 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Preserving Downsampling of Binary Images
Jul 25, 2024We present a novel discrete optimization-based approach to generate downsampled versions of binary images that are guaranteed to have the same topology as the original, measured by the zeroth and first Betti numbers of the black regions, while having good similarity to the original image as measured by IoU and Dice scores. To our best knowledge, all existing binary image downsampling methods do not have such topology-preserving guarantees. We also implemented a baseline morphological operation (dilation)-based approach that always generates topologically correct results. However, we found the similarity scores to be much worse. We demonstrate several applications of our approach. First, generating smaller versions of medical image segmentation masks for easier human inspection. Second, improving the efficiency of binary image operations, including persistent homology computation and shortest path computation, by substituting the original images with smaller ones. In particular, the latter is a novel application that is made feasible only by the full topology-preservation guarantee of our method.
H&E Stain Normalization using U-Net
Nov 10, 2022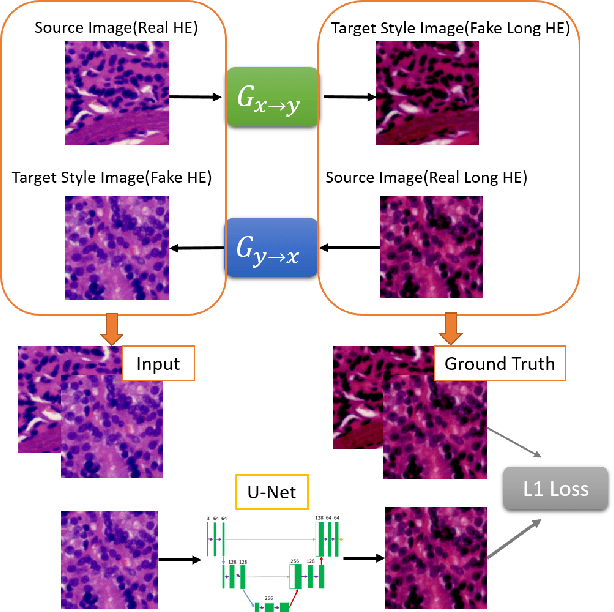


We propose a novel hematoxylin and eosin (H&E) stain normalization method based on a modified U-Net neural network architecture. Unlike previous deep-learning methods that were often based on generative adversarial networks (GANs), we take a teacher-student approach and use paired datasets generated by a trained CycleGAN to train a U-Net to perform the stain normalization task. Through experiments, we compared our method to two recent competing methods, CycleGAN and StainNet, a lightweight approach also based on the teacher-student model. We found that our method is faster and can process larger images with better quality compared to CycleGAN. We also compared to StainNet and found that our method delivered quantitatively and qualitatively better results.
High-Resolution Depth Estimation for 360-degree Panoramas through Perspective and Panoramic Depth Images Registration
Oct 20, 2022
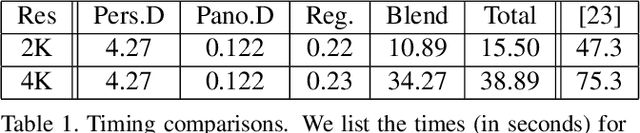
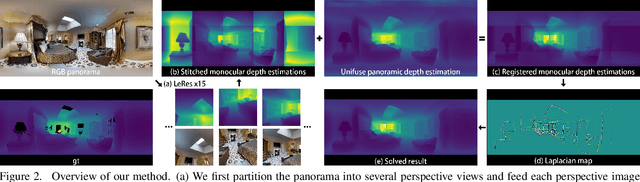
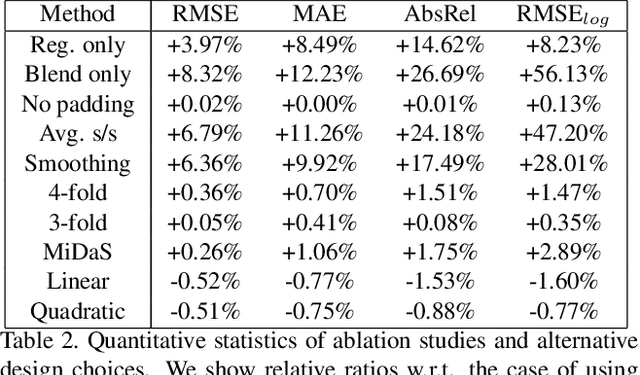
We propose a novel approach to compute high-resolution (2048x1024 and higher) depths for panoramas that is significantly faster and qualitatively and qualitatively more accurate than the current state-of-the-art method (360MonoDepth). As traditional neural network-based methods have limitations in the output image sizes (up to 1024x512) due to GPU memory constraints, both 360MonoDepth and our method rely on stitching multiple perspective disparity or depth images to come out a unified panoramic depth map. However, to achieve globally consistent stitching, 360MonoDepth relied on solving extensive disparity map alignment and Poisson-based blending problems, leading to high computation time. Instead, we propose to use an existing panoramic depth map (computed in real-time by any panorama-based method) as the common target for the individual perspective depth maps to register to. This key idea made producing globally consistent stitching results from a straightforward task. Our experiments show that our method generates qualitatively better results than existing panorama-based methods, and further outperforms them quantitatively on datasets unseen by these methods.
GPR-Net: Multi-view Layout Estimation via a Geometry-aware Panorama Registration Network
Oct 20, 2022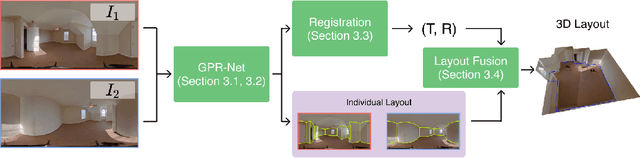

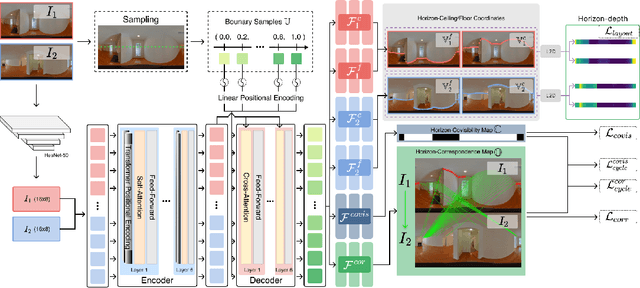

Reconstructing 3D layouts from multiple $360^{\circ}$ panoramas has received increasing attention recently as estimating a complete layout of a large-scale and complex room from a single panorama is very difficult. The state-of-the-art method, called PSMNet, introduces the first learning-based framework that jointly estimates the room layout and registration given a pair of panoramas. However, PSMNet relies on an approximate (i.e., "noisy") registration as input. Obtaining this input requires a solution for wide baseline registration which is a challenging problem. In this work, we present a complete multi-view panoramic layout estimation framework that jointly learns panorama registration and layout estimation given a pair of panoramas without relying on a pose prior. The major improvement over PSMNet comes from a novel Geometry-aware Panorama Registration Network or GPR-Net that effectively tackles the wide baseline registration problem by exploiting the layout geometry and computing fine-grained correspondences on the layout boundaries, instead of the global pixel-space. Our architecture consists of two parts. First, given two panoramas, we adopt a vision transformer to learn a set of 1D horizon features sampled on the panorama. These 1D horizon features encode the depths of individual layout boundary samples and the correspondence and covisibility maps between layout boundaries. We then exploit a non-linear registration module to convert these 1D horizon features into a set of corresponding 2D boundary points on the layout. Finally, we estimate the final relative camera pose via RANSAC and obtain the complete layout simply by taking the union of registered layouts. Experimental results indicate that our method achieves state-of-the-art performance in both panorama registration and layout estimation on a large-scale indoor panorama dataset ZInD.
3D Manhattan Room Layout Reconstruction from a Single 360 Image
Oct 24, 2019



Recent approaches for predicting layouts from 360 panoramas produce excellent results. These approaches build on a common framework consisting of three steps: a pre-processing step based on edge-based alignment, prediction of layout elements, and a post-processing step by fitting a 3D layout to the layout elements. Until now, it has been difficult to compare the methods due to multiple different design decisions, such as the encoding network (e.g. SegNet or ResNet), type of elements predicted (e.g. corners, wall/floor boundaries, or semantic segmentation), or method of fitting the 3D layout. To address this challenge, we summarize and describe the common framework, the variants, and the impact of the design decisions. For a complete evaluation, we also propose extended annotations for the Matterport3D dataset, and introduce two depth-based evaluation metrics.
DuLa-Net: A Dual-Projection Network for Estimating Room Layouts from a Single RGB Panorama
Nov 29, 2018

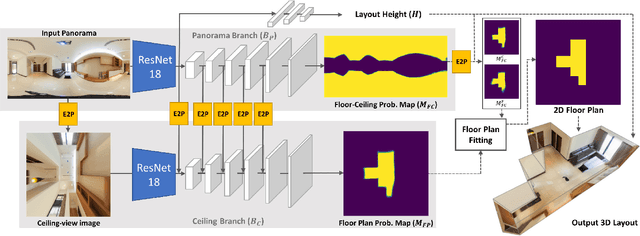

We present a deep learning framework, called DuLa-Net, to predict Manhattan-world 3D room layouts from a single RGB panorama. To achieve better prediction accuracy, our method leverages two projections of the panorama at once, namely the equirectangular panorama-view and the perspective ceiling-view, that each contains different clues about the room layouts. Our network architecture consists of two encoder-decoder branches for analyzing each of the two views. In addition, a novel feature fusion structure is proposed to connect the two branches, which are then jointly trained to predict the 2D floor plans and layout heights. To learn more complex room layouts, we introduce the Realtor360 dataset that contains panoramas of Manhattan-world room layouts with different numbers of corners. Experimental results show that our work outperforms recent state-of-the-art in prediction accuracy and performance, especially in the rooms with non-cuboid layouts.