 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Human Motion Prediction with Scene Context
Jul 07, 2020
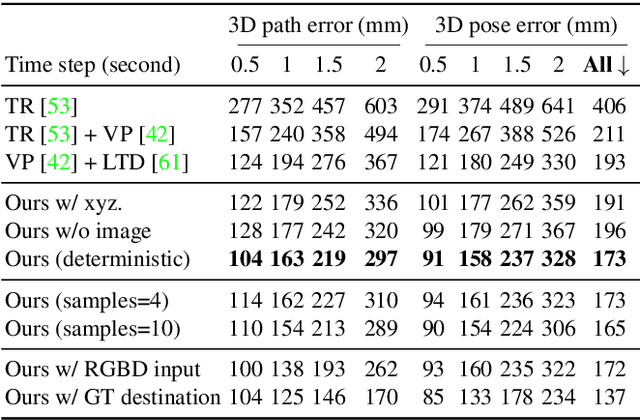
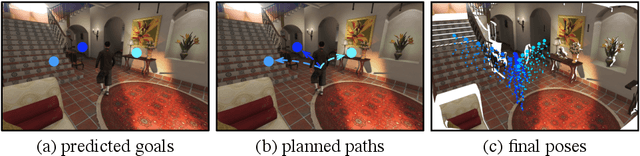
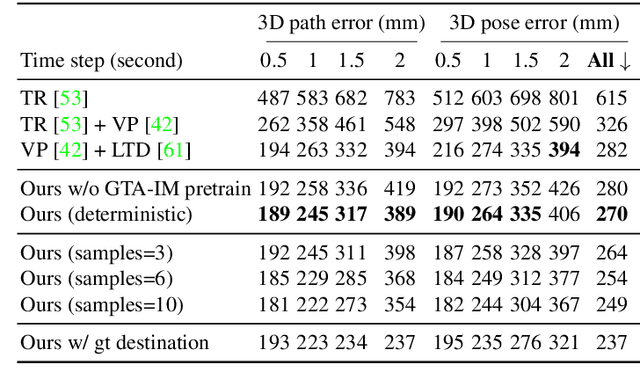
Human movement is goal-directed and influenced by the spatial layout of the objects in the scene. To plan future human motion, it is crucial to perceive the environment -- imagine how hard it is to navigate a new room with lights off. Existing works on predicting human motion do not pay attention to the scene context and thus struggle in long-term prediction. In this work, we propose a novel three-stage framework that exploits scene context to tackle this task. Given a single scene image and 2D pose histories, our method first samples multiple human motion goals, then plans 3D human paths towards each goal, and finally predicts 3D human pose sequences following each path. For stable training and rigorous evaluation, we contribute a diverse synthetic dataset with clean annotations. In both synthetic and real datasets, our method shows consistent quantitative and qualitative improvements over existing methods.
Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder
May 22, 2019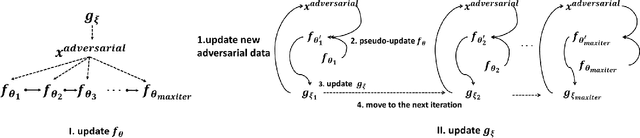


In this work, we consider one challenging training time attack by modifying training data with bounded perturbation, hoping to manipulate the behavior (both targeted or non-targeted) of any corresponding trained classifier during test time when facing clean samples. To achieve this, we proposed to use an auto-encoder-like network to generate the pertubation on the training data paired with one differentiable system acting as the imaginary victim classifier. The perturbation generator will learn to update its weights by watching the training procedure of the imaginary classifier in order to produce the most harmful and imperceivable noise which in turn will lead the lowest generalization power for the victim classifier. This can be formulated into a non-linear equality constrained optimization problem. Unlike GANs, solving such problem is computationally challenging, we then proposed a simple yet effective procedure to decouple the alternating updates for the two networks for stability. The method proposed in this paper can be easily extended to the label specific setting where the attacker can manipulate the predictions of the victim classifiers according to some predefined rules rather than only making wrong predictions. Experiments on various datasets including CIFAR-10 and a reduced version of ImageNet confirmed the effectiveness of the proposed method and empirical results showed that, such bounded perturbation have good transferability regardless of which classifier the victim is actually using on image data.
Monocular Plan View Networks for Autonomous Driving
May 16, 2019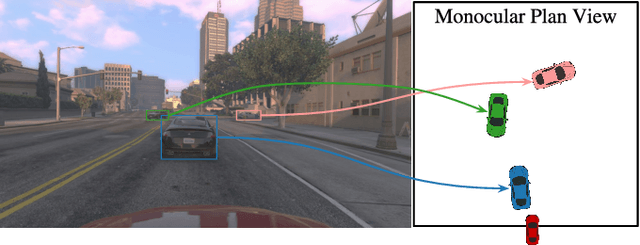

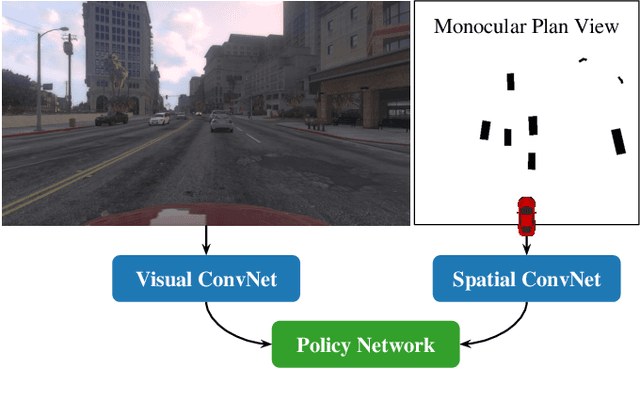
Convolutions on monocular dash cam videos capture spatial invariances in the image plane but do not explicitly reason about distances and depth. We propose a simple transformation of observations into a bird's eye view, also known as plan view, for end-to-end control. We detect vehicles and pedestrians in the first person view and project them into an overhead plan view. This representation provides an abstraction of the environment from which a deep network can easily deduce the positions and directions of entities. Additionally, the plan view enables us to leverage advances in 3D object detection in conjunction with deep policy learning. We evaluate our monocular plan view network on the photo-realistic Grand Theft Auto V simulator. A network using both a plan view and front view causes less than half as many collisions as previous detection-based methods and an order of magnitude fewer collisions than pure pixel-based policies.
Deep Object-Centric Policies for Autonomous Driving
Mar 01, 2019
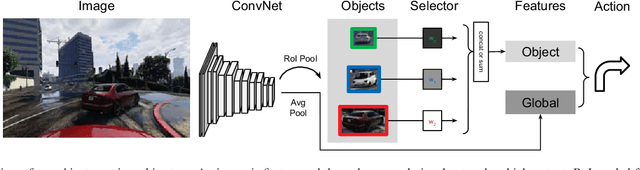

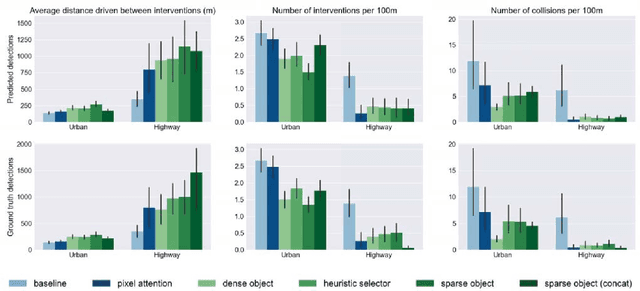
While learning visuomotor skills in an end-to-end manner is appealing, deep neural networks are often uninterpretable and fail in surprising ways. For robotics tasks, such as autonomous driving, models that explicitly represent objects may be more robust to new scenes and provide intuitive visualizations. We describe a taxonomy of "object-centric" models which leverage both object instances and end-to-end learning. In the Grand Theft Auto V simulator, we show that object-centric models outperform object-agnostic methods in scenes with other vehicles and pedestrians, even with an imperfect detector. We also demonstrate that our architectures perform well on real-world environments by evaluating on the Berkeley DeepDrive Video dataset, where an object-centric model outperforms object-agnostic models in the low-data regimes.
Disentangling Propagation and Generation for Video Prediction
Dec 02, 2018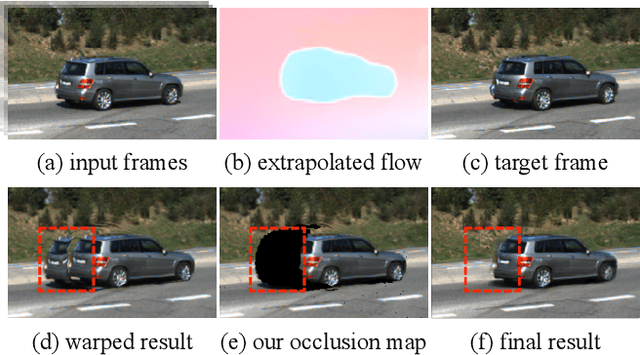
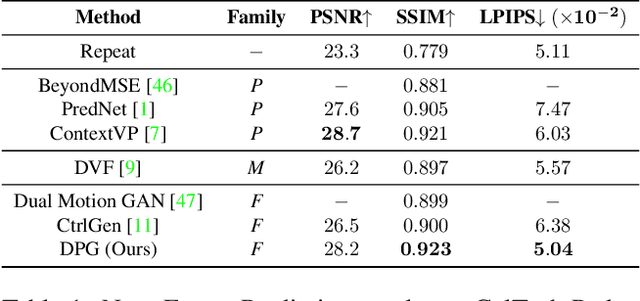
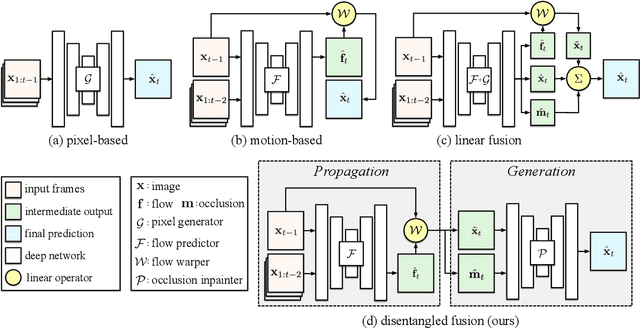
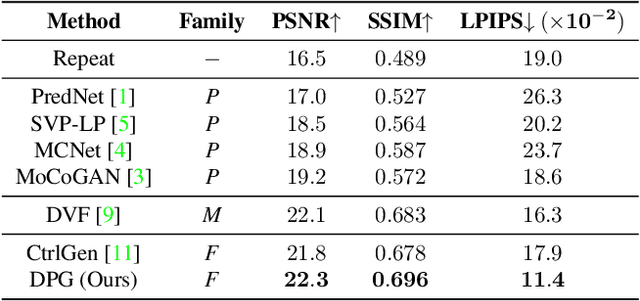
Learning to predict future video frames is a challenging task. Recent approaches for natural scenes directly predict pixels via inferring appearance flow and using flow-guided warping. Such models excel when motion estimates are accurate, but the motion may be ambiguous or erroneous in many real scenes. When scene motion exposes new regions of the scene, motion-based prediction yields poor results. However, learning to predict novel pixels directly can also require a prohibitive amount of training. In this work, we present a confidence-aware spatial-temporal context encoder for video prediction called Flow-Grounded Video Prediction (FGVP), in which motion propagation and novel pixel generation are first disentangled and then fused according to computed flow uncertainty map. For regions where motion-based prediction shows low-confidence, our model uses a conditional context encoder to hallucinate appropriate content. We test our methods on the standard CalTech Pedestrian dataset and the more challenging KITTI Flow dataset of larger motions and occlusions. Our methods produce both sharp and natural predictions compared to previous works, achieving the state-of-the-art performance on both datasets.
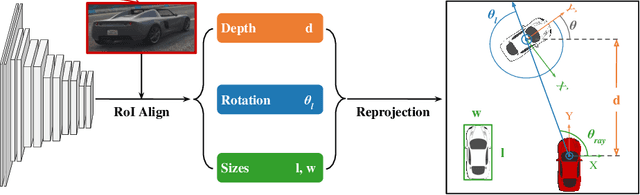
Joint Monocular 3D Vehicle Detection and Tracking
Dec 02, 2018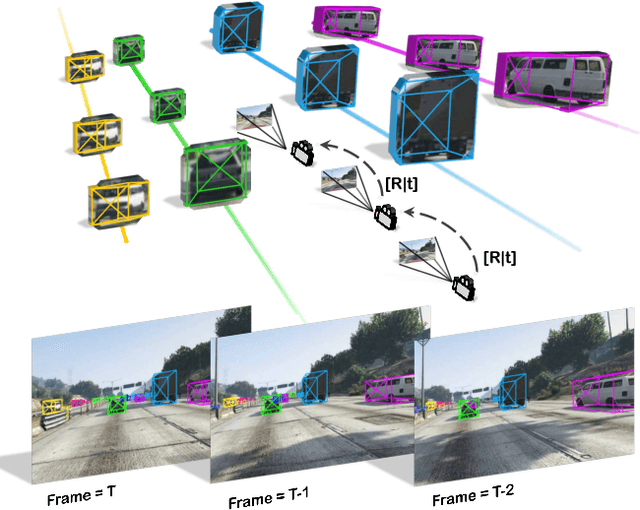
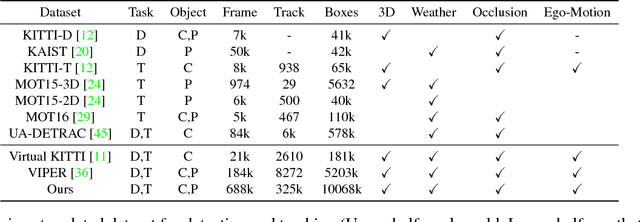
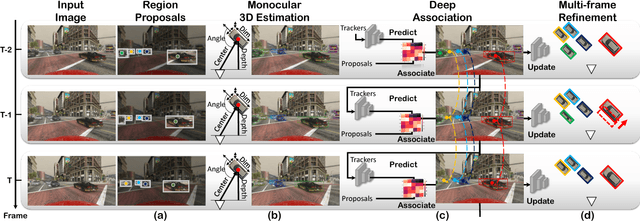
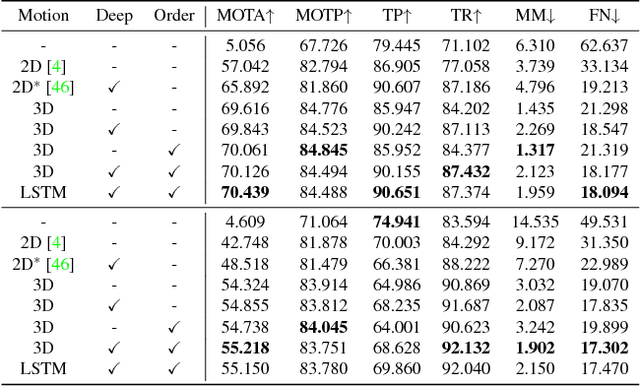
3D vehicle detection and tracking from a monocular camera requires detecting and associating vehicles, and estimating their locations and extents together. It is challenging because vehicles are in constant motion and it is practically impossible to recover the 3D positions from a single image. In this paper, we propose a novel framework that jointly detects and tracks 3D vehicle bounding boxes. Our approach leverages 3D pose estimation to learn 2D patch association overtime and uses temporal information from tracking to obtain stable 3D estimation. Our method also leverages 3D box depth ordering and motion to link together the tracks of occluded objects. We train our system on realistic 3D virtual environments, collecting a new diverse, large-scale and densely annotated dataset with accurate 3D trajectory annotations. Our experiments demonstrate that our method benefits from inferring 3D for both data association and tracking robustness, leveraging our dynamic 3D tracking dataset.
Curriculum Adversarial Training
May 13, 2018
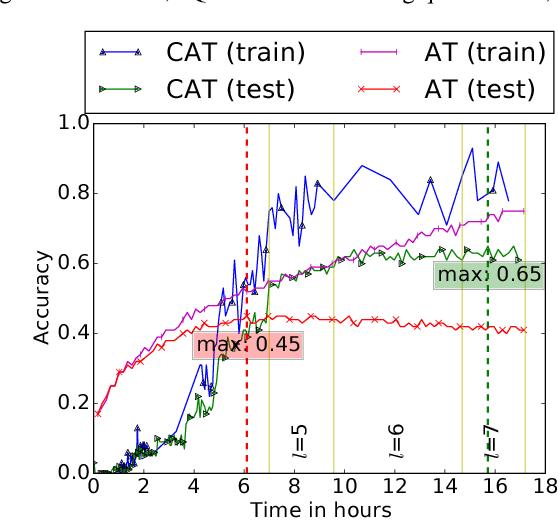
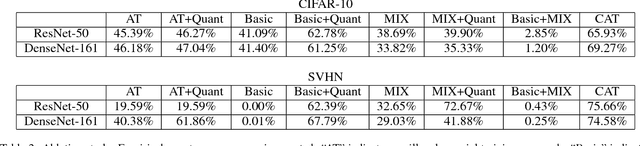
Recently, deep learning has been applied to many security-sensitive applications, such as facial authentication. The existence of adversarial examples hinders such applications. The state-of-the-art result on defense shows that adversarial training can be applied to train a robust model on MNIST against adversarial examples; but it fails to achieve a high empirical worst-case accuracy on a more complex task, such as CIFAR-10 and SVHN. In our work, we propose curriculum adversarial training (CAT) to resolve this issue. The basic idea is to develop a curriculum of adversarial examples generated by attacks with a wide range of strengths. With two techniques to mitigate the forgetting and the generalization issues, we demonstrate that CAT can improve the prior art's empirical worst-case accuracy by a large margin of 25% on CIFAR-10 and 35% on SVHN. At the same, the model's performance on non-adversarial inputs is comparable to the state-of-the-art models.