 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchNet: A Simple Face Anti-Spoofing Framework via Fine-Grained Patch Recognition
Mar 27, 2022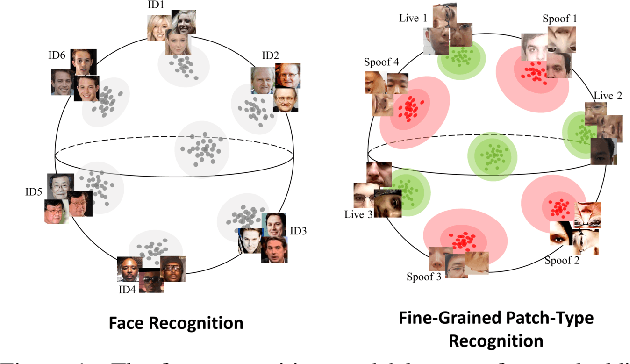
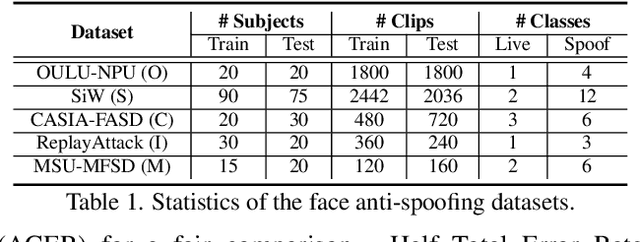
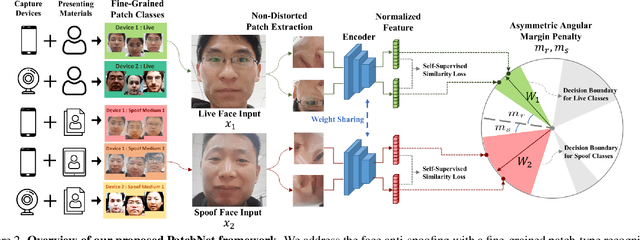
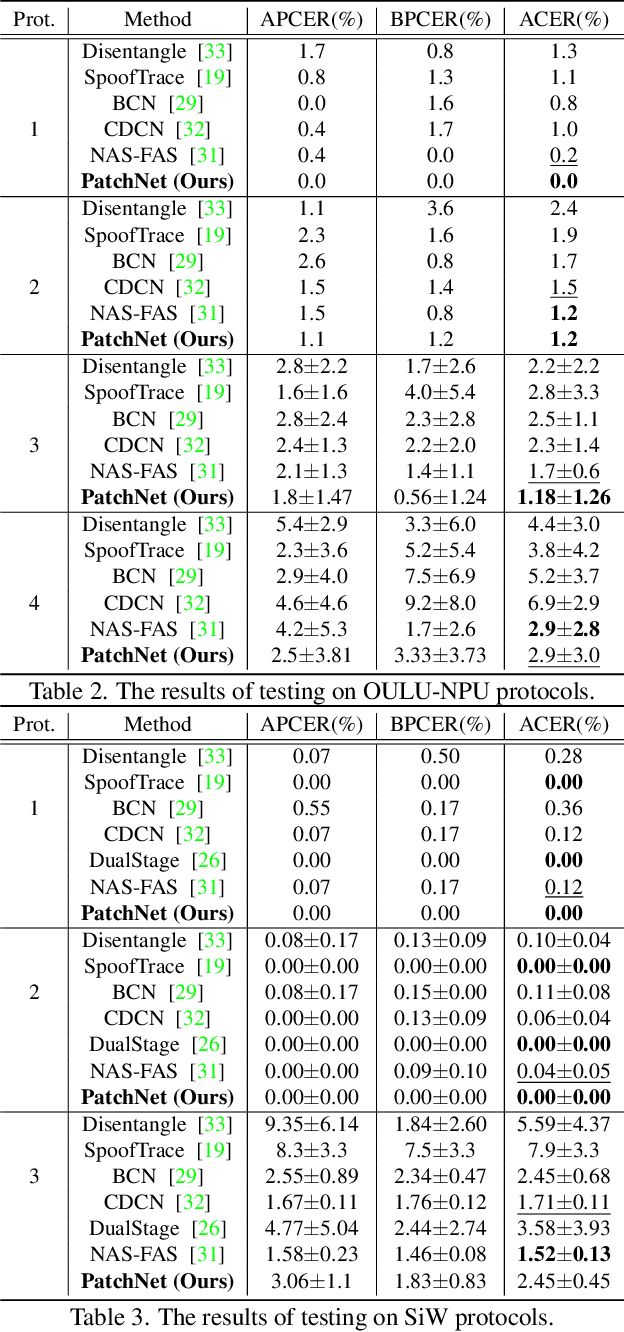
Face anti-spoofing (FAS) plays a critical role in securing face recognition systems from different presentation attacks. Previous works leverage auxiliary pixel-level supervision and domain generalization approaches to address unseen spoof types. However, the local characteristics of image captures, i.e., capturing devices and presenting materials, are ignored in existing works and we argue that such information is required for networks to discriminate between live and spoof images. In this work, we propose PatchNet which reformulates face anti-spoofing as a fine-grained patch-type recognition problem. To be specific, our framework recognizes the combination of capturing devices and presenting materials based on the patches cropped from non-distorted face images. This reformulation can largely improve the data variation and enforce the network to learn discriminative feature from local capture patterns. In addition, to further improve the generalization ability of the spoof feature, we propose the novel Asymmetric Margin-based Classification Loss and Self-supervised Similarity Loss to regularize the patch embedding space. Our experimental results verify our assumption and show that the model is capable of recognizing unseen spoof types robustly by only looking at local regions. Moreover, the fine-grained and patch-level reformulation of FAS outperforms the existing approaches on intra-dataset, cross-dataset, and domain generalization benchmarks. Furthermore, our PatchNet framework can enable practical applications like Few-Shot Reference-based FAS and facilitate future exploration of spoof-related intrinsic cues.
Unified Representation Learning for Cross Model Compatibility
Aug 11, 2020

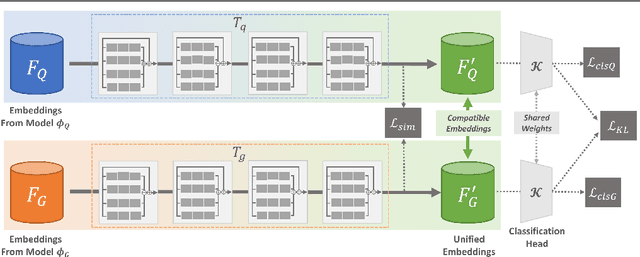

We propose a unified representation learning framework to address the Cross Model Compatibility (CMC) problem in the context of visual search applications. Cross compatibility between different embedding models enables the visual search systems to correctly recognize and retrieve identities without re-encoding user images, which are usually not available due to privacy concerns. While there are existing approaches to address CMC in face identification, they fail to work in a more challenging setting where the distributions of embedding models shift drastically. The proposed solution improves CMC performance by introducing a light-weight Residual Bottleneck Transformation (RBT) module and a new training scheme to optimize the embedding spaces. Extensive experiments demonstrate that our proposed solution outperforms previous approaches by a large margin for various challenging visual search scenarios of face recognition and person re-identification.
DuLa-Net: A Dual-Projection Network for Estimating Room Layouts from a Single RGB Panorama
Nov 29, 2018

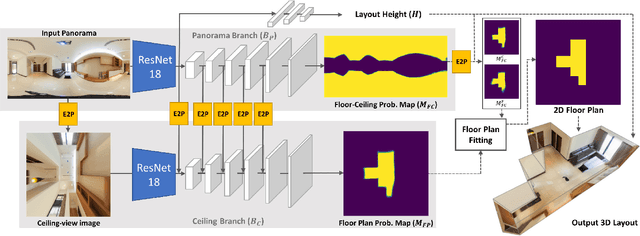

We present a deep learning framework, called DuLa-Net, to predict Manhattan-world 3D room layouts from a single RGB panorama. To achieve better prediction accuracy, our method leverages two projections of the panorama at once, namely the equirectangular panorama-view and the perspective ceiling-view, that each contains different clues about the room layouts. Our network architecture consists of two encoder-decoder branches for analyzing each of the two views. In addition, a novel feature fusion structure is proposed to connect the two branches, which are then jointly trained to predict the 2D floor plans and layout heights. To learn more complex room layouts, we introduce the Realtor360 dataset that contains panoramas of Manhattan-world room layouts with different numbers of corners. Experimental results show that our work outperforms recent state-of-the-art in prediction accuracy and performance, especially in the rooms with non-cuboid layouts.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018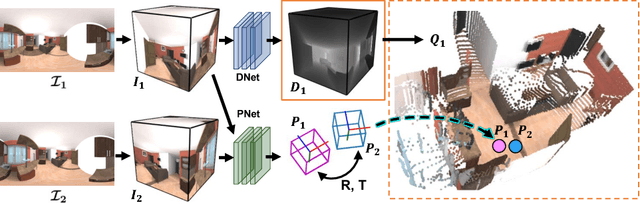
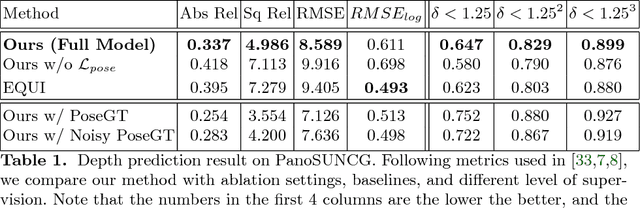
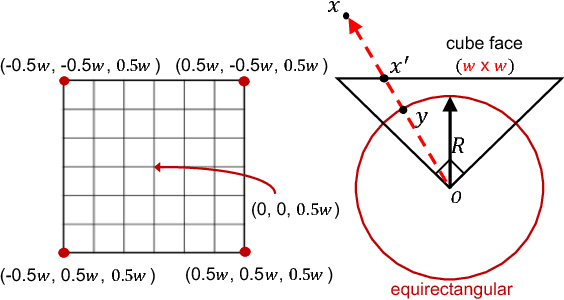
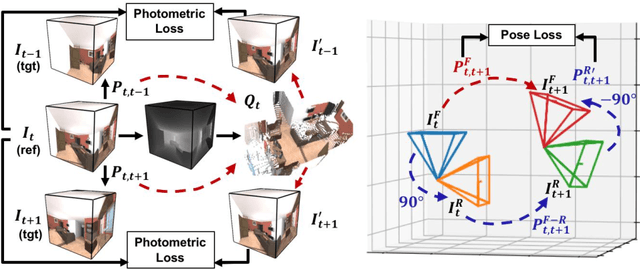
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.