 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituation and Behavior Understanding by Trope Detection on Films
Jan 19, 2021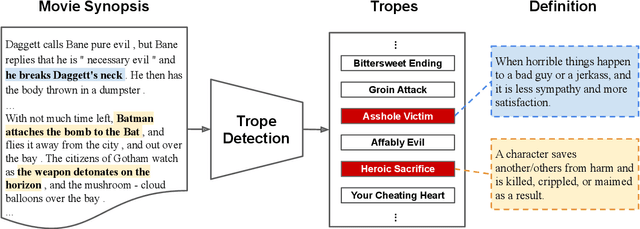
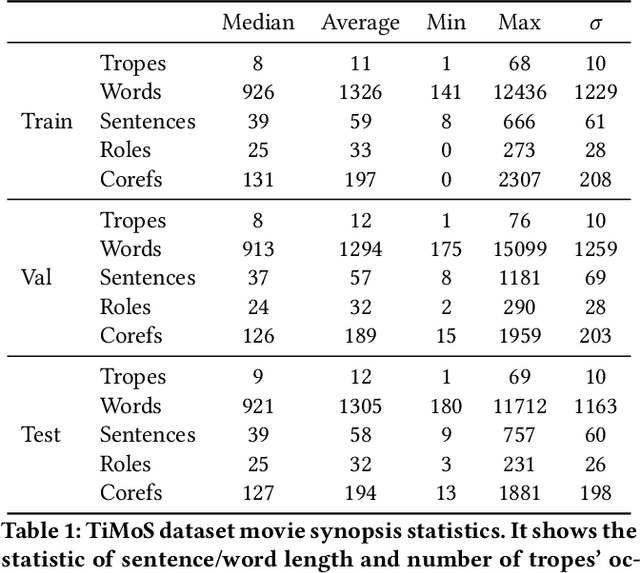
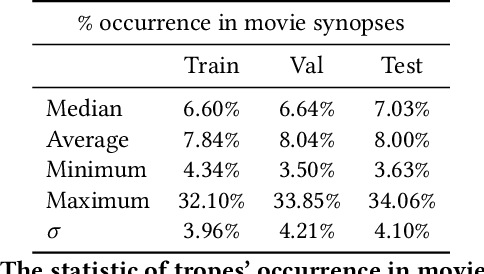
The human ability of deep cognitive skills are crucial for the development of various real-world applications that process diverse and abundant user generated input. While recent progress of deep learning and natural language processing have enabled learning system to reach human performance on some benchmarks requiring shallow semantics, such human ability still remains challenging for even modern contextual embedding models, as pointed out by many recent studies. Existing machine comprehension datasets assume sentence-level input, lack of casual or motivational inferences, or could be answered with question-answer bias. Here, we present a challenging novel task, trope detection on films, in an effort to create a situation and behavior understanding for machines. Tropes are storytelling devices that are frequently used as ingredients in recipes for creative works. Comparing to existing movie tag prediction tasks, tropes are more sophisticated as they can vary widely, from a moral concept to a series of circumstances, and embedded with motivations and cause-and-effects. We introduce a new dataset, Tropes in Movie Synopses (TiMoS), with 5623 movie synopses and 95 different tropes collecting from a Wikipedia-style database, TVTropes. We present a multi-stream comprehension network (MulCom) leveraging multi-level attention of words, sentences, and role relations. Experimental result demonstrates that modern models including BERT contextual embedding, movie tag prediction systems, and relational networks, perform at most 37% of human performance (23.97/64.87) in terms of F1 score. Our MulCom outperforms all modern baselines, by 1.5 to 5.0 F1 score and 1.5 to 3.0 mean of average precision (mAP) score. We also provide a detailed analysis and human evaluation to pave ways for future research.
End-to-End Video Question-Answer Generation with Generator-Pretester Network
Jan 05, 2021

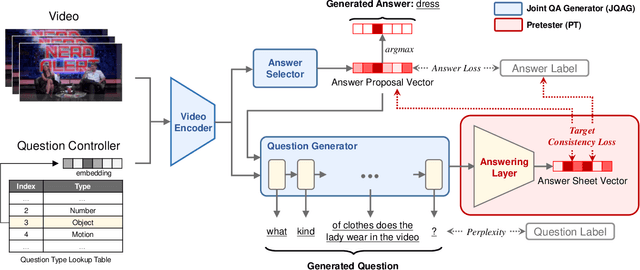

We study a novel task, Video Question-Answer Generation (VQAG), for challenging Video Question Answering (Video QA) task in multimedia. Due to expensive data annotation costs, many widely used, large-scale Video QA datasets such as Video-QA, MSVD-QA and MSRVTT-QA are automatically annotated using Caption Question Generation (CapQG) which inputs captions instead of the video itself. As captions neither fully represent a video, nor are they always practically available, it is crucial to generate question-answer pairs based on a video via Video Question-Answer Generation (VQAG). Existing video-to-text (V2T) approaches, despite taking a video as the input, only generate a question alone. In this work, we propose a novel model Generator-Pretester Network that focuses on two components: (1) The Joint Question-Answer Generator (JQAG) which generates a question with its corresponding answer to allow Video Question "Answering" training. (2) The Pretester (PT) verifies a generated question by trying to answer it and checks the pretested answer with both the model's proposed answer and the ground truth answer. We evaluate our system with the only two available large-scale human-annotated Video QA datasets and achieves state-of-the-art question generation performances. Furthermore, using our generated QA pairs only on the Video QA task, we can surpass some supervised baselines. We apply our generated questions to Video QA applications and surpasses some supervised baselines using generated questions only. As a pre-training strategy, we outperform both CapQG and transfer learning approaches when employing semi-supervised (20%) or fully supervised learning with annotated data. These experimental results suggest the novel perspectives for Video QA training.
GDN: A Coarse-To-Fine Representation for End-To-End 6-DoF Grasp Detection
Nov 11, 2020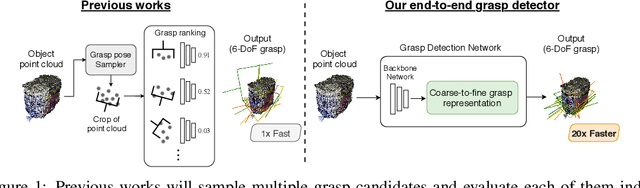
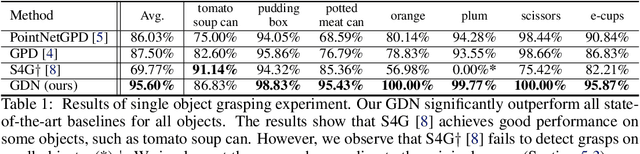
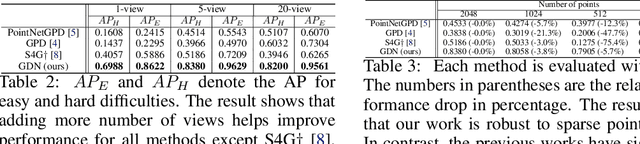
We proposed an end-to-end grasp detection network, Grasp Detection Network (GDN), cooperated with a novel coarse-to-fine (C2F) grasp representation design to detect diverse and accurate 6-DoF grasps based on point clouds. Compared to previous two-stage approaches which sample and evaluate multiple grasp candidates, our architecture is at least 20 times faster. It is also 8% and 40% more accurate in terms of the success rate in single object scenes and the complete rate in clutter scenes, respectively. Our method shows superior results among settings with different number of views and input points. Moreover, we propose a new AP-based metric which considers both rotation and transition errors, making it a more comprehensive evaluation tool for grasp detection models.
Unified Representation Learning for Cross Model Compatibility
Aug 11, 2020

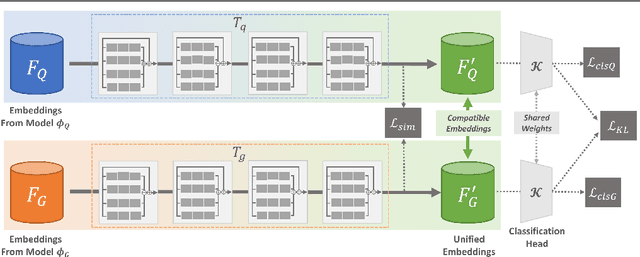

We propose a unified representation learning framework to address the Cross Model Compatibility (CMC) problem in the context of visual search applications. Cross compatibility between different embedding models enables the visual search systems to correctly recognize and retrieve identities without re-encoding user images, which are usually not available due to privacy concerns. While there are existing approaches to address CMC in face identification, they fail to work in a more challenging setting where the distributions of embedding models shift drastically. The proposed solution improves CMC performance by introducing a light-weight Residual Bottleneck Transformation (RBT) module and a new training scheme to optimize the embedding spaces. Extensive experiments demonstrate that our proposed solution outperforms previous approaches by a large margin for various challenging visual search scenarios of face recognition and person re-identification.
xCos: An Explainable Cosine Metric for Face Verification Task
Mar 11, 2020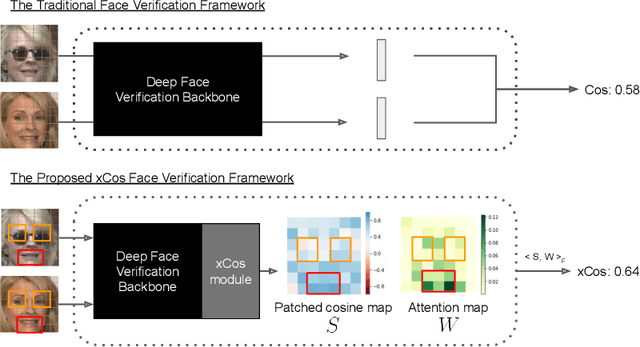
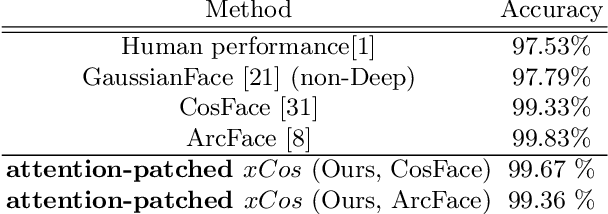
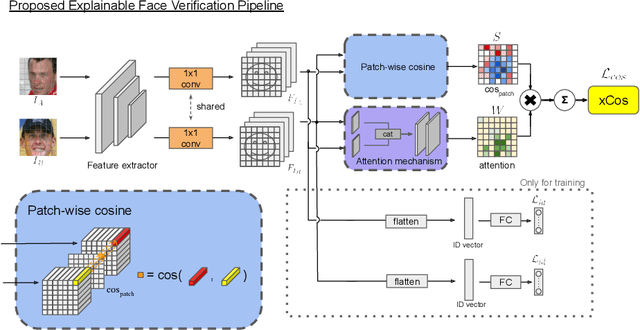
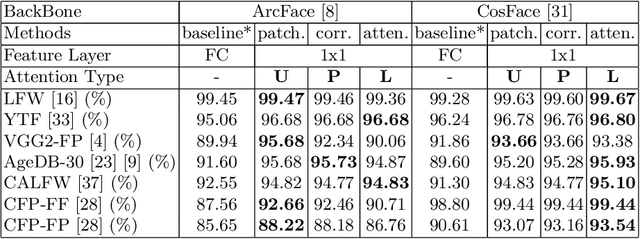
We study the XAI (explainable AI) on the face recognition task, particularly the face verification here. Face verification is a crucial task in recent days and it has been deployed to plenty of applications, such as access control, surveillance, and automatic personal log-on for mobile devices. With the increasing amount of data, deep convolutional neural networks can achieve very high accuracy for the face verification task. Beyond exceptional performances, deep face verification models need more interpretability so that we can trust the results they generate. In this paper, we propose a novel similarity metric, called explainable cosine ($xCos$), that comes with a learnable module that can be plugged into most of the verification models to provide meaningful explanations. With the help of $xCos$, we can see which parts of the 2 input faces are similar, where the model pays its attention to, and how the local similarities are weighted to form the output $xCos$ score. We demonstrate the effectiveness of our proposed method on LFW and various competitive benchmarks, resulting in not only providing novel and desiring model interpretability for face verification but also ensuring the accuracy as plugging into existing face recognition models.
Learnable Gated Temporal Shift Module for Deep Video Inpainting
Jul 09, 2019
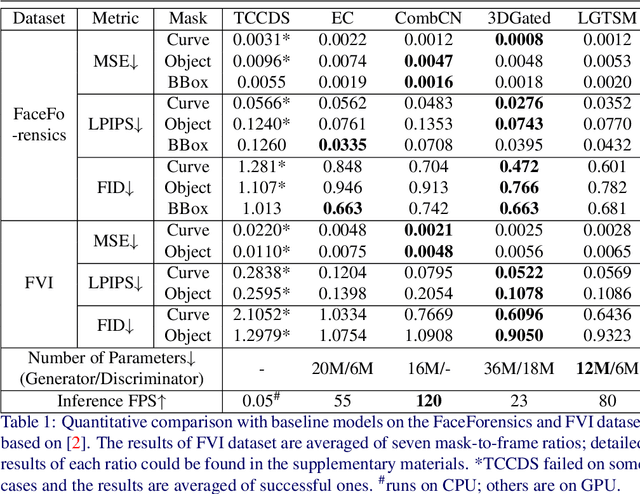
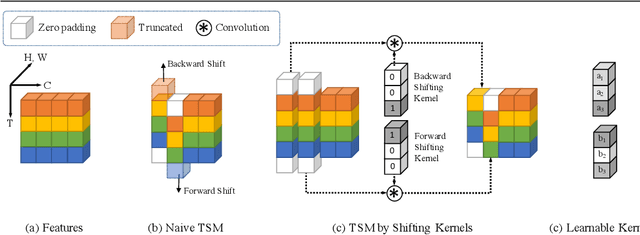
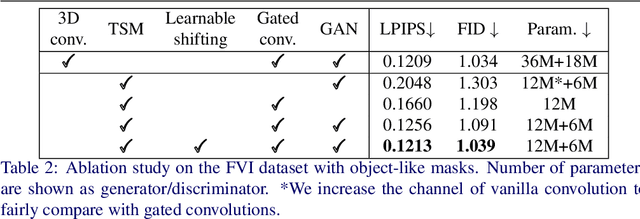
How to efficiently utilize temporal information to recover videos in a consistent way is the main issue for video inpainting problems. Conventional 2D CNNs have achieved good performance on image inpainting but often lead to temporally inconsistent results where frames will flicker when applied to videos (see https://www.youtube.com/watch?v=87Vh1HDBjD0&list=PLPoVtv-xp_dL5uckIzz1PKwNjg1yI0I94&index=1); 3D CNNs can capture temporal information but are computationally intensive and hard to train. In this paper, we present a novel component termed Learnable Gated Temporal Shift Module (LGTSM) for video inpainting models that could effectively tackle arbitrary video masks without additional parameters from 3D convolutions. LGTSM is designed to let 2D convolutions make use of neighboring frames more efficiently, which is crucial for video inpainting. Specifically, in each layer, LGTSM learns to shift some channels to its temporal neighbors so that 2D convolutions could be enhanced to handle temporal information. Meanwhile, a gated convolution is applied to the layer to identify the masked areas that are poisoning for conventional convolutions. On the FaceForensics and Free-form Video Inpainting (FVI) dataset, our model achieves state-of-the-art results with simply 33% of parameters and inference time.
Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN
Apr 28, 2019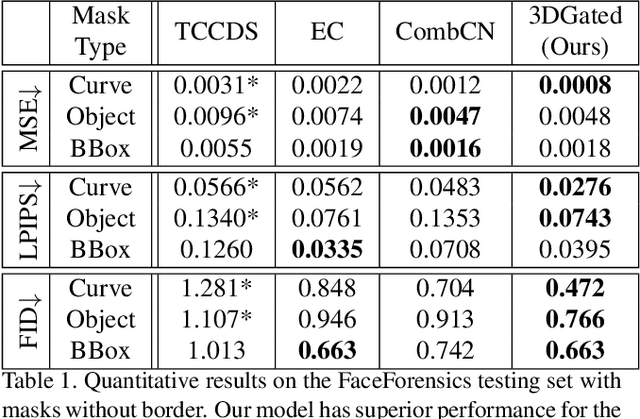
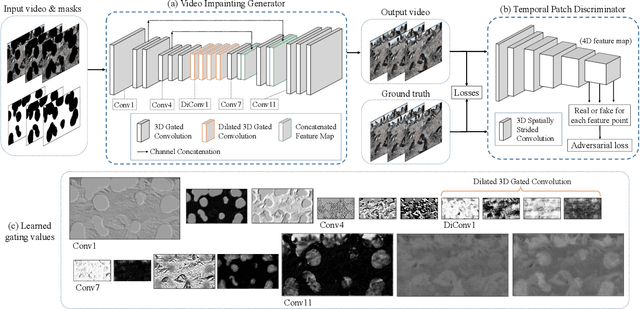
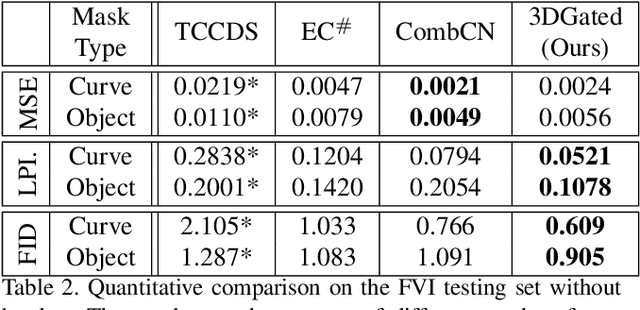
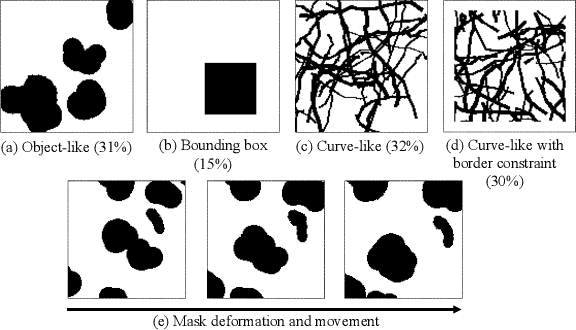
Free-form video inpainting is a very challenging task that could be widely used for video editing such as text removal. Existing patch-based methods could not handle non-repetitive structures such as faces, while directly applying image-based inpainting models to videos will result in temporal inconsistency (see http://bit.ly/2Fu1n6b). In this paper, we introduce a deep learn-ing based free-form video inpainting model, with proposed 3D gated convolutions to tackle the uncertainty of free-form masks and a novel Temporal PatchGAN loss to enhance temporal consistency. In addition, we collect videos and design a free-form mask generation algorithm to build the free-form video inpainting (FVI) dataset for training and evaluation of video inpainting models. We demonstrate the benefits of these components and experiments on both the FaceForensics and our FVI dataset suggest that our method is superior to existing ones.
VORNet: Spatio-temporally Consistent Video Inpainting for Object Removal
Apr 14, 2019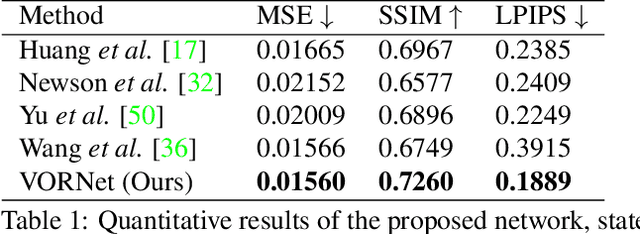
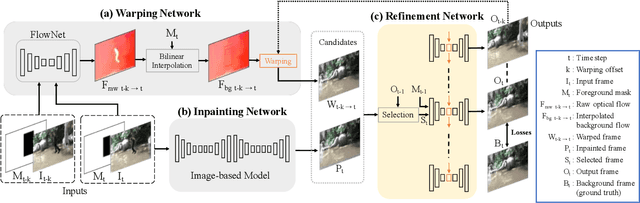
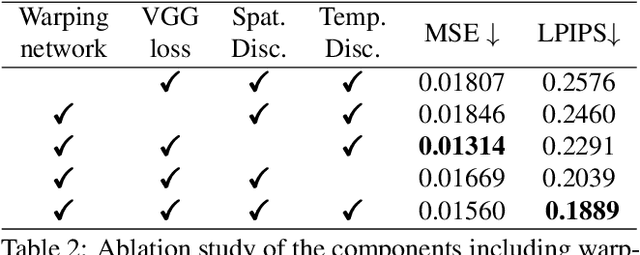
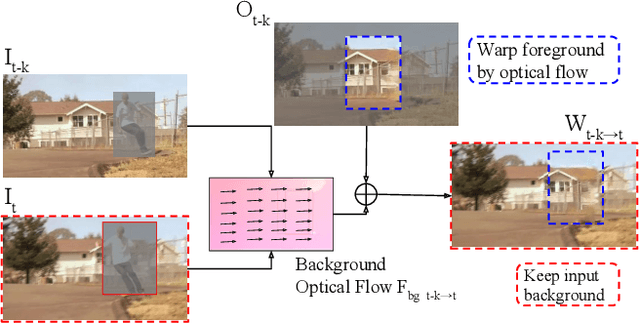
Video object removal is a challenging task in video processing that often requires massive human efforts. Given the mask of the foreground object in each frame, the goal is to complete (inpaint) the object region and generate a video without the target object. While recently deep learning based methods have achieved great success on the image inpainting task, they often lead to inconsistent results between frames when applied to videos. In this work, we propose a novel learning-based Video Object Removal Network (VORNet) to solve the video object removal task in a spatio-temporally consistent manner, by combining the optical flow warping and image-based inpainting model. Experiments are done on our Synthesized Video Object Removal (SVOR) dataset based on the YouTube-VOS video segmentation dataset, and both the objective and subjective evaluation demonstrate that our VORNet generates more spatially and temporally consistent videos compared with existing methods.