 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning
Apr 11, 2019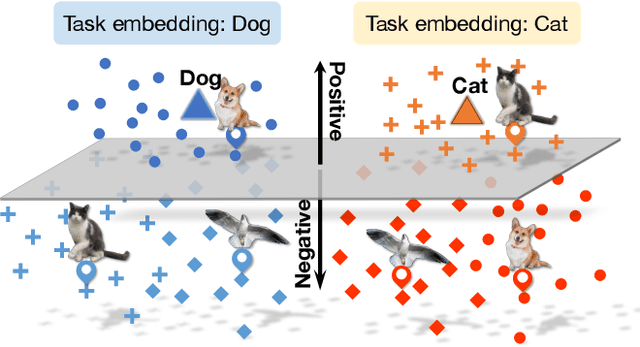
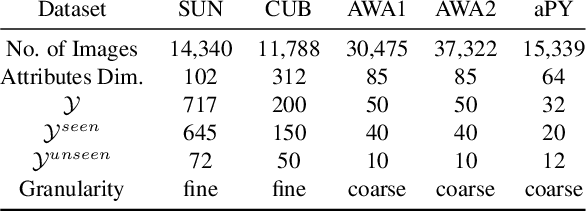
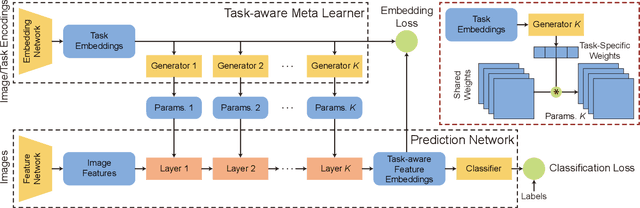

Learning good feature embeddings for images often requires substantial training data. As a consequence, in settings where training data is limited (e.g., few-shot and zero-shot learning), we are typically forced to use a generic feature embedding across various tasks. Ideally, we want to construct feature embeddings that are tuned for the given task. In this work, we propose Task-Aware Feature Embedding Networks (TAFE-Nets) to learn how to adapt the image representation to a new task in a meta learning fashion. Our network is composed of a meta learner and a prediction network. Based on a task input, the meta learner generates parameters for the feature layers in the prediction network so that the feature embedding can be accurately adjusted for that task. We show that TAFE-Net is highly effective in generalizing to new tasks or concepts and evaluate the TAFE-Net on a range of benchmarks in zero-shot and few-shot learning. Our model matches or exceeds the state-of-the-art on all tasks. In particular, our approach improves the prediction accuracy of unseen attribute-object pairs by 4 to 15 points on the challenging visual attribute-object composition task.
Disentangling Propagation and Generation for Video Prediction
Dec 02, 2018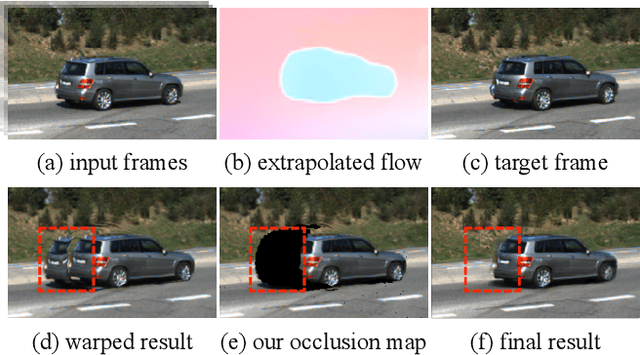
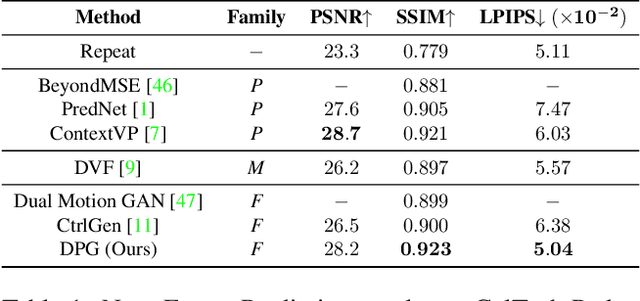
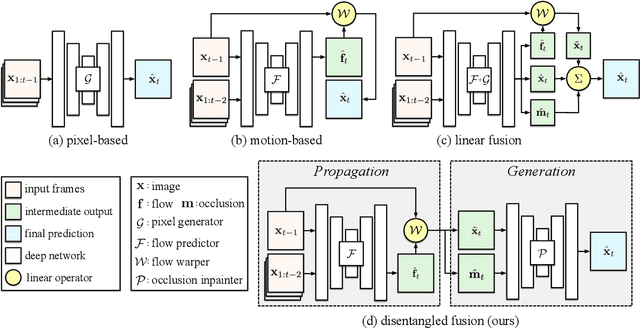
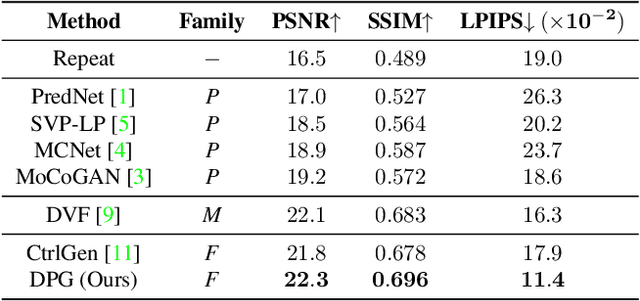
Learning to predict future video frames is a challenging task. Recent approaches for natural scenes directly predict pixels via inferring appearance flow and using flow-guided warping. Such models excel when motion estimates are accurate, but the motion may be ambiguous or erroneous in many real scenes. When scene motion exposes new regions of the scene, motion-based prediction yields poor results. However, learning to predict novel pixels directly can also require a prohibitive amount of training. In this work, we present a confidence-aware spatial-temporal context encoder for video prediction called Flow-Grounded Video Prediction (FGVP), in which motion propagation and novel pixel generation are first disentangled and then fused according to computed flow uncertainty map. For regions where motion-based prediction shows low-confidence, our model uses a conditional context encoder to hallucinate appropriate content. We test our methods on the standard CalTech Pedestrian dataset and the more challenging KITTI Flow dataset of larger motions and occlusions. Our methods produce both sharp and natural predictions compared to previous works, achieving the state-of-the-art performance on both datasets.
Deep Mixture of Experts via Shallow Embedding
Jun 05, 2018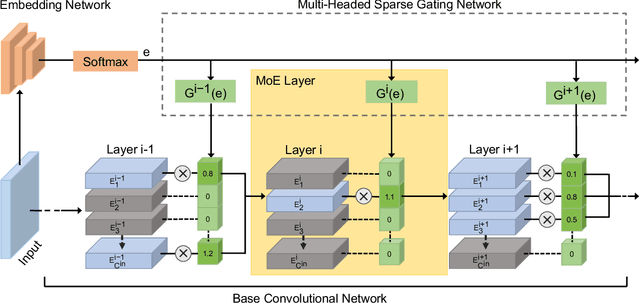

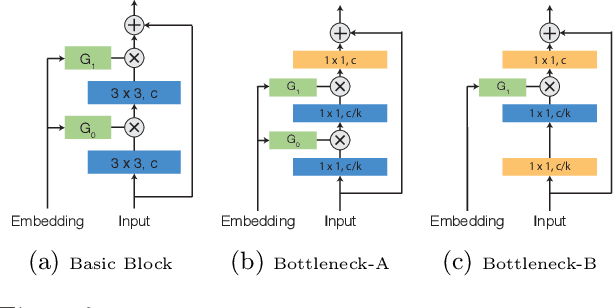
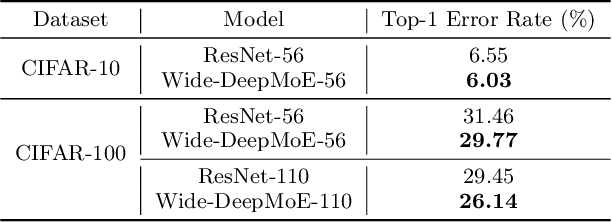
Larger networks generally have greater representational power at the cost of increased computational complexity. Sparsifying such networks has been an active area of research but has been generally limited to static regularization or dynamic approaches using reinforcement learning. We explore a mixture of experts (MoE) approach to deep dynamic routing, which activates certain experts in the network on a per-example basis. Our novel DeepMoE architecture increases the representational power of standard convolutional networks by adaptively sparsifying and recalibrating channel-wise features in each convolutional layer. We employ a multi-headed sparse gating network to determine the selection and scaling of channels for each input, leveraging exponential combinations of experts within a single convolutional network. Our proposed architecture is evaluated on several benchmark datasets and tasks and we show that DeepMoEs are able to achieve higher accuracy with lower computation than standard convolutional networks.