 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchNet: A Simple Face Anti-Spoofing Framework via Fine-Grained Patch Recognition
Mar 27, 2022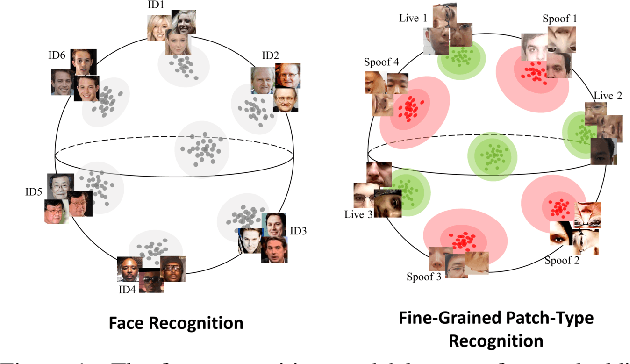
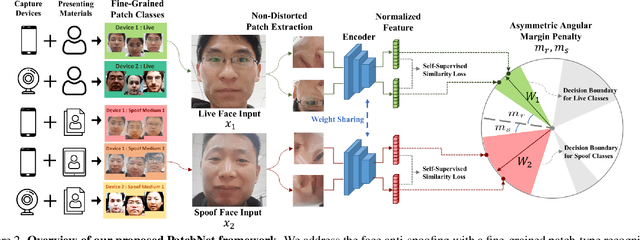
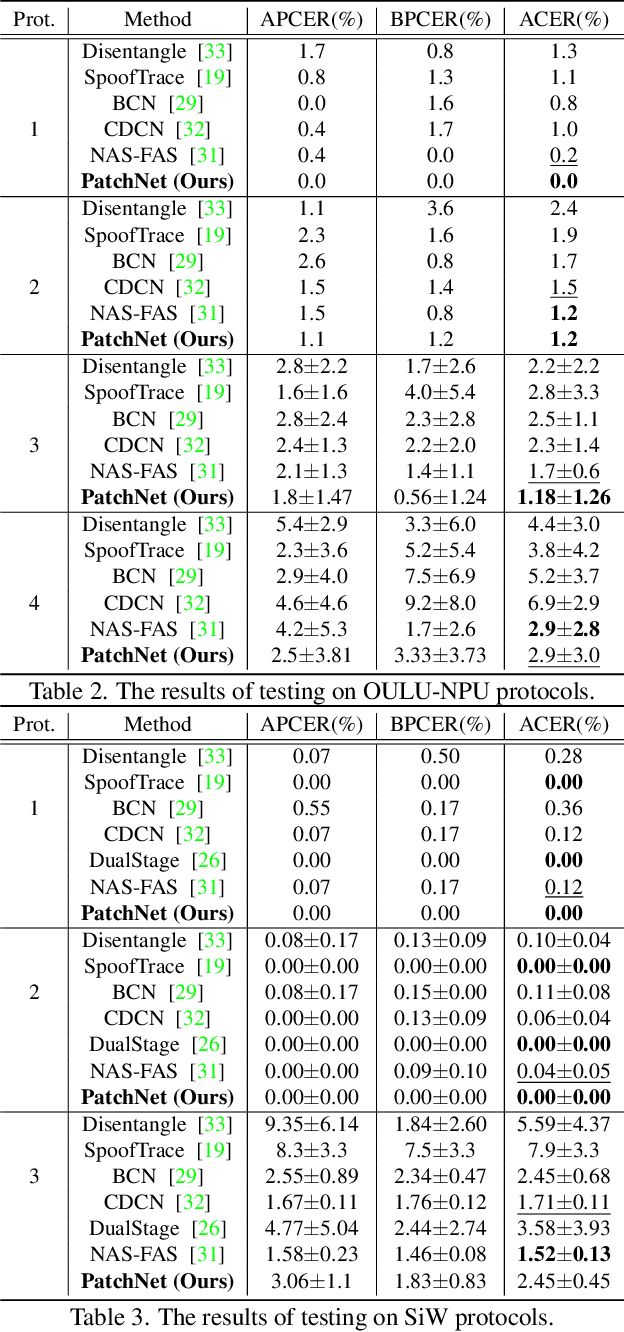
Face anti-spoofing (FAS) plays a critical role in securing face recognition systems from different presentation attacks. Previous works leverage auxiliary pixel-level supervision and domain generalization approaches to address unseen spoof types. However, the local characteristics of image captures, i.e., capturing devices and presenting materials, are ignored in existing works and we argue that such information is required for networks to discriminate between live and spoof images. In this work, we propose PatchNet which reformulates face anti-spoofing as a fine-grained patch-type recognition problem. To be specific, our framework recognizes the combination of capturing devices and presenting materials based on the patches cropped from non-distorted face images. This reformulation can largely improve the data variation and enforce the network to learn discriminative feature from local capture patterns. In addition, to further improve the generalization ability of the spoof feature, we propose the novel Asymmetric Margin-based Classification Loss and Self-supervised Similarity Loss to regularize the patch embedding space. Our experimental results verify our assumption and show that the model is capable of recognizing unseen spoof types robustly by only looking at local regions. Moreover, the fine-grained and patch-level reformulation of FAS outperforms the existing approaches on intra-dataset, cross-dataset, and domain generalization benchmarks. Furthermore, our PatchNet framework can enable practical applications like Few-Shot Reference-based FAS and facilitate future exploration of spoof-related intrinsic cues.
Unsupervised Discovery of Disentangled Manifolds in GANs
Nov 29, 2020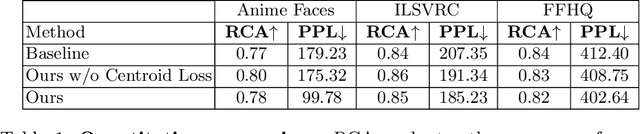
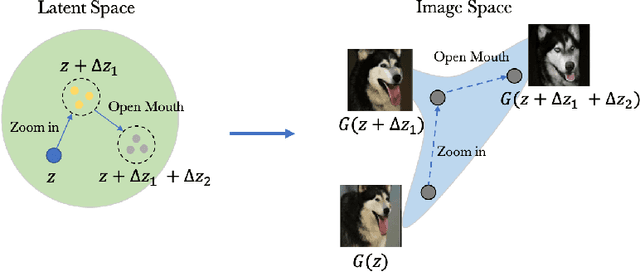
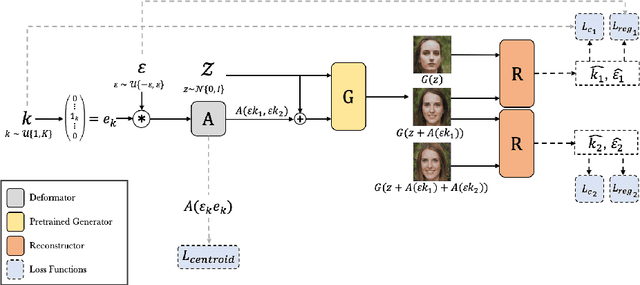

As recent generative models can generate photo-realistic images, people seek to understand the mechanism behind the generation process. Interpretable generation process is beneficial to various image editing applications. In this work, we propose a framework to discover interpretable directions in the latent space given arbitrary pre-trained generative adversarial networks. We propose to learn the transformation from prior one-hot vectors representing different attributes to the latent space used by pre-trained models. Furthermore, we apply a centroid loss function to improve consistency and smoothness while traversing through different directions. We demonstrate the efficacy of the proposed framework on a wide range of datasets. The discovered direction vectors are shown to be visually corresponding to various distinct attributes and thus enable attribute editing.
Dancing to Music
Nov 05, 2019
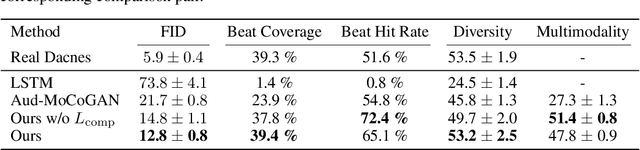
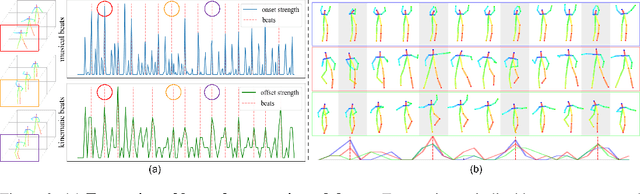
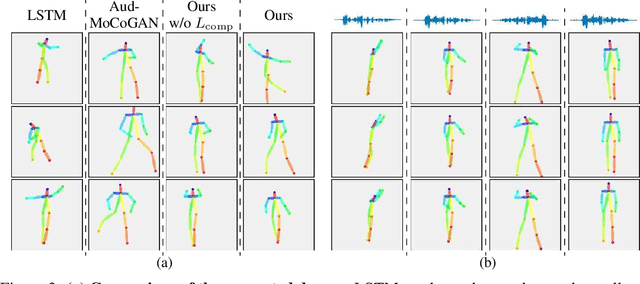
Dancing to music is an instinctive move by humans. Learning to model the music-to-dance generation process is, however, a challenging problem. It requires significant efforts to measure the correlation between music and dance as one needs to simultaneously consider multiple aspects, such as style and beat of both music and dance. Additionally, dance is inherently multimodal and various following movements of a pose at any moment are equally likely. In this paper, we propose a synthesis-by-analysis learning framework to generate dance from music. In the analysis phase, we decompose a dance into a series of basic dance units, through which the model learns how to move. In the synthesis phase, the model learns how to compose a dance by organizing multiple basic dancing movements seamlessly according to the input music. Experimental qualitative and quantitative results demonstrate that the proposed method can synthesize realistic, diverse,style-consistent, and beat-matching dances from music.
Self-supervised Audio Spatialization with Correspondence Classifier
May 14, 2019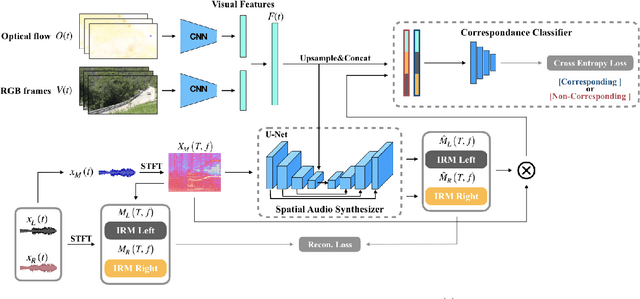


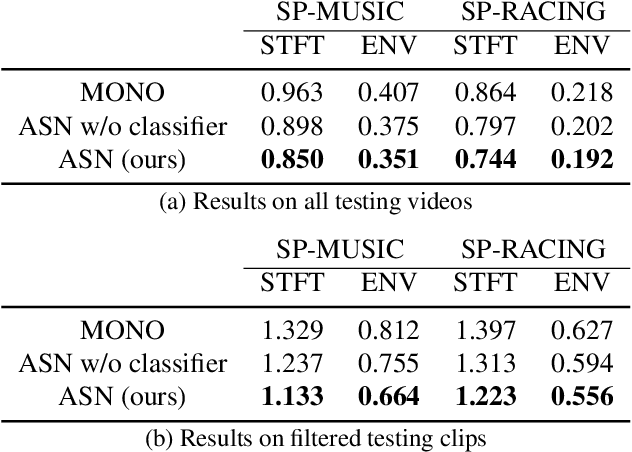
Spatial audio is an essential medium to audiences for 3D visual and auditory experience. However, the recording devices and techniques are expensive or inaccessible to the general public. In this work, we propose a self-supervised audio spatialization network that can generate spatial audio given the corresponding video and monaural audio. To enhance spatialization performance, we use an auxiliary classifier to classify ground-truth videos and those with audio where the left and right channels are swapped. We collect a large-scale video dataset with spatial audio to validate the proposed method. Experimental results demonstrate the effectiveness of the proposed model on the audio spatialization task.
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
May 02, 2019
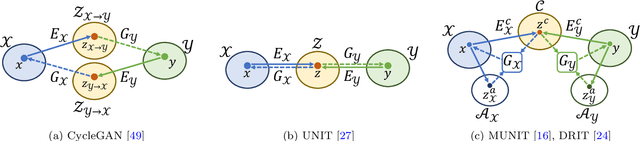
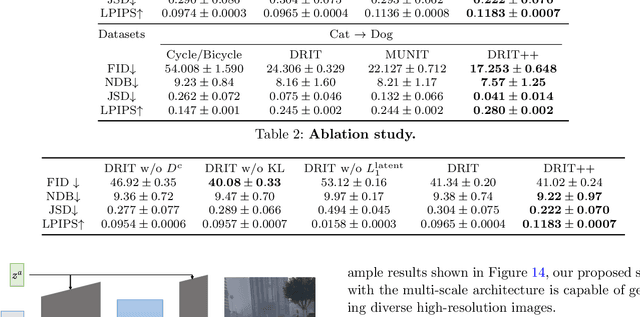
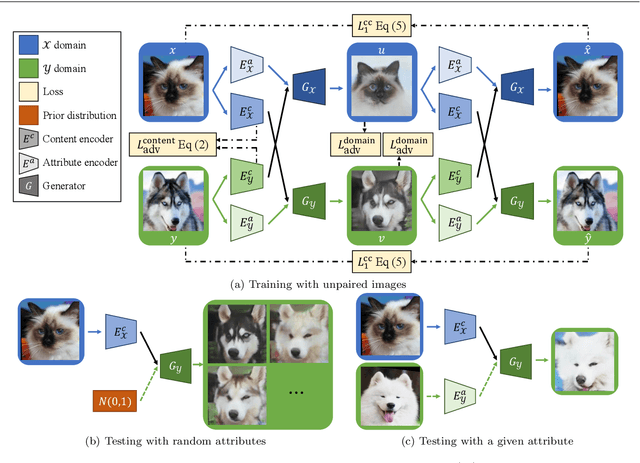
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: 1) lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fr\'{e}chet inception distance, and measure diversity with the perceptual distance metric, Jensen-Shannon divergence, and number of statistically-different bins.