 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDR Reconstruction Boosting with Training-Free and Exposure-Consistent Diffusion
Feb 23, 2026Single LDR to HDR reconstruction remains challenging for over-exposed regions where traditional methods often fail due to complete information loss. We present a training-free approach that enhances existing indirect and direct HDR reconstruction methods through diffusion-based inpainting. Our method combines text-guided diffusion models with SDEdit refinement to generate plausible content in over-exposed areas while maintaining consistency across multi-exposure LDR images. Unlike previous approaches requiring extensive training, our method seamlessly integrates with existing HDR reconstruction techniques through an iterative compensation mechanism that ensures luminance coherence across multiple exposures. We demonstrate significant improvements in both perceptual quality and quantitative metrics on standard HDR datasets and in-the-wild captures. Results show that our method effectively recovers natural details in challenging scenarios while preserving the advantages of existing HDR reconstruction pipelines. Project page: https://github.com/EusdenLin/HDR-Reconstruction-Boosting
ORFormer: Occlusion-Robust Transformer for Accurate Facial Landmark Detection
Dec 17, 2024



Although facial landmark detection (FLD) has gained significant progress, existing FLD methods still suffer from performance drops on partially non-visible faces, such as faces with occlusions or under extreme lighting conditions or poses. To address this issue, we introduce ORFormer, a novel transformer-based method that can detect non-visible regions and recover their missing features from visible parts. Specifically, ORFormer associates each image patch token with one additional learnable token called the messenger token. The messenger token aggregates features from all but its patch. This way, the consensus between a patch and other patches can be assessed by referring to the similarity between its regular and messenger embeddings, enabling non-visible region identification. Our method then recovers occluded patches with features aggregated by the messenger tokens. Leveraging the recovered features, ORFormer compiles high-quality heatmaps for the downstream FLD task. Extensive experiments show that our method generates heatmaps resilient to partial occlusions. By integrating the resultant heatmaps into existing FLD methods, our method performs favorably against the state of the arts on challenging datasets such as WFLW and COFW.
Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
Apr 05, 2024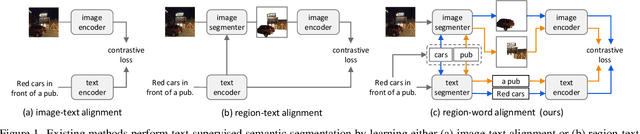
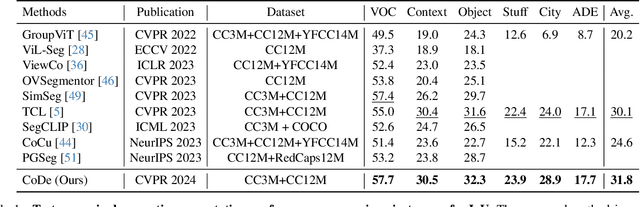
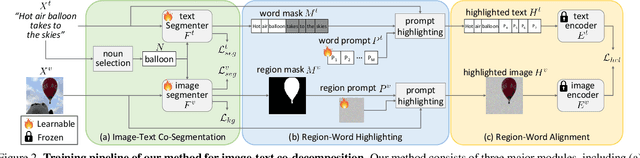
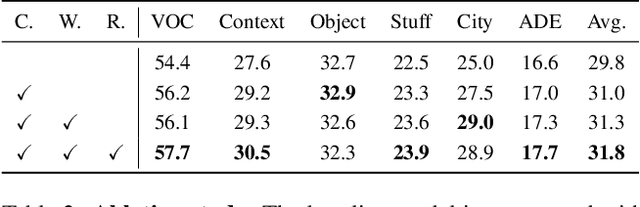
This paper addresses text-supervised semantic segmentation, aiming to learn a model capable of segmenting arbitrary visual concepts within images by using only image-text pairs without dense annotations. Existing methods have demonstrated that contrastive learning on image-text pairs effectively aligns visual segments with the meanings of texts. We notice that there is a discrepancy between text alignment and semantic segmentation: A text often consists of multiple semantic concepts, whereas semantic segmentation strives to create semantically homogeneous segments. To address this issue, we propose a novel framework, Image-Text Co-Decomposition (CoDe), where the paired image and text are jointly decomposed into a set of image regions and a set of word segments, respectively, and contrastive learning is developed to enforce region-word alignment. To work with a vision-language model, we present a prompt learning mechanism that derives an extra representation to highlight an image segment or a word segment of interest, with which more effective features can be extracted from that segment. Comprehensive experimental results demonstrate that our method performs favorably against existing text-supervised semantic segmentation methods on six benchmark datasets.
Learning Continuous Exposure Value Representations for Single-Image HDR Reconstruction
Sep 07, 2023Deep learning is commonly used to reconstruct HDR images from LDR images. LDR stack-based methods are used for single-image HDR reconstruction, generating an HDR image from a deep learning-generated LDR stack. However, current methods generate the stack with predetermined exposure values (EVs), which may limit the quality of HDR reconstruction. To address this, we propose the continuous exposure value representation (CEVR), which uses an implicit function to generate LDR images with arbitrary EVs, including those unseen during training. Our approach generates a continuous stack with more images containing diverse EVs, significantly improving HDR reconstruction. We use a cycle training strategy to supervise the model in generating continuous EV LDR images without corresponding ground truths. Our CEVR model outperforms existing methods, as demonstrated by experimental results.
Monocular Quasi-Dense 3D Object Tracking
Mar 12, 2021
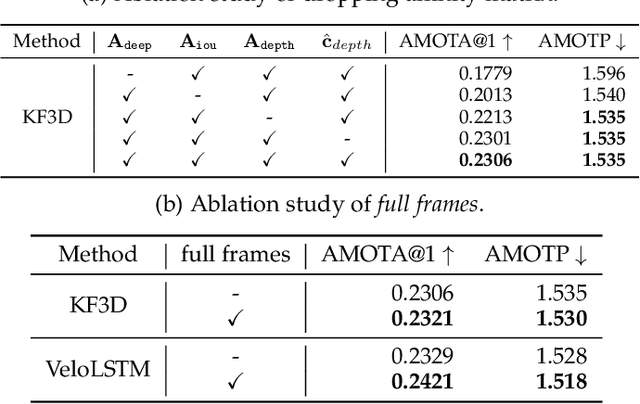
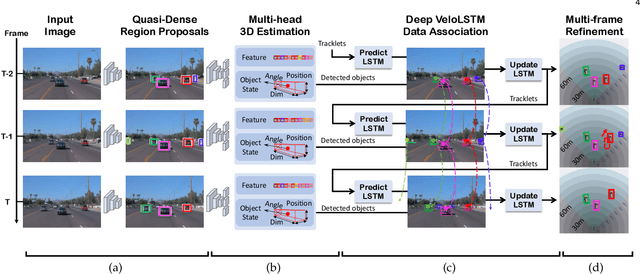
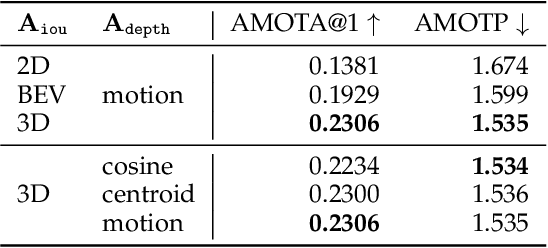
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.
3D LiDAR and Stereo Fusion using Stereo Matching Network with Conditional Cost Volume Normalization
Apr 05, 2019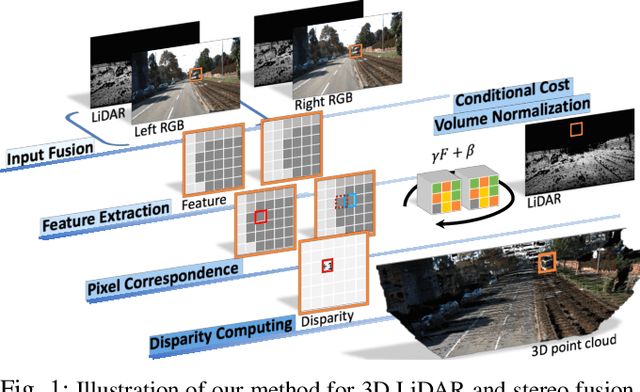
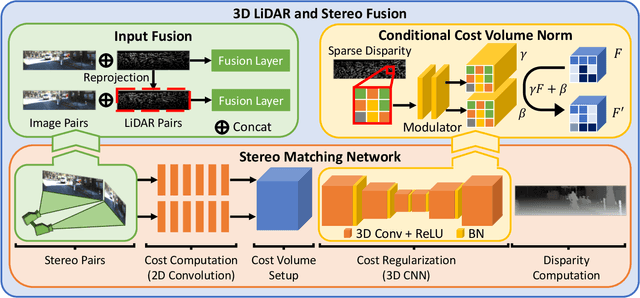
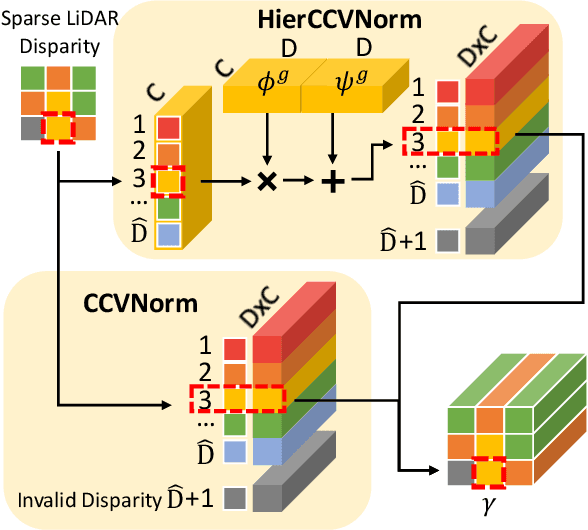
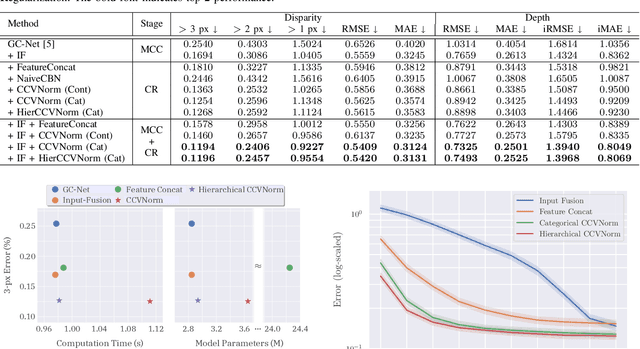
The complementary characteristics of active and passive depth sensing techniques motivate the fusion of the Li-DAR sensor and stereo camera for improved depth perception. Instead of directly fusing estimated depths across LiDAR and stereo modalities, we take advantages of the stereo matching network with two enhanced techniques: Input Fusion and Conditional Cost Volume Normalization (CCVNorm) on the LiDAR information. The proposed framework is generic and closely integrated with the cost volume component that is commonly utilized in stereo matching neural networks. We experimentally verify the efficacy and robustness of our method on the KITTI Stereo and Depth Completion datasets, obtaining favorable performance against various fusion strategies. Moreover, we demonstrate that, with a hierarchical extension of CCVNorm, the proposed method brings only slight overhead to the stereo matching network in terms of computation time and model size. For project page, see https://zswang666.github.io/Stereo-LiDAR-CCVNorm-Project-Page/
Joint Monocular 3D Vehicle Detection and Tracking
Dec 02, 2018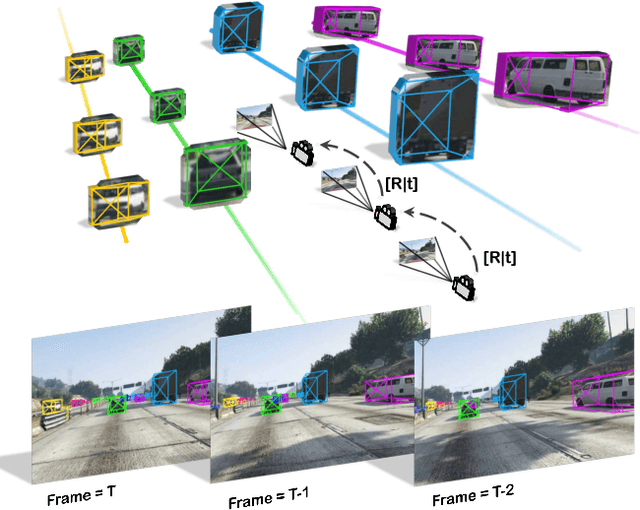
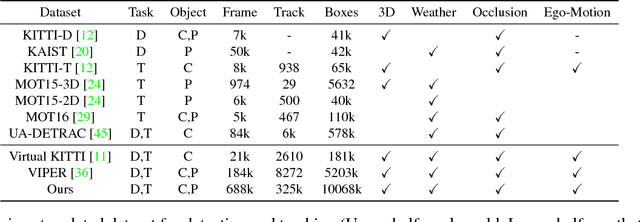
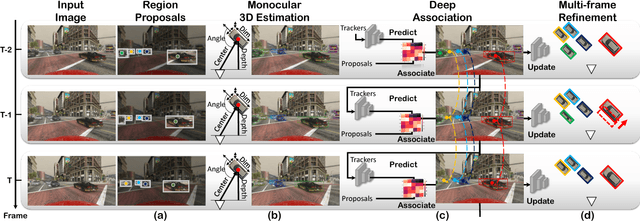
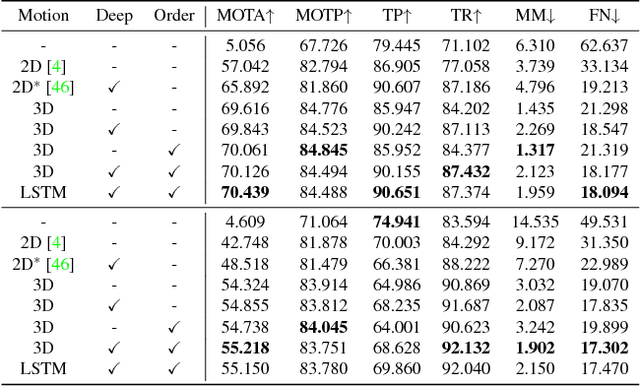
3D vehicle detection and tracking from a monocular camera requires detecting and associating vehicles, and estimating their locations and extents together. It is challenging because vehicles are in constant motion and it is practically impossible to recover the 3D positions from a single image. In this paper, we propose a novel framework that jointly detects and tracks 3D vehicle bounding boxes. Our approach leverages 3D pose estimation to learn 2D patch association overtime and uses temporal information from tracking to obtain stable 3D estimation. Our method also leverages 3D box depth ordering and motion to link together the tracks of occluded objects. We train our system on realistic 3D virtual environments, collecting a new diverse, large-scale and densely annotated dataset with accurate 3D trajectory annotations. Our experiments demonstrate that our method benefits from inferring 3D for both data association and tracking robustness, leveraging our dynamic 3D tracking dataset.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018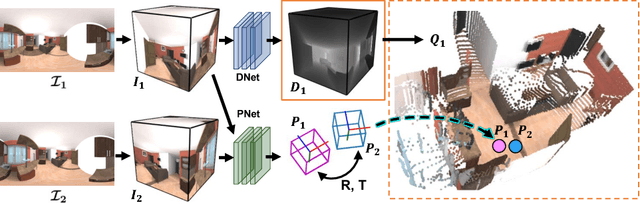
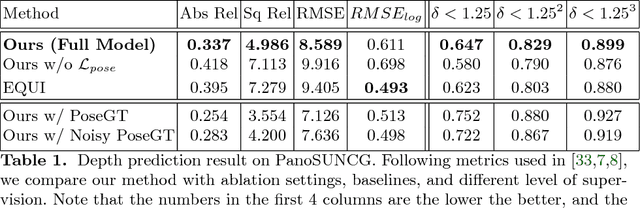
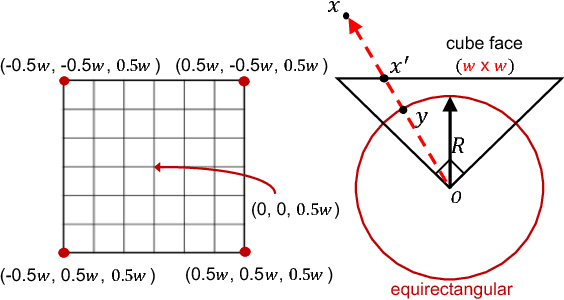
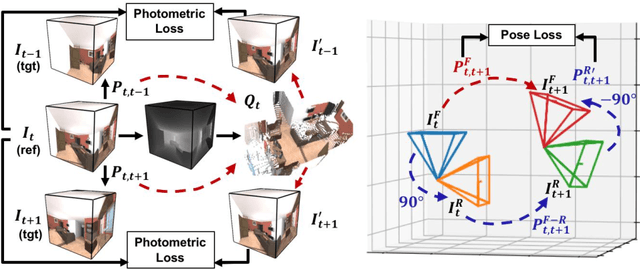
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Self-view Grounding Given a Narrated 360° Video
Nov 23, 2017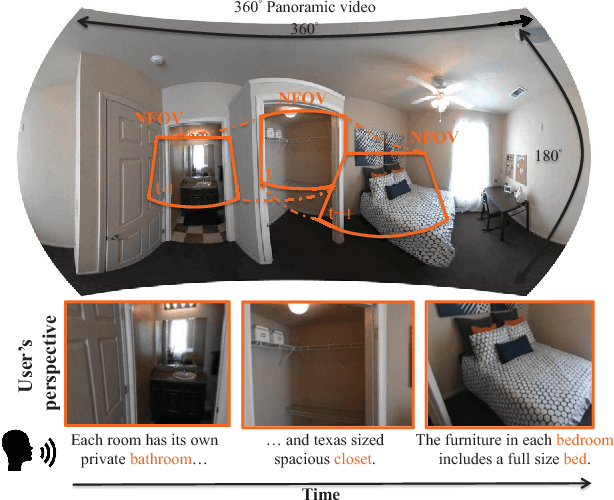
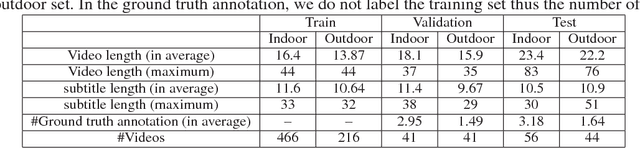
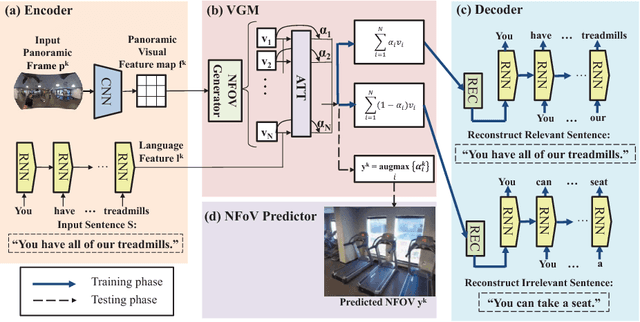
Narrated 360{\deg} videos are typically provided in many touring scenarios to mimic real-world experience. However, previous work has shown that smart assistance (i.e., providing visual guidance) can significantly help users to follow the Normal Field of View (NFoV) corresponding to the narrative. In this project, we aim at automatically grounding the NFoVs of a 360{\deg} video given subtitles of the narrative (referred to as "NFoV-grounding"). We propose a novel Visual Grounding Model (VGM) to implicitly and efficiently predict the NFoVs given the video content and subtitles. Specifically, at each frame, we efficiently encode the panorama into feature map of candidate NFoVs using a Convolutional Neural Network (CNN) and the subtitles to the same hidden space using an RNN with Gated Recurrent Units (GRU). Then, we apply soft-attention on candidate NFoVs to trigger sentence decoder aiming to minimize the reconstruct loss between the generated and given sentence. Finally, we obtain the NFoV as the candidate NFoV with the maximum attention without any human supervision. To train VGM more robustly, we also generate a reverse sentence conditioning on one minus the soft-attention such that the attention focuses on candidate NFoVs less relevant to the given sentence. The negative log reconstruction loss of the reverse sentence (referred to as "irrelevant loss") is jointly minimized to encourage the reverse sentence to be different from the given sentence. To evaluate our method, we collect the first narrated 360{\deg} videos dataset and achieve state-of-the-art NFoV-grounding performance.
Deep 360 Pilot: Learning a Deep Agent for Piloting through 360° Sports Video
May 04, 2017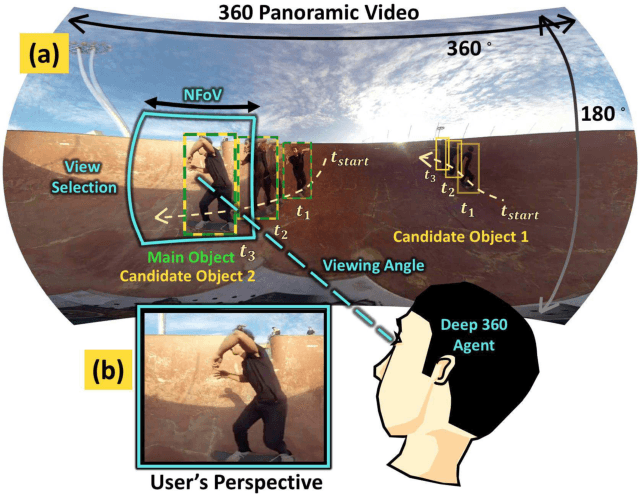

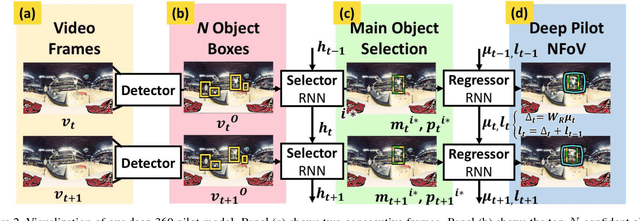
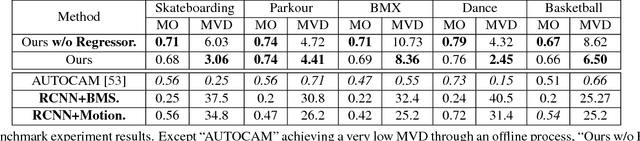
Watching a 360{\deg} sports video requires a viewer to continuously select a viewing angle, either through a sequence of mouse clicks or head movements. To relieve the viewer from this "360 piloting" task, we propose "deep 360 pilot" -- a deep learning-based agent for piloting through 360{\deg} sports videos automatically. At each frame, the agent observes a panoramic image and has the knowledge of previously selected viewing angles. The task of the agent is to shift the current viewing angle (i.e. action) to the next preferred one (i.e., goal). We propose to directly learn an online policy of the agent from data. We use the policy gradient technique to jointly train our pipeline: by minimizing (1) a regression loss measuring the distance between the selected and ground truth viewing angles, (2) a smoothness loss encouraging smooth transition in viewing angle, and (3) maximizing an expected reward of focusing on a foreground object. To evaluate our method, we build a new 360-Sports video dataset consisting of five sports domains. We train domain-specific agents and achieve the best performance on viewing angle selection accuracy and transition smoothness compared to [51] and other baselines.