities within the domains of Intelligent Traffic Monitoring and Intelligent Transportation Systems. Nevertheless, the integration of urban traffic scene knowledge into VidQA systems has received limited attention in previous research endeavors. In this work, we present a novel approach termed Traffic-domain Video Question Answering with Automatic Captioning (TRIVIA), which serves as a weak-supervision technique for infusing traffic-domain knowledge into large video-language models. Empirical findings obtained from the SUTD-TrafficQA task highlight the substantial enhancements achieved by TRIVIA, elevating the accuracy of representative video-language models by a remarkable 6.5 points (19.88%) compared to baseline settings. This pioneering methodology holds great promise for driving advancements in the field, inspiring researchers and practitioners alike to unlock the full potential of emerging video-language models in traffic-related applications.
VIPHY: Probing "Visible" Physical Commonsense Knowledge
Sep 15, 2022
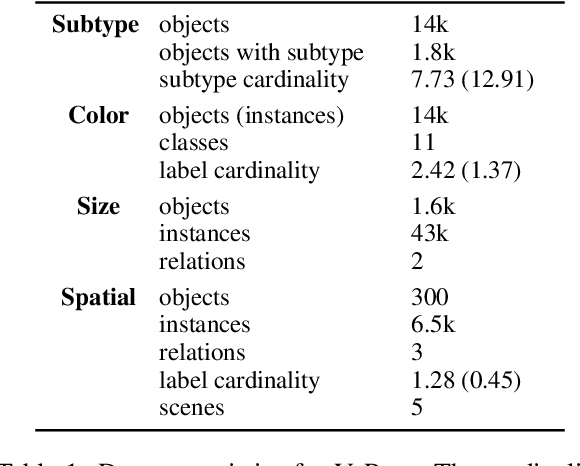
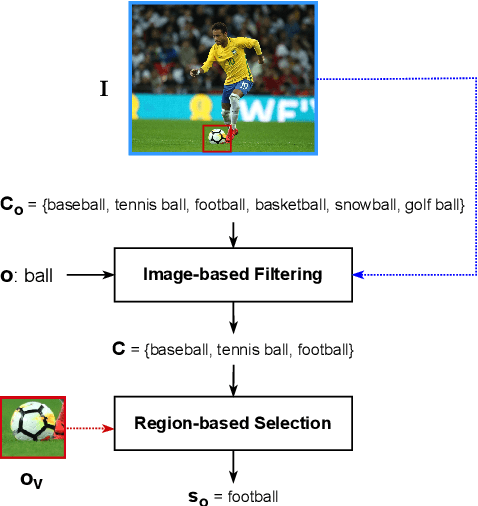

In recent years, vision-language models (VLMs) have shown remarkable performance on visual reasoning tasks (e.g. attributes, location). While such tasks measure the requisite knowledge to ground and reason over a given visual instance, they do not, however, measure the ability of VLMs to retain and generalize such knowledge. In this work, we evaluate their ability to acquire "visible" physical knowledge -- the information that is easily accessible from images of static scenes, particularly across the dimensions of object color, size and space. We build an automatic pipeline to derive a comprehensive knowledge resource for calibrating and probing these models. Our results indicate a severe gap between model and human performance across all three tasks. Furthermore, our caption pretrained baseline (CapBERT) significantly outperforms VLMs on both size and spatial tasks -- highlighting that despite sufficient access to ground language with visual modality, they struggle to retain such knowledge. The dataset and code are available at https://github.com/Axe--/ViPhy .
PInKS: Preconditioned Commonsense Inference with Minimal Supervision
Jun 16, 2022

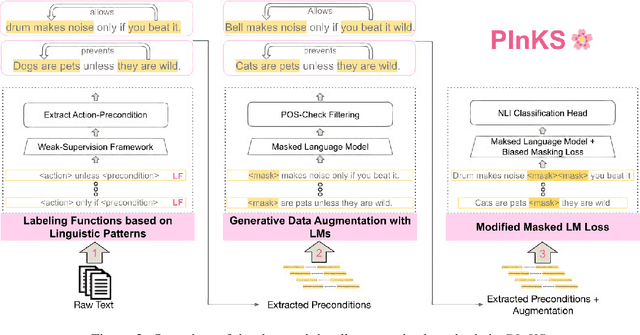
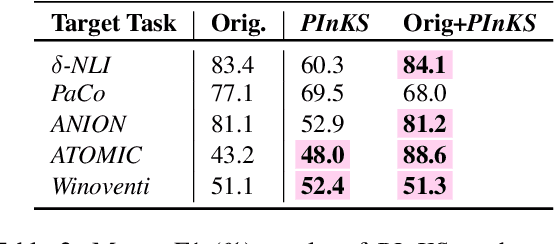
Reasoning with preconditions such as "glass can be used for drinking water unless the glass is shattered" remains an open problem for language models. The main challenge lies in the scarcity of preconditions data and the model's lack of support for such reasoning. We present PInKS, Preconditioned Commonsense Inference with WeaK Supervision, an improved model for reasoning with preconditions through minimum supervision. We show, both empirically and theoretically, that PInKS improves the results on benchmarks focused on reasoning with the preconditions of commonsense knowledge (up to 40% Macro-F1 scores). We further investigate PInKS through PAC-Bayesian informativeness analysis, precision measures, and ablation study.
Evaluating Machine Common Sense via Cloze Testing
Jan 19, 2022Language models (LMs) show state of the art performance for common sense (CS) question answering, but whether this ability implies a human-level mastery of CS remains an open question. Understanding the limitations and strengths of LMs can help researchers improve these models, potentially by developing novel ways of integrating external CS knowledge. We devise a series of tests and measurements to systematically quantify their performance on different aspects of CS. We propose the use of cloze testing combined with word embeddings to measure the LM's robustness and confidence. Our results show than although language models tend to achieve human-like accuracy, their confidence is subpar. Future work can leverage this information to build more complex systems, such as an ensemble of symbolic and distributed knowledge.
CoreQuisite: Circumstantial Preconditions of Common Sense Knowledge
Apr 18, 2021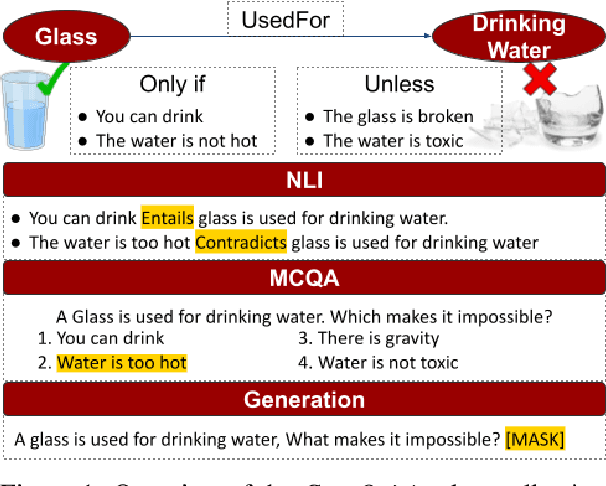

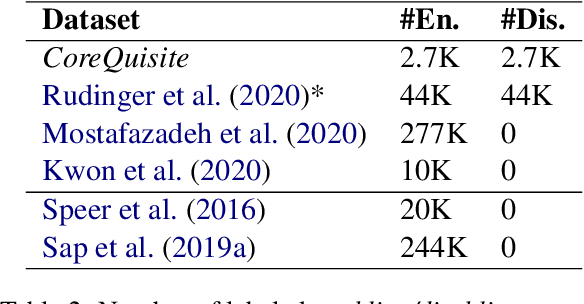
The task of identifying and reasoning with circumstantial preconditions associated with everyday facts is natural to humans. It is unclear whether state-of-the-art language models (LMs) understand the implicit preconditions that enable or invalidate commonsense facts, such as "A glass is used for drinking water", Despite their impressive accuracy on existing commonsense tasks. In this paper, we propose a new problem of reasoning with circumstantial preconditions, and present a dataset, called CoreQuisite, which annotates commonsense facts with preconditions expressed in natural language. Based on this resource, we create three canonical evaluation tasks and use them to examine the capability of existing LMs to understand situational pre-conditions. Our results show that there is a 10-30%gap between machine and human performance on our tasks. We make all resources and software publicly available.
Consolidating Commonsense Knowledge
Jun 22, 2020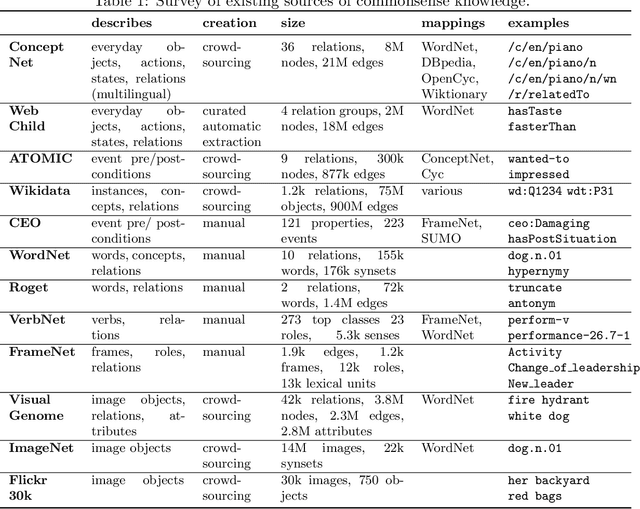
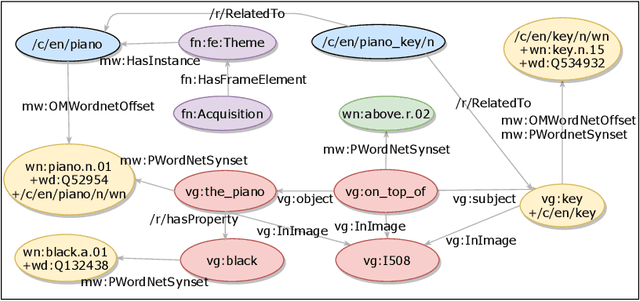

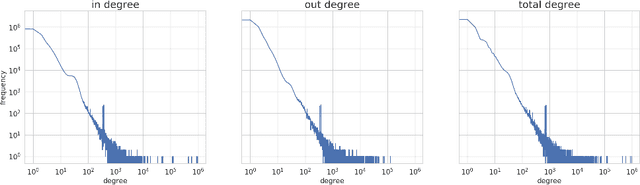
Commonsense reasoning is an important aspect of building robust AI systems and is receiving significant attention in the natural language understanding, computer vision, and knowledge graphs communities. At present, a number of valuable commonsense knowledge sources exist, with different foci, strengths, and weaknesses. In this paper, we list representative sources and their properties. Based on this survey, we propose principles and a representation model in order to consolidate them into a Common Sense Knowledge Graph (CSKG). We apply this approach to consolidate seven separate sources into a first integrated CSKG. We present statistics of CSKG, present initial investigations of its utility on four QA datasets, and list learned lessons.