 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Documents Drafting with Fine-Tuned Pre-Trained Large Language Model
Jun 06, 2024With the development of large-scale Language Models (LLM), fine-tuning pre-trained LLM has become a mainstream paradigm for solving downstream tasks of natural language processing. However, training a language model in the legal field requires a large number of legal documents so that the language model can learn legal terminology and the particularity of the format of legal documents. The typical NLP approaches usually rely on many manually annotated data sets for training. However, in the legal field application, it is difficult to obtain a large number of manually annotated data sets, which restricts the typical method applied to the task of drafting legal documents. The experimental results of this paper show that not only can we leverage a large number of annotation-free legal documents without Chinese word segmentation to fine-tune a large-scale language model, but more importantly, it can fine-tune a pre-trained LLM on the local computer to achieve the generating legal document drafts task, and at the same time achieve the protection of information privacy and to improve information security issues.
An Evaluation Dataset for Legal Word Embedding: A Case Study On Chinese Codex
Mar 29, 2022
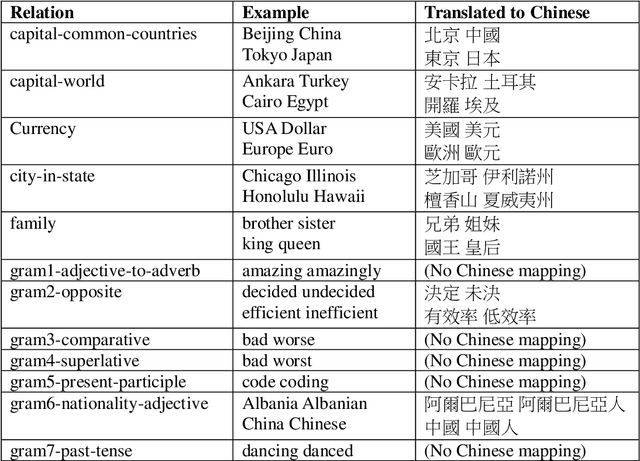
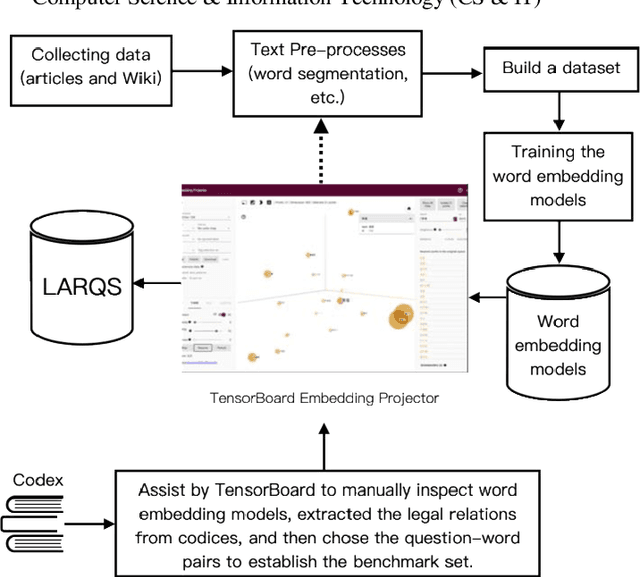
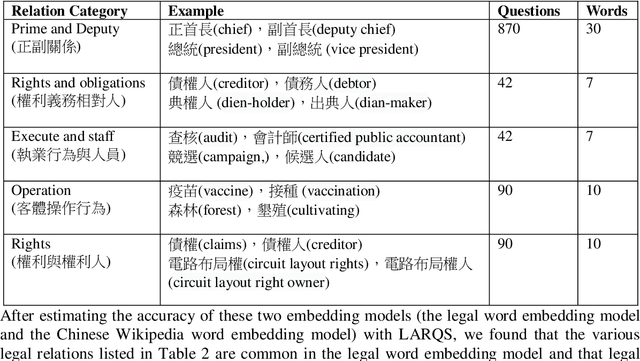
Word embedding is a modern distributed word representations approach widely used in many natural language processing tasks. Converting the vocabulary in a legal document into a word embedding model facilitates subjecting legal documents to machine learning, deep learning, and other algorithms and subsequently performing the downstream tasks of natural language processing vis-\`a-vis, for instance, document classification, contract review, and machine translation. The most common and practical approach of accuracy evaluation with the word embedding model uses a benchmark set with linguistic rules or the relationship between words to perform analogy reasoning via algebraic calculation. This paper proposes establishing a 1,134 Legal Analogical Reasoning Questions Set (LARQS) from the 2,388 Chinese Codex corpus using five kinds of legal relations, which are then used to evaluate the accuracy of the Chinese word embedding model. Moreover, we discovered that legal relations might be ubiquitous in the word embedding model.
Mitigating Domain Mismatch in Face Recognition Using Style Matching
Feb 26, 2021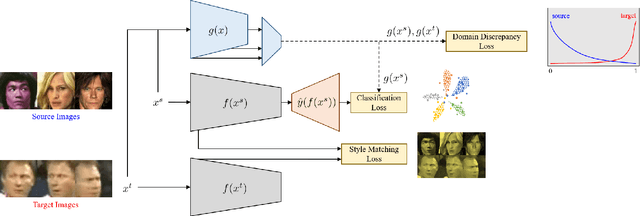
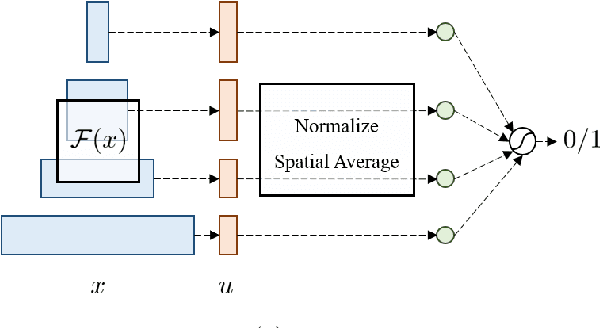

Despite outstanding performance on public benchmarks, face recognition still suffers due to domain mismatch between training (source) and testing (target) data. Furthermore, these domains are not shared classes, which complicates domain adaptation. Since this is also a fine-grained classification problem which does not strictly follow the low-density separation principle, conventional domain adaptation approaches do not resolve these problems. In this paper, we formulate domain mismatch in face recognition as a style mismatch problem for which we propose two methods. First, we design a domain discriminator with human-level judgment to mine target-like images in the training data to mitigate the domain gap. Second, we extract style representations in low-level feature maps of the backbone model, and match the style distributions of the two domains to find a common style representation. Evaluations on verification and open-set and closed-set identification protocols show that both methods yield good improvements, and that performance is more robust if they are combined. Our approach is competitive with related work, and its effectiveness is verified in a practical application.
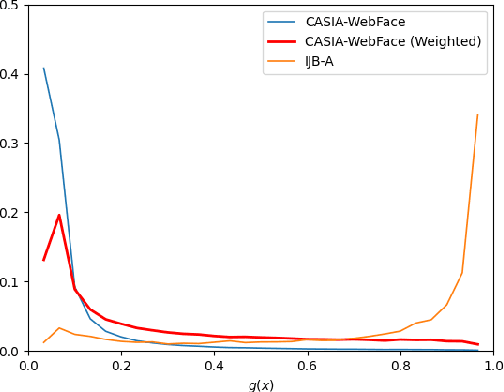
Domain Adapting Ability of Self-Supervised Learning for Face Recognition
Feb 26, 2021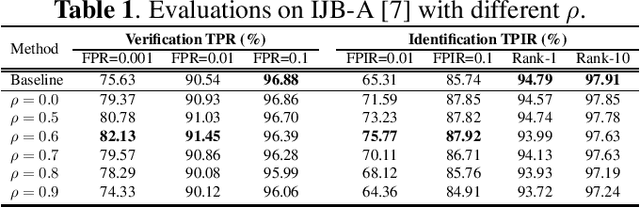
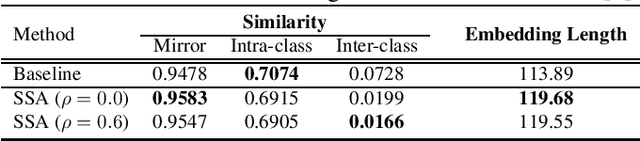

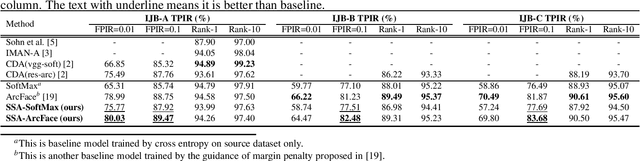
Although deep convolutional networks have achieved great performance in face recognition tasks, the challenge of domain discrepancy still exists in real world applications. Lack of domain coverage of training data (source domain) makes the learned models degenerate in a testing scenario (target domain). In face recognition tasks, classes in two domains are usually different, so classical domain adaptation approaches, assuming there are shared classes in domains, may not be reasonable solutions for this problem. In this paper, self-supervised learning is adopted to learn a better embedding space where the subjects in target domain are more distinguishable. The learning goal is maximizing the similarity between the embeddings of each image and its mirror in both domains. The experiments show its competitive results compared with prior works. To know the reason why it can achieve such performance, we further discuss how this approach affects the learning of embeddings.