 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-OP: Cross-Morphology Whole-Body Teleoperation via MPC Retargeting
Jun 06, 2026Whole-body teleoperation is essential for scalable robot data collection in loco-manipulation tasks, yet existing approaches relying on exoskeleton suits or multi-camera setups impose prohibitive cost, complexity, and environmental constraints. Recent methods using a single extended reality (XR) device with end-to-end reinforcement learning policies partially address these limitations but require robot-specific retraining, suffer from out-of-distribution failures, and rely on motion retargeting that neglects dynamic feasibility. We propose a hierarchical whole-body teleoperation framework driven by a single XR device that generalizes across diverse robot morphologies without retraining robot-specific policies. A Model Predictive Control (MPC)-based motion retargeter jointly optimizes alignment with the operator's intent and the robot's dynamic feasibility, generating optimal commands for existing low-level controllers. To ensure robust online execution, we introduce a state synchronization method that resets the simulator state at each MPC step to handle noisy real-world measurements and contact sensitivity, and integrate SLAM-based global pose feedback to mitigate long-term drift. Simulation results show higher success rates on whole-body control tasks for both a humanoid (over 30% lower completion time and 20% lower power consumption) and a mobile manipulator (zero collisions) compared to baselines. Real-world experiments further validate the effectiveness and flexibility of our method, demonstrating the successful deployment of the proposed retargeter on both platforms for whole-body control tasks and the ease of allowing users to adjust teleoperation behavior based on their preferences. This plug-and-play framework offers a scalable, morphology-agnostic solution for whole-body robot teleoperation, enabling real-time behavioral customization and broad applicability across platforms.
A Simple Approach for General Task-Oriented Picking using Placing constraints
Apr 03, 2023



Pick-and-place is an important manipulation task in domestic or manufacturing applications. There exist many works focusing on grasp detection with high picking success rate but lacking consideration of downstream manipulation tasks (e.g., placing). Although some research works proposed methods to incorporate task conditions into grasp selection, most of them are data-driven and are therefore hard to adapt to arbitrary operating environments. Observing this challenge, we propose a general task-oriented pick-place framework that treats the target task and operating environment as placing constraints into grasping optimization. Combined with existing grasp detectors, our framework is able to generate feasible grasps for different downstream tasks and adapt to environmental changes without time-consuming re-training processes. Moreover, the framework can accept different definitions of placing constraints, so it is easy to integrate with other modules. Experiments in the simulator and real-world on multiple pick-place tasks are conducted to evaluate the performance of our framework. The result shows that our framework achieves a high and robust task success rate on a wide variety of the pick-place tasks.
ODIP: Towards Automatic Adaptation for Object Detection by Interactive Perception
Aug 03, 2021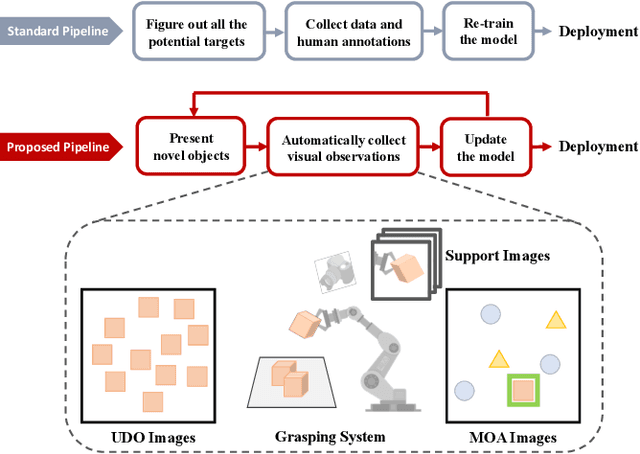
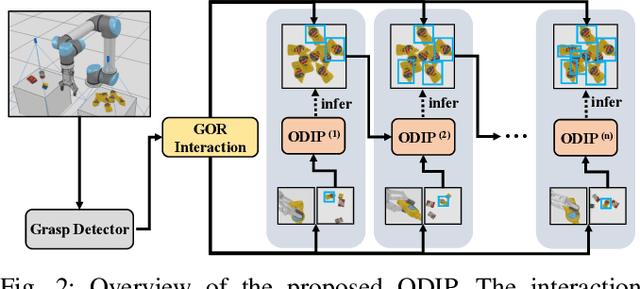
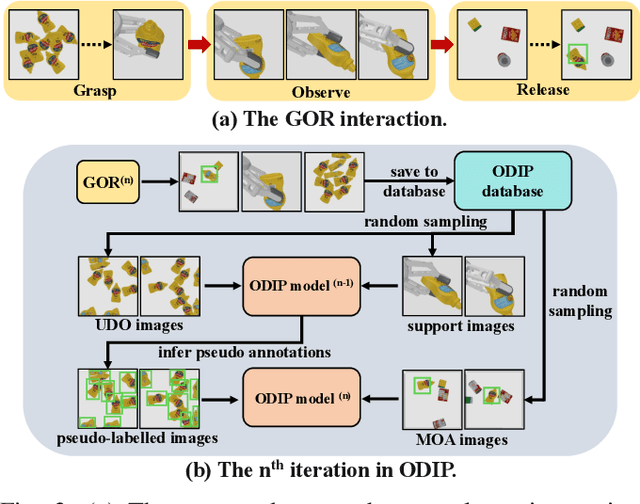
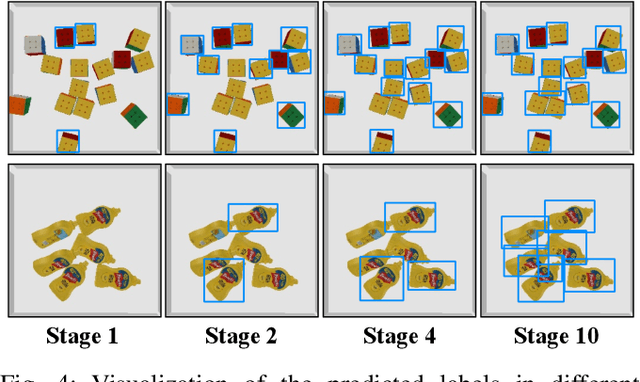
Object detection plays a deep role in visual systems by identifying instances for downstream algorithms. In industrial scenarios, however, a slight change in manufacturing systems would lead to costly data re-collection and human annotation processes to re-train models. Existing solutions such as semi-supervised and few-shot methods either rely on numerous human annotations or suffer low performance. In this work, we explore a novel object detector based on interactive perception (ODIP), which can be adapted to novel domains in an automated manner. By interacting with a grasping system, ODIP accumulates visual observations of novel objects, learning to identify previously unseen instances without human-annotated data. Extensive experiments show ODIP outperforms both the generic object detector and state-of-the-art few-shot object detector fine-tuned in traditional manners. A demo video is provided to further illustrate the idea.
OCID-Ref: A 3D Robotic Dataset with Embodied Language for Clutter Scene Grounding
Mar 13, 2021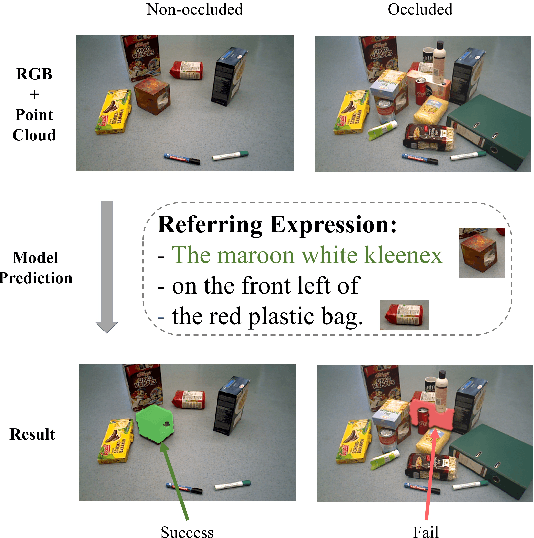

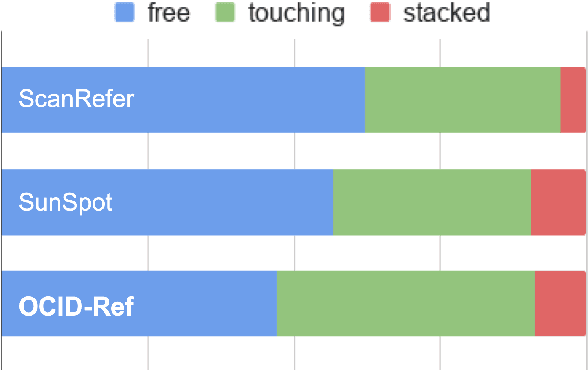

To effectively apply robots in working environments and assist humans, it is essential to develop and evaluate how visual grounding (VG) can affect machine performance on occluded objects. However, current VG works are limited in working environments, such as offices and warehouses, where objects are usually occluded due to space utilization issues. In our work, we propose a novel OCID-Ref dataset featuring a referring expression segmentation task with referring expressions of occluded objects. OCID-Ref consists of 305,694 referring expressions from 2,300 scenes with providing RGB image and point cloud inputs. To resolve challenging occlusion issues, we argue that it's crucial to take advantage of both 2D and 3D signals to resolve challenging occlusion issues. Our experimental results demonstrate the effectiveness of aggregating 2D and 3D signals but referring to occluded objects still remains challenging for the modern visual grounding systems. OCID-Ref is publicly available at https://github.com/lluma/OCID-Ref
GDN: A Coarse-To-Fine Representation for End-To-End 6-DoF Grasp Detection
Nov 11, 2020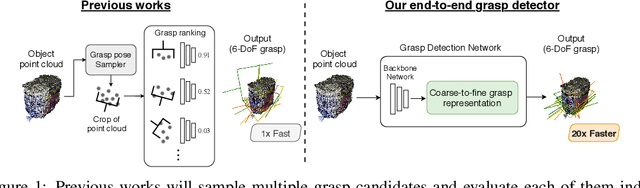
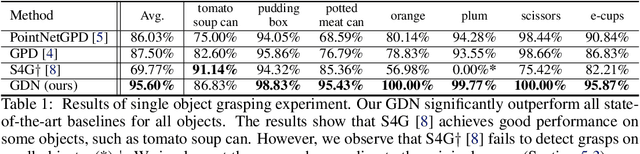
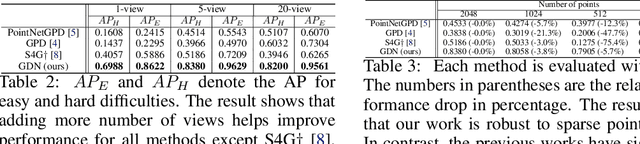
We proposed an end-to-end grasp detection network, Grasp Detection Network (GDN), cooperated with a novel coarse-to-fine (C2F) grasp representation design to detect diverse and accurate 6-DoF grasps based on point clouds. Compared to previous two-stage approaches which sample and evaluate multiple grasp candidates, our architecture is at least 20 times faster. It is also 8% and 40% more accurate in terms of the success rate in single object scenes and the complete rate in clutter scenes, respectively. Our method shows superior results among settings with different number of views and input points. Moreover, we propose a new AP-based metric which considers both rotation and transition errors, making it a more comprehensive evaluation tool for grasp detection models.