 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Point Cloud Registration with SE-Equivariant Representations
Oct 05, 2022
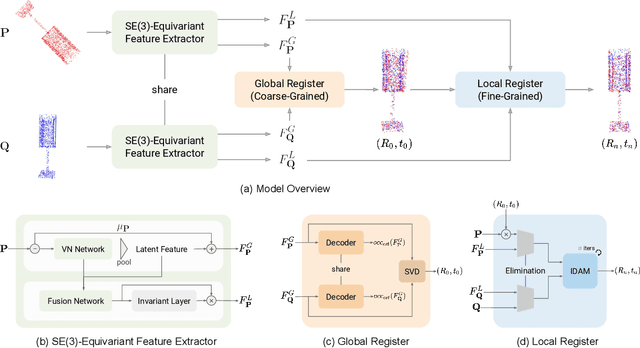
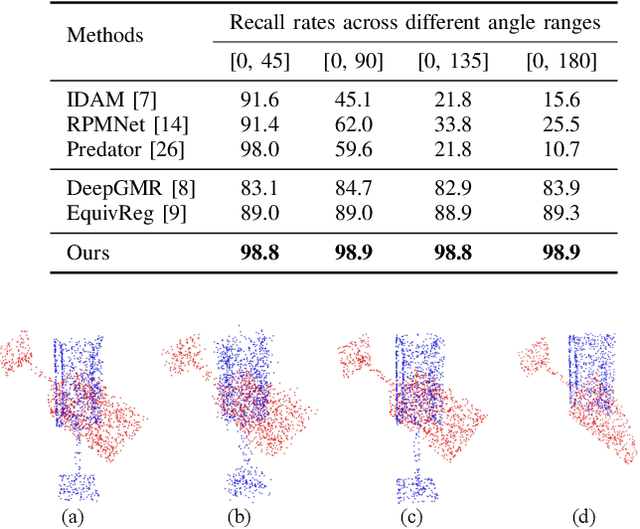
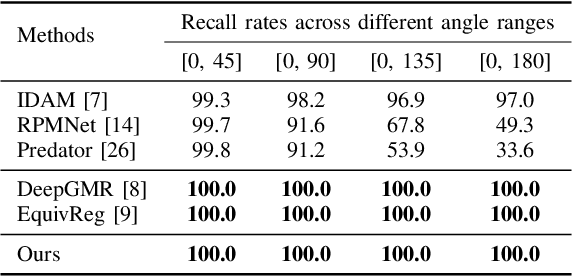
Point cloud registration is a crucial problem in computer vision and robotics. Existing methods either rely on matching local geometric features, which are sensitive to the pose differences, or leverage global shapes and thereby lead to inconsistency when facing distribution variances such as partial overlapping. Combining the advantages of both types of methods, we adopt a coarse-to-fine pipeline that concurrently handles both issues. We first reduce the pose differences between input point clouds by aligning global features; then we match the local features to further refine the inaccurate alignments resulting from distribution variances. As global feature alignment requires the features to preserve the poses of input point clouds and local feature matching expects the features to be invariant to these poses, we propose an SE(3)-equivariant feature extractor to simultaneously generate two types of features. In this feature extractor, representations preserving the poses are first encoded by our novel SE(3)-equivariant network and then converted into pose-invariant ones by a pose-detaching module. Experiments demonstrate that our proposed method increases the recall rate by 20% compared to state-of-the-art methods when facing both pose differences and distribution variances.
CFVS: Coarse-to-Fine Visual Servoing for 6-DoF Object-Agnostic Peg-In-Hole Assembly
Sep 19, 2022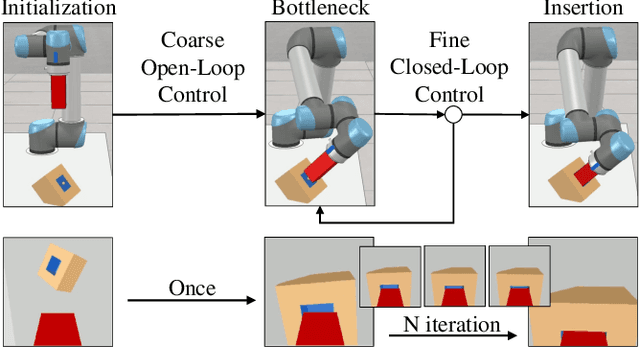
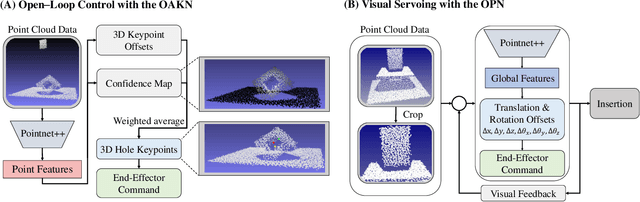

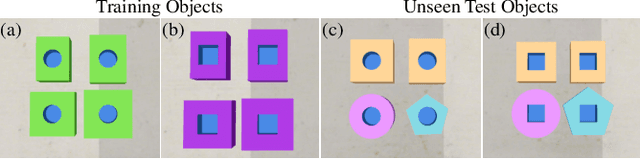
Robotic peg-in-hole assembly remains a challenging task due to its high accuracy demand. Previous work tends to simplify the problem by restricting the degree of freedom of the end-effector, or limiting the distance between the target and the initial pose position, which prevents them from being deployed in real-world manufacturing. Thus, we present a Coarse-to-Fine Visual Servoing (CFVS) peg-in-hole method, achieving 6-DoF end-effector motion control based on 3D visual feedback. CFVS can handle arbitrary tilt angles and large initial alignment errors through a fast pose estimation before refinement. Furthermore, by introducing a confidence map to ignore the irrelevant contour of objects, CFVS is robust against noise and can deal with various targets beyond training data. Extensive experiments show CFVS outperforms state-of-the-art methods and obtains 100%, 91%, and 82% average success rates in 3-DoF, 4-DoF, and 6-DoF peg-in-hole, respectively.
ADeADA: Adaptive Density-aware Active Domain Adaptation for Semantic Segmentation
Feb 15, 2022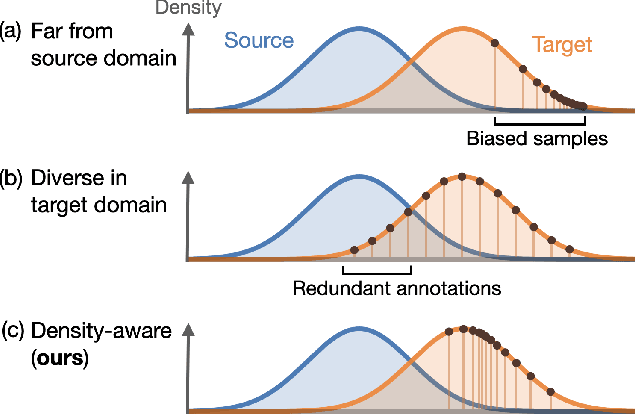
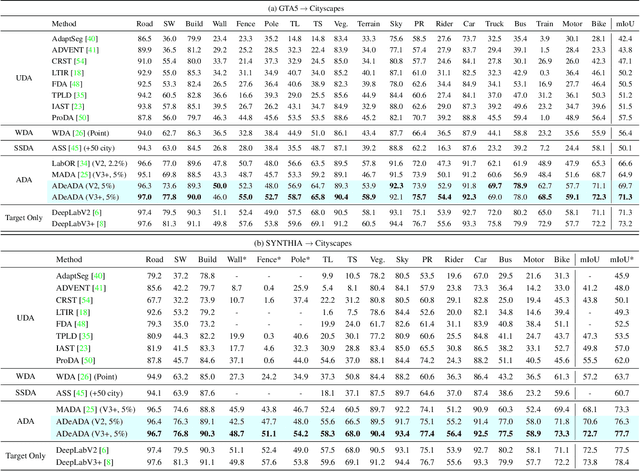
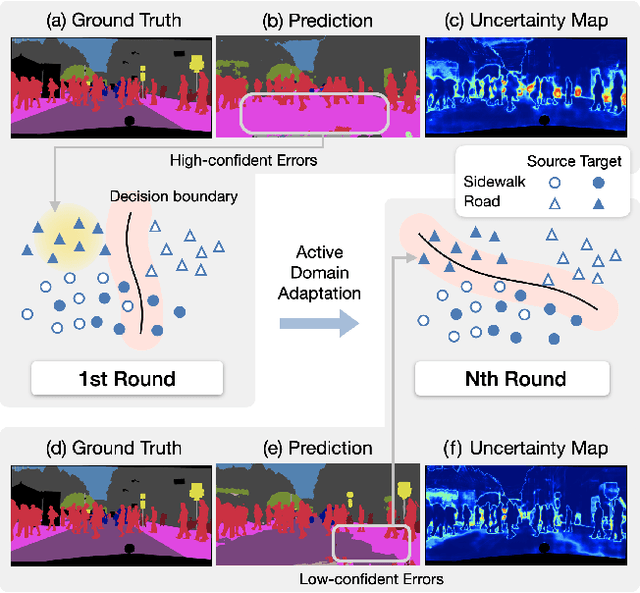
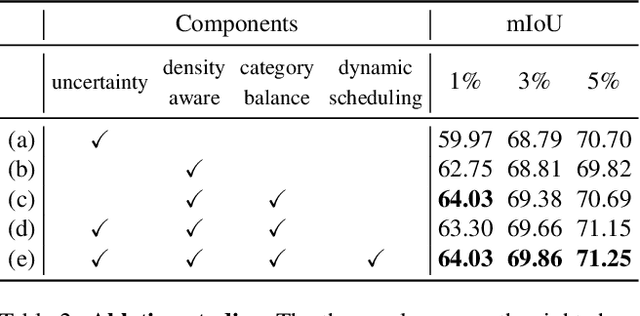
In the field of domain adaptation, a trade-off exists between the model performance and the number of target domain annotations. Active learning, maximizing model performance with few informative labeled data, comes in handy for such a scenario. In this work, we present ADeADA, a general active domain adaptation framework for semantic segmentation. To adapt the model to the target domain with minimum queried labels, we propose acquiring labels of the samples with high probability density in the target domain yet with low probability density in the source domain, complementary to the existing source domain labeled data. To further facilitate the label efficiency, we design an adaptive budget allocation policy, which dynamically balances the labeling budgets among different categories as well as between density-aware and uncertainty-based methods. Extensive experiments show that our method outperforms existing active learning and domain adaptation baselines on two benchmarks, GTA5 -> Cityscapes and SYNTHIA -> Cityscapes. With less than 5% target domain annotations, our method reaches comparable results with that of full supervision.
Anomaly-Aware Semantic Segmentation by Leveraging Synthetic-Unknown Data
Nov 29, 2021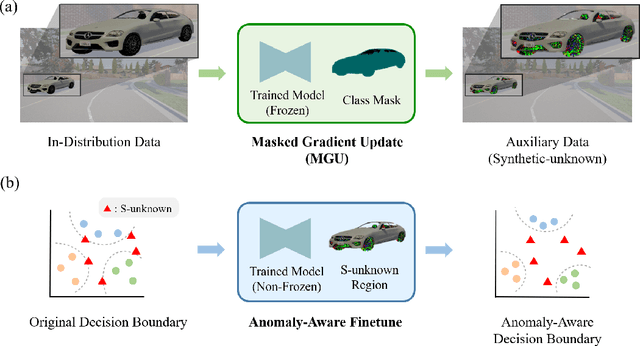
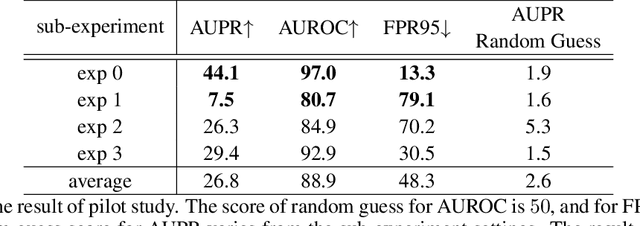
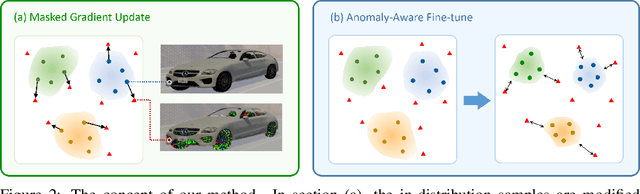
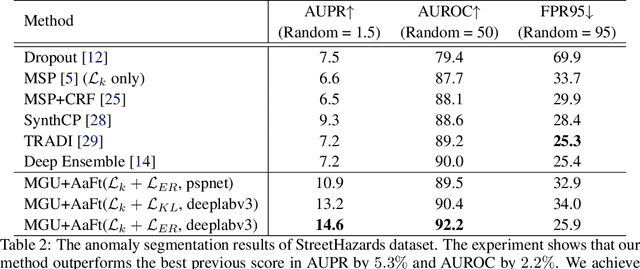
Anomaly awareness is an essential capability for safety-critical applications such as autonomous driving. While recent progress of robotics and computer vision has enabled anomaly detection for image classification, anomaly detection on semantic segmentation is less explored. Conventional anomaly-aware systems assuming other existing classes as out-of-distribution (pseudo-unknown) classes for training a model will result in two drawbacks. (1) Unknown classes, which applications need to cope with, might not actually exist during training time. (2) Model performance would strongly rely on the class selection. Observing this, we propose a novel Synthetic-Unknown Data Generation, intending to tackle the anomaly-aware semantic segmentation task. We design a new Masked Gradient Update (MGU) module to generate auxiliary data along the boundary of in-distribution data points. In addition, we modify the traditional cross-entropy loss to emphasize the border data points. We reach the state-of-the-art performance on two anomaly segmentation datasets. Ablation studies also demonstrate the effectiveness of proposed modules.
ODIP: Towards Automatic Adaptation for Object Detection by Interactive Perception
Aug 03, 2021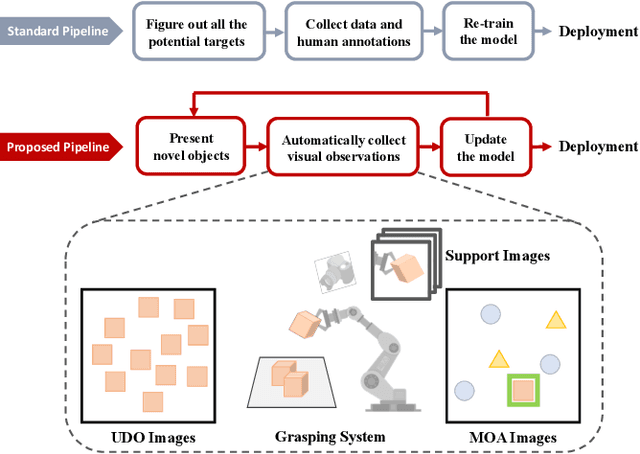
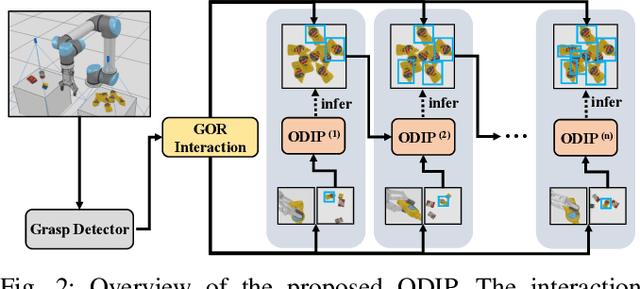
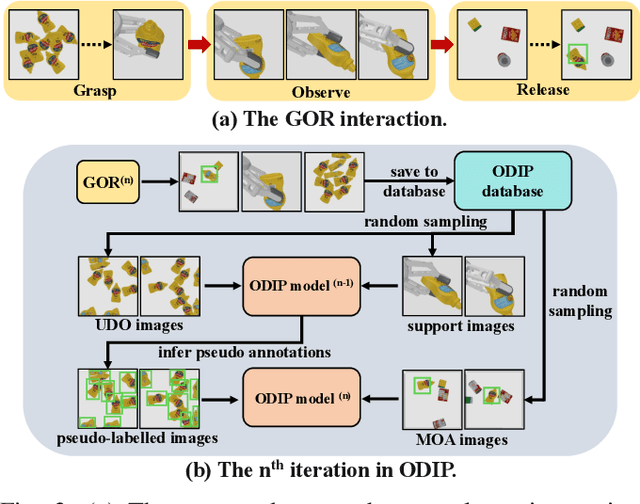
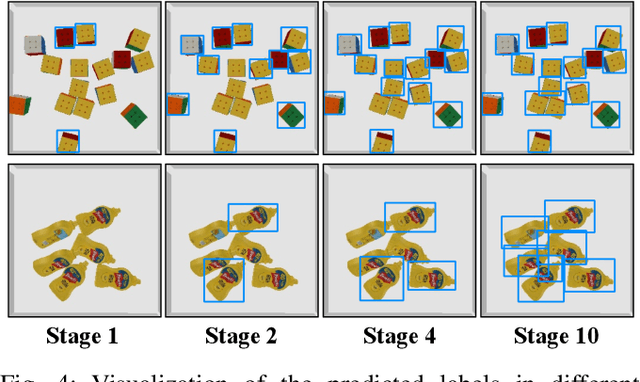
Object detection plays a deep role in visual systems by identifying instances for downstream algorithms. In industrial scenarios, however, a slight change in manufacturing systems would lead to costly data re-collection and human annotation processes to re-train models. Existing solutions such as semi-supervised and few-shot methods either rely on numerous human annotations or suffer low performance. In this work, we explore a novel object detector based on interactive perception (ODIP), which can be adapted to novel domains in an automated manner. By interacting with a grasping system, ODIP accumulates visual observations of novel objects, learning to identify previously unseen instances without human-annotated data. Extensive experiments show ODIP outperforms both the generic object detector and state-of-the-art few-shot object detector fine-tuned in traditional manners. A demo video is provided to further illustrate the idea.
Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection
Feb 24, 2021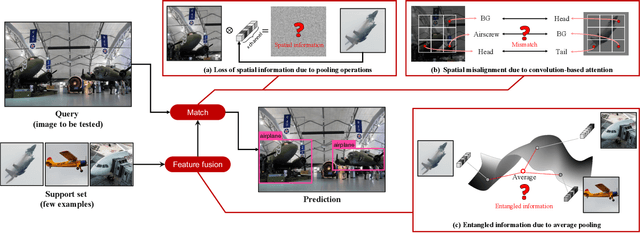

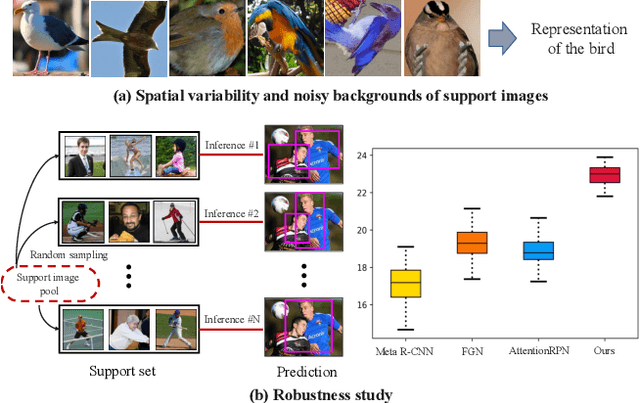
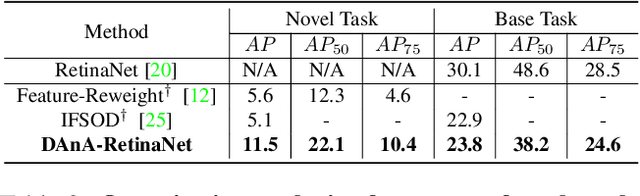
While recent progress has significantly boosted few-shot classification (FSC) performance, few-shot object detection (FSOD) remains challenging for modern learning systems. Existing FSOD systems follow FSC approaches, neglect the problem of spatial misalignment and the risk of information entanglement, and result in low performance. Observing this, we propose a novel Dual-Awareness-Attention (DAnA), which captures the pairwise spatial relationship cross the support and query images. The generated query-position-aware support features are robust to spatial misalignment and used to guide the detection network precisely. Our DAnA component is adaptable to various existing object detection networks and boosts FSOD performance by paying attention to specific semantics conditioned on the query. Experimental results demonstrate that DAnA significantly boosts (48% and 125% relatively) object detection performance on the COCO benchmark. By equipping DAnA, conventional object detection models, Faster-RCNN and RetinaNet, which are not designed explicitly for few-shot learning, reach state-of-the-art performance.