 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All LLM-Generated Data Are Equal: Rethinking Data Weighting in Text Classification
Oct 28, 2024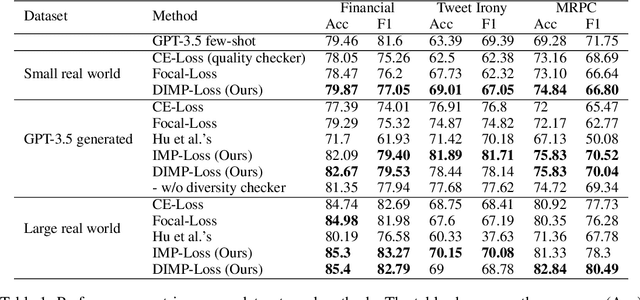
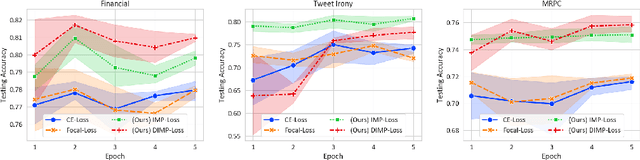
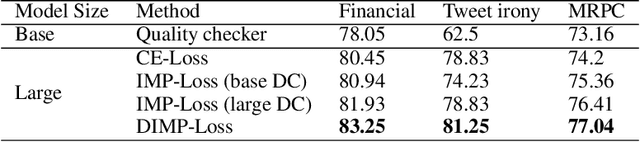
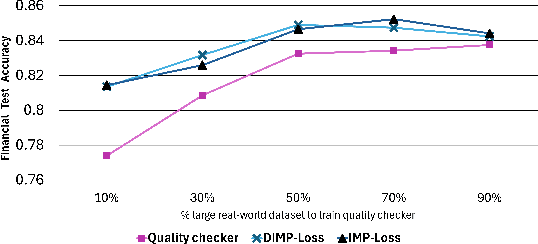
Synthetic data augmentation via large language models (LLMs) allows researchers to leverage additional training data, thus enhancing the performance of downstream tasks, especially when real-world data is scarce. However, the generated data can deviate from the real-world data, and this misalignment can bring deficient outcomes while applying the trained model to applications. Therefore, we proposed efficient weighted-loss approaches to align synthetic data with real-world distribution by emphasizing high-quality and diversified data generated by LLMs with using merely a little real-world data. We empirically assessed the effectiveness of our method on multiple text classification tasks, and the results showed leveraging our approaches on a BERT-level model robustly outperformed standard cross-entropy and other data weighting approaches, providing potential solutions to effectively leveraging synthetic data from any suitable data generator for model training.