 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN
Paper and Code
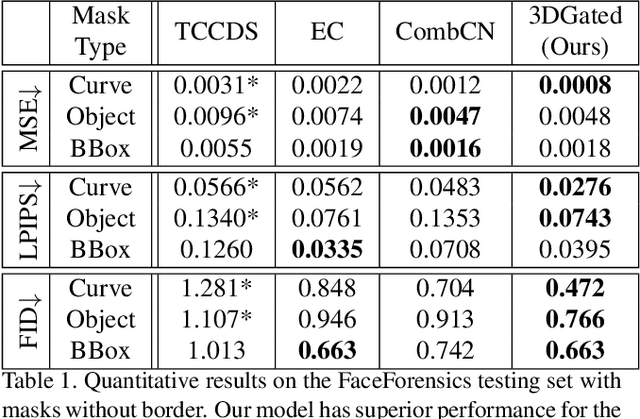
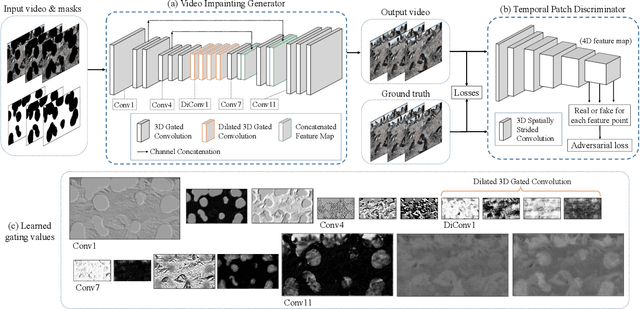
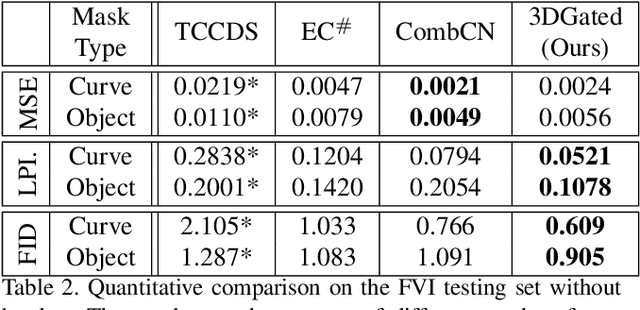
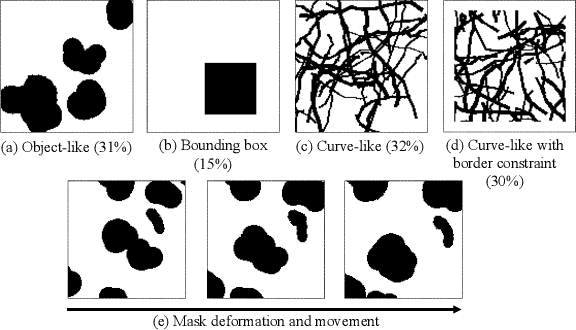
Free-form video inpainting is a very challenging task that could be widely used for video editing such as text removal. Existing patch-based methods could not handle non-repetitive structures such as faces, while directly applying image-based inpainting models to videos will result in temporal inconsistency (see http://bit.ly/2Fu1n6b). In this paper, we introduce a deep learn-ing based free-form video inpainting model, with proposed 3D gated convolutions to tackle the uncertainty of free-form masks and a novel Temporal PatchGAN loss to enhance temporal consistency. In addition, we collect videos and design a free-form mask generation algorithm to build the free-form video inpainting (FVI) dataset for training and evaluation of video inpainting models. We demonstrate the benefits of these components and experiments on both the FaceForensics and our FVI dataset suggest that our method is superior to existing ones.