 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflection Separation from a Single Image via Joint Latent Diffusion
Jun 02, 2026Single-image reflection separation is highly challenging under extreme conditions like glare or weak reflections. Existing methods often struggle to recover both layers in glare or weak-reflection scenarios because of insufficient information. This paper presents a diffusion model explicitly fine-tuned for this task, leveraging generative diffusion priors for robust separation. Our method simultaneously generates transmission and reflection layers through a unified diffusion model, incorporating a novel cross-layer self-attention mechanism for better feature disentanglement. We further introduce a disjoint sampling strategy to iteratively reduce interference between the layers during diffusion and a latent optimization step with a learned composition function for improved results in complex real-world scenarios. Extensive experiments demonstrate that our approach surpasses state-of-the-art methods on multiple real-world benchmarks. Project page: https://brian90709.github.io/diff-reflection-separation/
Generative World Renderer
Apr 02, 2026Scaling generative inverse and forward rendering to real-world scenarios is bottlenecked by the limited realism and temporal coherence of existing synthetic datasets. To bridge this persistent domain gap, we introduce a large-scale, dynamic dataset curated from visually complex AAA games. Using a novel dual-screen stitched capture method, we extracted 4M continuous frames (720p/30 FPS) of synchronized RGB and five G-buffer channels across diverse scenes, visual effects, and environments, including adverse weather and motion-blur variants. This dataset uniquely advances bidirectional rendering: enabling robust in-the-wild geometry and material decomposition, and facilitating high-fidelity G-buffer-guided video generation. Furthermore, to evaluate the real-world performance of inverse rendering without ground truth, we propose a novel VLM-based assessment protocol measuring semantic, spatial, and temporal consistency. Experiments demonstrate that inverse renderers fine-tuned on our data achieve superior cross-dataset generalization and controllable generation, while our VLM evaluation strongly correlates with human judgment. Combined with our toolkit, our forward renderer enables users to edit styles of AAA games from G-buffers using text prompts.
BEVANet: Bilateral Efficient Visual Attention Network for Real-Time Semantic Segmentation
Aug 10, 2025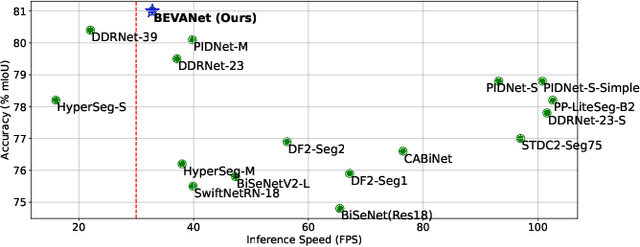



Real-time semantic segmentation presents the dual challenge of designing efficient architectures that capture large receptive fields for semantic understanding while also refining detailed contours. Vision transformers model long-range dependencies effectively but incur high computational cost. To address these challenges, we introduce the Large Kernel Attention (LKA) mechanism. Our proposed Bilateral Efficient Visual Attention Network (BEVANet) expands the receptive field to capture contextual information and extracts visual and structural features using Sparse Decomposed Large Separable Kernel Attentions (SDLSKA). The Comprehensive Kernel Selection (CKS) mechanism dynamically adapts the receptive field to further enhance performance. Furthermore, the Deep Large Kernel Pyramid Pooling Module (DLKPPM) enriches contextual features by synergistically combining dilated convolutions and large kernel attention. The bilateral architecture facilitates frequent branch communication, and the Boundary Guided Adaptive Fusion (BGAF) module enhances boundary delineation by integrating spatial and semantic features under boundary guidance. BEVANet achieves real-time segmentation at 33 FPS, yielding 79.3% mIoU without pretraining and 81.0% mIoU on Cityscapes after ImageNet pretraining, demonstrating state-of-the-art performance. The code and model is available at https://github.com/maomao0819/BEVANet.
* Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Matting by Generation
Jul 30, 2024


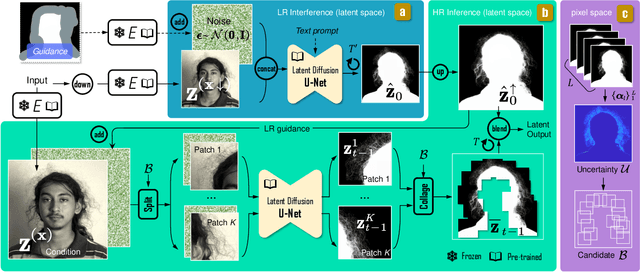
This paper introduces an innovative approach for image matting that redefines the traditional regression-based task as a generative modeling challenge. Our method harnesses the capabilities of latent diffusion models, enriched with extensive pre-trained knowledge, to regularize the matting process. We present novel architectural innovations that empower our model to produce mattes with superior resolution and detail. The proposed method is versatile and can perform both guidance-free and guidance-based image matting, accommodating a variety of additional cues. Our comprehensive evaluation across three benchmark datasets demonstrates the superior performance of our approach, both quantitatively and qualitatively. The results not only reflect our method's robust effectiveness but also highlight its ability to generate visually compelling mattes that approach photorealistic quality. The project page for this paper is available at https://lightchaserx.github.io/matting-by-generation/
Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
Apr 05, 2024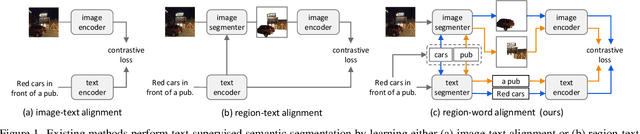
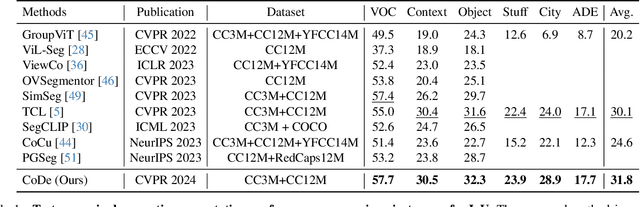
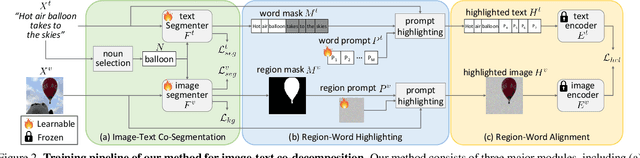
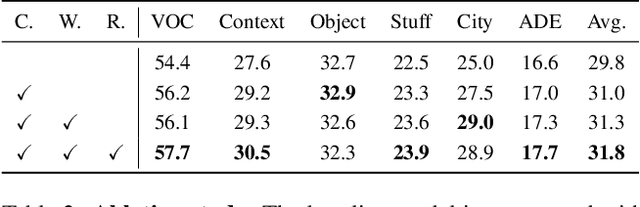
This paper addresses text-supervised semantic segmentation, aiming to learn a model capable of segmenting arbitrary visual concepts within images by using only image-text pairs without dense annotations. Existing methods have demonstrated that contrastive learning on image-text pairs effectively aligns visual segments with the meanings of texts. We notice that there is a discrepancy between text alignment and semantic segmentation: A text often consists of multiple semantic concepts, whereas semantic segmentation strives to create semantically homogeneous segments. To address this issue, we propose a novel framework, Image-Text Co-Decomposition (CoDe), where the paired image and text are jointly decomposed into a set of image regions and a set of word segments, respectively, and contrastive learning is developed to enforce region-word alignment. To work with a vision-language model, we present a prompt learning mechanism that derives an extra representation to highlight an image segment or a word segment of interest, with which more effective features can be extracted from that segment. Comprehensive experimental results demonstrate that our method performs favorably against existing text-supervised semantic segmentation methods on six benchmark datasets.
CTGAN: Semantic-guided Conditional Texture Generator for 3D Shapes
Feb 08, 2024The entertainment industry relies on 3D visual content to create immersive experiences, but traditional methods for creating textured 3D models can be time-consuming and subjective. Generative networks such as StyleGAN have advanced image synthesis, but generating 3D objects with high-fidelity textures is still not well explored, and existing methods have limitations. We propose the Semantic-guided Conditional Texture Generator (CTGAN), producing high-quality textures for 3D shapes that are consistent with the viewing angle while respecting shape semantics. CTGAN utilizes the disentangled nature of StyleGAN to finely manipulate the input latent codes, enabling explicit control over both the style and structure of the generated textures. A coarse-to-fine encoder architecture is introduced to enhance control over the structure of the resulting textures via input segmentation. Experimental results show that CTGAN outperforms existing methods on multiple quality metrics and achieves state-of-the-art performance on texture generation in both conditional and unconditional settings.
2D-3D Interlaced Transformer for Point Cloud Segmentation with Scene-Level Supervision
Oct 19, 2023We present a Multimodal Interlaced Transformer (MIT) that jointly considers 2D and 3D data for weakly supervised point cloud segmentation. Research studies have shown that 2D and 3D features are complementary for point cloud segmentation. However, existing methods require extra 2D annotations to achieve 2D-3D information fusion. Considering the high annotation cost of point clouds, effective 2D and 3D feature fusion based on weakly supervised learning is in great demand. To this end, we propose a transformer model with two encoders and one decoder for weakly supervised point cloud segmentation using only scene-level class tags. Specifically, the two encoders compute the self-attended features for 3D point clouds and 2D multi-view images, respectively. The decoder implements interlaced 2D-3D cross-attention and carries out implicit 2D and 3D feature fusion. We alternately switch the roles of queries and key-value pairs in the decoder layers. It turns out that the 2D and 3D features are iteratively enriched by each other. Experiments show that it performs favorably against existing weakly supervised point cloud segmentation methods by a large margin on the S3DIS and ScanNet benchmarks. The project page will be available at https://jimmy15923.github.io/mit_web/.
Robust Dynamic Radiance Fields
Jan 05, 2023



Dynamic radiance field reconstruction methods aim to model the time-varying structure and appearance of a dynamic scene. Existing methods, however, assume that accurate camera poses can be reliably estimated by Structure from Motion (SfM) algorithms. These methods, thus, are unreliable as SfM algorithms often fail or produce erroneous poses on challenging videos with highly dynamic objects, poorly textured surfaces, and rotating camera motion. We address this robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length). We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods.
Physically Plausible Animation of Human Upper Body from a Single Image
Dec 09, 2022



We present a new method for generating controllable, dynamically responsive, and photorealistic human animations. Given an image of a person, our system allows the user to generate Physically plausible Upper Body Animation (PUBA) using interaction in the image space, such as dragging their hand to various locations. We formulate a reinforcement learning problem to train a dynamic model that predicts the person's next 2D state (i.e., keypoints on the image) conditioned on a 3D action (i.e., joint torque), and a policy that outputs optimal actions to control the person to achieve desired goals. The dynamic model leverages the expressiveness of 3D simulation and the visual realism of 2D videos. PUBA generates 2D keypoint sequences that achieve task goals while being responsive to forceful perturbation. The sequences of keypoints are then translated by a pose-to-image generator to produce the final photorealistic video.
NeighborTrack: Improving Single Object Tracking by Bipartite Matching with Neighbor Tracklets
Nov 12, 2022We propose a post-processor, called NeighborTrack, that leverages neighbor information of the tracking target to validate and improve single-object tracking (SOT) results. It requires no additional data or retraining. Instead, it uses the confidence score predicted by the backbone SOT network to automatically derive neighbor information and then uses this information to improve the tracking results. When tracking an occluded target, its appearance features are untrustworthy. However, a general siamese network often cannot tell whether the tracked object is occluded by reading the confidence score alone, because it could be misled by neighbors with high confidence scores. Our proposed NeighborTrack takes advantage of unoccluded neighbors' information to reconfirm the tracking target and reduces false tracking when the target is occluded. It not only reduces the impact caused by occlusion, but also fixes tracking problems caused by object appearance changes. NeighborTrack is agnostic to SOT networks and post-processing methods. For the VOT challenge dataset commonly used in short-term object tracking, we improve three famous SOT networks, Ocean, TransT, and OSTrack, by an average of ${1.92\%}$ EAO and ${2.11\%}$ robustness. For the mid- and long-term tracking experiments based on OSTrack, we achieve state-of-the-art ${72.25\%}$ AUC on LaSOT and ${75.7\%}$ AO on GOT-10K.